CPU相关术语
平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
CPU 上下文切换
CPU上下文(context switch)切换就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
所以,根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
系统调用
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
进程上下文切换
进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
什么时候会切换进程上下文。
- 其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
线程的上下文切换其实就可以分为两种情况:
- 第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
特点:
- 中断上下文切换并不涉及到进程的用户态
- 对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。
- 中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。
- 中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
中断处理过程
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
简单来说
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。ksoftirqd/0 就是软中断的内核线程
中断的记录
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
CPU使用率
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比
进程状态
top 和 ps 是最常用的查看进程状态的工具
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。进程长时间处于不可中断状态,通常表示系统有I/O 性能问题。
- Z 是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
- T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
- X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员; 会话是指共享同一个控制终端的一个或多个进程组。
CPU性能指标
cpu的性能指标可分为以下几种:
CPU性能指标
├── CPU使用率
│ ├── 用户CPU
│ ├── 系统CPU
│ ├── IOWAIT
│ ├── 软中断
│ ├── 硬中断
│ ├── 窃取CPU
│ └── 客户CPU
├── 上下文切换
│ ├── 自愿上下文切换
│ └── 非自愿上下文切换
├── 平均负载
└── CPU缓存命中率
CPU 使用率
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的CPU 时间百分比。
平均负载(Load Average)
平均负载也就是系统的平均活跃进程数。
它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。 理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
进程上下文切换
进程上下文切换包括
- 无法获取资源而导致的自愿上下文切换;
- 被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
CPU 缓存命中率
由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
+------------------------------+
| Memory |
+------------------------------+
+------------------------------+
| +--------------------------+ |
| | L3 Cache | |
| +--------------------------+ |
| +----------+ +----------+ |
| | L2 Cache | | L2 Cache | |
| +----------+ +----------+ |
| | L1 Cache | | L1 Cache | |
| +----------+ +----------+ |
| | Core 0 | | Core 0 | |
| +----------+ +----------+ |
| |
| CPU (Node) |
+------------------------------+
就像上面这张图显示的,CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
性能工具
从故障案例的角度来看使用的性能工具。
平均负载升高
- 先用
uptime, 查看了系统的平均负载 - 再用
mpstat和pidstat,分别观察了每个 CPU 和每个进程 CPU 的使用情况
上下文切换异常
- 先用
vmstat,查看了系统的上下文切换次数和中断次数; - 然后通过
pidstat,观察了进程的自愿上下文切换和非自愿上下文切换情况; - 最后通过
pidstat,观察了线程的上下文切换情况
进程CPU使用率升高
- 先用
top,查看了系统和进程的 CPU 使用情况 - 发现 CPU 使用率升高的进程;
- 再用
perf top,观察进程的调用链
系统CPU使用率升高
- 先用
top观察到了系统 CPU 升高,但通过top和pidstat,却找不出高 CPU 使用率的进程。 - 于是,我们重新审视
top的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处。 - 最终通过
perf record和perf report查看进程调用链
不可中断进程和僵尸进程
- 先用
top观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程; - 接着我们用
dstat发现是这是由磁盘读导致的,于是又通过pidstat找出了相关的进程。 - 但我们用
strace查看进程系统调用却失败了,最终还是用perf分析进程调用链,才发现根源在于磁盘直接 I/O 。
软中断
- 先用
top观察到,系统的软中断 CPU 使用率升高; - 接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;
- 然后通过
sar命令,发现是网络小包的问题,最后再用tcpdump,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
再从cpu的性能指标出发,也就是说当你想查看某项指标的时候,改用哪些工具
| 性能指标 | 工具 | 说明 |
|---|---|---|
| 平均负载 | uptime top |
uptime最简单,top提供了更全的指标 |
| 系统整体CPU使用率 | vmstatmpstattopsar/proc/stat |
top、vmstat、 mpstat 只可以动态查看,而sar还可以记录历史数据/proc/stat是其他性能工具的数据来源 |
| 进程CPU使用率 | top pidstat ps htop atop |
top和ps可以按CPU使用率给进程排序,而pidst at只显示实际用了CPU的进程 htop和atop以不同颜色显示更直观 |
| 系统上下文切换 | vmstat | 除了上下文切换次数,还提供运行状态和不可中断状态进程的数量 |
| 进程上下文切换 | pidstat | 注意加上-w选项 |
| 软中断 | top /proc/softirqs mpstat |
top提供软中断CPU使用率,而/proc/softirqs和mpstat提供了各种软中断在每个CPU上的运行次数 |
| 硬中断 | vmstat /proc/interrupts |
vmstat提供总的中断次数,而/proc/int errupts提供各种中断在每个CPU上运行的累积次数 |
| 网络 | dstat sar tcpdump |
dst at和sar提供总的网络接收和发送情况,而t cpdump则是动态抓取正在进行的网络通讯 |
| I/O | dstat sar |
dst at和sar都提供了I/O的整体情况 |
| CPU个数 | /proc/cpuinfo lscpu |
Iscpu更直观 |
| 事件剖析 | perf execsnoop |
perf可以用来分析CPU的缓存以及内核调用链,execsnoop用 来监控短时进程 |
从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
| 性能工具 | CPU性能指标 |
|---|---|
| uptime | 平均负载 |
| top | 平均负载、运行队列、整体的CPU使用率以及每个进程的状态和CPU使用率 |
| htop | top增强版,以不同颜色区分不同类型的进程,更直观 |
| atop | CPU、内存、磁盘和网络等各种资源的全面监控 |
| vmstat | 系统整体的CPU使用率、上下文切换次数、中断次数,还包括处于运行和不可中断状态的进程数量 |
| mpstat | 每个CPU的使用率和软中断次数 |
| pidstat | 进程和线程的CPU使用率、中断上下文切换次数 |
| /proc/softirqs | 软中断类型和在每个CPU上的累积中断次数 |
| /proc/interrupts | 硬中断类型和在每个CPU上的累积中断次数 |
| ps | 每个进程的状态和CPU使用率 |
| pstree | 进程的父子关系 |
| dstat | 系统整体的CPU使用率 |
| sar | 系统整体的CPU使用率,包括可配置的历史数据 |
| strace | 进程的系统调用 |
| perf | CPU性能事件剖析,如调用链分析、CPU缓存、CPU调度等 |
| execsnoop | 监控短时进程 |
如何迅速分析 CPU 的性能瓶颈
就是熟练掌握CPU指标之间的关联性。
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
有了这样的基本认识之后,我们就可以缩小排查范围,缩小范围之后会先运行几个支持指标较多的工具,如 top、vmstat和 pidstat, 请看下图中的联系
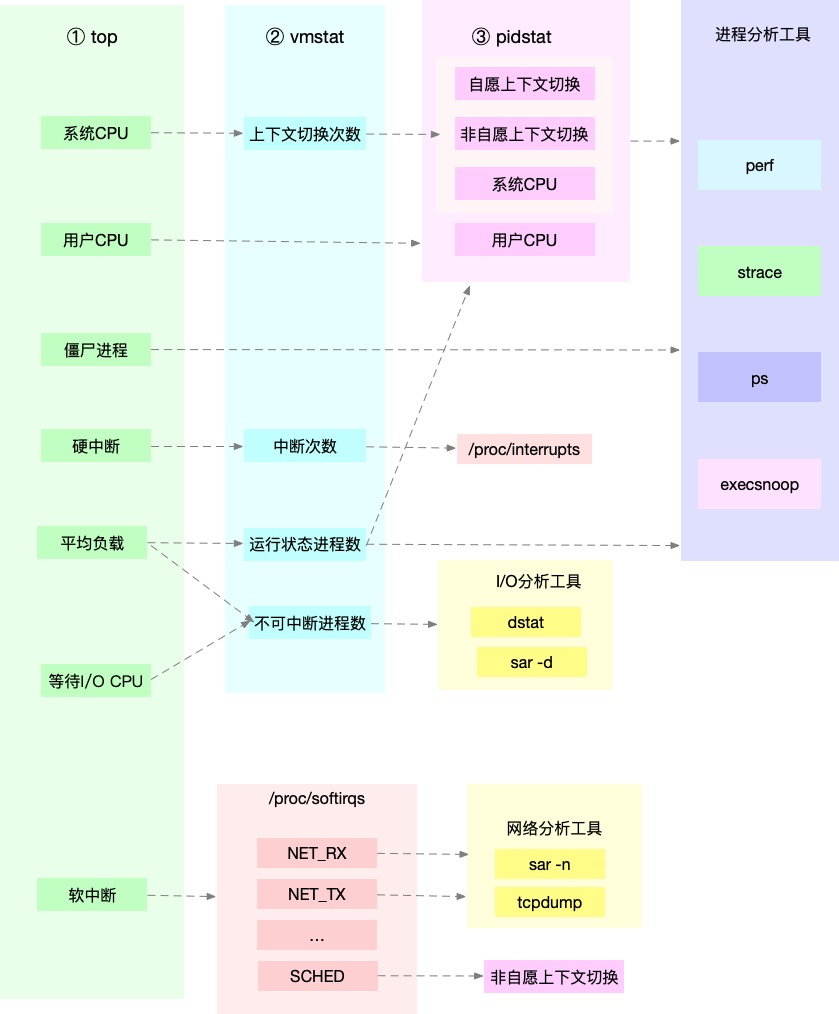
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进 程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下 文切换和非自愿上下文切换情况。
- 在遇到进程问题时,使用 strace分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
- 在遇到IO问题时,使用dstat 或 sar 等工具,进一步分析 I/O 的情况。
- 在遇到网络接收中断导致的问题,使用网络分析工具 sar 和 tcpdump 来分析。
CPU性能优化
性能优化方法论
- 首先,既然要做性能优化,那要怎么判断它是不是有效呢?特别是优化后,到底能提升 多少性能呢?
- 第二,性能问题通常不是独立的,如果有多个性能问题同时发生,你应该先优化哪一个 呢?
- 第三,提升性能的方法并不是唯一的,当有多种方法可以选择时,你会选用哪一种呢? 是不是总选那个最大程度提升性能的方法就行了呢?
在优化性能前先回答上面三个问题。
怎么评估性能优化的效果?
- 确定性能的量化指标。
- 测试优化前的性能指标。
- 测试优化后的性能指标。
量化指标最好有多种维度的数据,比如,以 Web 应用为例:
- 应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能。
- 系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况。
之所以从这两个不同维度选择指标,主要是因为应用程序和系统资源这两者间相辅相成的关系。
在进行性能测试时,有两个特别重要的地方你需要注意下
- 第一,要避免性能测试工具干扰应用程序的性能。通常,对 Web 应用来说,性能测试工 具跟目标应用程序要在不同的机器上运行。
- 第二,避免外部环境的变化影响性能指标的评估。这要求优化前、后的应用程序,都运行 在相同配置的机器上,并且它们的外部依赖也要完全一致。
多个性能问题同时存在,要怎么选择?
在性能测试的领域,流传很广的一个说法是“二八原则”,也就是说 80% 的问题都是由20% 的代码导致的。只要找出这 20% 的位置,你就可以优化 80% 的性能。所以,我想表达的是,并不是所有的性能问题都值得优化。
先优化问题比较突出的那个。
- 第一,如果发现是系统资源达到了瓶颈,比如 CPU 使用率达到了 100%,那么首先优化的一定是系统资源使用问题。完成系统资源瓶颈的优化后,我们才要考虑其他问题。
- 第二,针对不同类型的指标,首先去优化那些由瓶颈导致的,性能指标变化幅度最大的问题。比如产生瓶颈后,用户 CPU 使用率升高了 10%,而系统 CPU 使用率却升高了50%,这个时候就应该首先优化系统 CPU 的使用。
有多种优化方法时,要如何选择?
一般情况下,我们当然想选能最大提升性能的方法,这其实也是性能优化的目标。
但是性能优化并非没有成本。性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。也就是说,很可能你优化了一个指标,另一个指标的性能却变差了。
CPU优化
清楚了性能优化最基本的三个问题后,我们接下来从应用程序和系统的角度,分别来看看如何才能降低 CPU 使用率,提高 CPU 的并行处理能力。
应用程序优化
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
-
CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨CPU 调度带来的上下文切换问题。
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些CPU。
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
最后提醒大家,千万不要过早优化。因为,一方面,优化会带来复杂性的提升,降低可维护性;另一方面,需求不是一成不变的。针对当前情况进行的优化,很可能并不适应快速变化的新需求。这样,在新需求出现时,这些复杂的优化,反而可能阻碍新功能的开发。
性能工具的使用
uptime
显示系统已经运行了多长时间,当前登陆用户和系统负载情况
~# uptime
16:10:08 up 49 min, 2 users, load average: 0.07, 0.07, 0.05
top
动态地持续监听进程地运行状态
TOP 前五行的统计信息
top - 当前时间 up 系统运行时间, 当前登录用户数 users, load average: 系统负载
Tasks: 进程总数 total, 运行的进程数 running, 睡眠进程数 sleeping, 停止进程数 stopped, 僵尸进程数 zombie
%Cpu(s): 用户空间占CPU百分比 us, 内核空间占CPU百分比 sy, 用户进程空间内改变过优先级的进程占用CPU百分比 ni, 空闲CPU百分比 id, 等待输入输出的CPU时间百分比 wa, 硬件中断占CPU时间百分比 hi, 软件终端占CPU时间百分比 si, 提供给虚拟化环境执行占CPU时间百分比 st
KiB Mem: 物理内存总量 total, 使用内存 used, 空闲内存 free, 内核缓存的内存量 buffers
KiB Swap: 交换区总容量 total, 使用内存 used, 空闲内存 free. 缓冲交换区总量 cached Mem
进程信息
| 列名 | 含义 |
|---|---|
| PID | 进程ID |
| PPID | 父进程ID |
| RUSER | real user name |
| UID | 进程所有者用户ID |
| USER | 进程所有者用户名 |
| GROUP | 进程所有者组名 |
| TTY | 启动进程的终端名 |
| PR | 优先级 |
| NI | nice值,负数表示高优先级,正数表示低优先级 |
| P | 最后使用的CPU,仅用于多 CPU 环境 |
| %CPU | 上次更新到现在的 CPU 时间占用百分比 |
| TIME | 进程使用的CPU时间总计(以秒为单位) |
| TIME+ | 进程使用的CPU时间总计(以1/100秒为单位) |
| %MEM | 进程使用物理内存百分比 |
| VIRT | 进程使用虚拟内存总量(以KB为单位) VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小 |
| RES | 进程使用的未被换出的物理内存大小(以KB为单位) RES=CODE+DATA |
| CODE | 可执行代码占用物理内存总大小 |
| DATA | 数据段+栈占用的物理内存总大小 |
| SHR | 共享内存总大小 |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数 |
| S | 进程状态 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志,参考 sched.h |
top交互命令
| 命令 | 意义 | 默认值 |
|---|---|---|
| A | 分屏显示 | off(全屏显示) |
| d | 刷新间隔 | 3秒 |
| H | 线程模式 | off |
| I | Irix/Solaris模式切换 | solaris 模式 |
| p | 监控某个PID | no(监控所有PID) |
| s | 保护模式 | off |
| B | 是否支持粗体 | on |
| l | 显示任务队列信息 | on |
| t | 显示任务/cpu状态 | on |
| m | 显示内存/交换区状态 | on |
| 1 | 显示全部CPU核心状态 | off |
| b | 用背景突出显示 | off |
| c | 显示详细命令 | off |
| i | 显示僵尸进程 | on |
| J | 数字右对齐 | on |
| j | 列右对齐 | off |
| R | 按照 pid 从大到小排序 | on |
| S | 显示进程占用CPU的总时间 | off |
| u | 只显示某个用户ID | off |
| U | 显示全部用户ID | off |
| x | 突出显示用于排序的列 | off |
| y | 突出显示正在运行的任务 | on |
| z | 是否配色 | off |
| h/? | 显示help | |
| Z | 配置颜色 | |
| E/e | 切换内存数值单位(K、M、G) | off |
| f/F | 显示或隐藏某些信息 | |
| X | 设置列宽 | 0 |
| L/& | 查找 | |
| </> | 翻页 | |
| V | 显示进程树 | off |
| k | kill | |
| r | 重新指定进程优先级 | |
| W | 写入配置文件 | |
| q/ |
退出 |
进程的状态码
| D | 不可中断 Uninterruptible sleep (usually IO) |
|---|---|
| R | 正在运行,或在队列中的进程 |
| S | 处于休眠状态 |
| T | 停止或被追踪 |
| Z | 僵尸进程 |
| W | 进入内存交换(从内核2.6开始无效) |
| X | 死掉的进程 |
额外的状态标识
| < | 高优先级 |
|---|---|
| N | 低优先级 |
| L | 有些页被锁进内存 |
| s | 包含子进程 |
| + | 位于后台的进程组 |
| l | 多线程,克隆线程 multi-threaded |
常用命令
~# top # 进入交互界面
~# top -d 1 # 设置top的显示间隔,默认3秒
~# top -n 3 # 刷新3次后退出
pidstat
pidstat 概述 pidstat是sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况.
常用命令
~# yum install sysstat # 安装
~# pidstat # 查看所有进程的 CPU 使用情况
~# pidstat -u 5 1 # cpu使用情况统计,间隔 5 秒后输出一组数据
PID:进程ID
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
~# pidstat -r # 内存使用情况统计
PID:进程标识符
Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
VSZ:虚拟地址大小,虚拟内存的使用KB
RSS:常驻集合大小,非交换区五里内存使用KB
Command:task命令名
~# pidstat -d # 显示各个进程的IO使用情况
PID:进程id
kB_rd/s:每秒从磁盘读取的KB
kB_wr/s:每秒写入磁盘KB
kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
COMMAND:task的命令名
~# pidstat -w -p 2831 # 显示指定进程的上下文切换情况
PID:进程id
Cswch/s:每秒主动任务上下文切换数量
Nvcswch/s:每秒被动任务上下文切换数量
Command:命令名
~# pidstat -t -p 2831 # 显示选择任务的线程的统计信息外的额外信息
TGID:主线程的表示
TID:线程id
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
vmstat
是 Virtual Meomory Statistics(虚拟内存统计)的缩写,可用来监控 CPU 使用、进程状态、内存使用、虚拟内存使用、硬盘输入/输出状态等信息。
常用命令
vmstat 3 3 # 3秒钟刷新一次,总共输出3次
vmstat -a 3 3 # 显示活跃和非活跃内存
字段说明
procs
- r 正在等待运行的进程数
- b 在uninterruptible 睡眠中的进程数
memory
- swpd 以使用的swap空间
- free 剩余的物理内存
- buff buffer
- cache cache
- inact 非活动的内数量(-a选项)
- active 活动的内存的数量(-a选项)
swap
- si 从磁盘交换的内存大小
- so 交换到磁盘的内存大小
io
- bi 从块设备接收的块(block/s)
- bo 发送给块设备的块(block/s).如果这个值长期不为0,说明内存可能有问题,因为没有使用到缓存(当然,不排除直接I/O的情况,但是一般很少有直接I/O的)
system
- in 每秒的中断次数,包括时钟中断
- cs 进程上下文切换次数
cpu
- us 用户进程占用CPU时间比例
- sy 系统占用CPU时间比例
- id CPU空闲时间比
- wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了)
- st steal time
mpstat
mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。
常用命令
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
$ mpstat -P ALL 5
字段含义
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
%nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%sys 在internal时间段里,内核时间(%) (system/total)*100
%iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%irq 在internal时间段里,硬中断时间(%) (irq/total)*100
%soft 在internal时间段里,软中断时间(%) (softirq/total)*100
%steal 在internal时间段里,显示虚拟机管理程序为另一个虚拟处理器提供服务时虚拟CPU或CPU在非自愿等待中花费的时间百分比
%guest 在internal时间段里,CPU运行虚拟器的占比
%gnice 在internal时间段里,CPU运行niced guest虚拟机所花费的时间百分比
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
dstat
dstat命令是一个用来替换vmstat、iostat、netstat、nfsstat和ifstat这些命令的工具,是一个全能系统信息统计工具
常用命令
$ yum -y instatll dstat # 安装
$ dstat 1 10 # 间隔 1 秒输出 10 组数据
$ dstat --top-mem --top-io --top-cpu
$ dstat -cmsdnl -D sda1 -N lo,ens33 100 5
字段说明
--total-cpu-usage---- CPU使用率
usr:用户空间的程序所占百分比;
sys:系统空间程序所占百分比;
idel:空闲百分比;
wai:等待磁盘I/O所消耗的百分比;
hiq:硬中断次数;
siq:软中断次数;
-dsk/total-磁盘统计
read:读总数
writ:写总数
-net/total- 网络统计
recv:网络收包总数
send:网络发包总数
---paging-- 内存分页统计
in: pagein(换入)
out:page out(换出)
注:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,通常情况下当系统已经开始用交换空间的时候,就说明你的内存已经不够用了,或者说内存非常分散,理想情况下page in(换入)和page out(换出)的值是0 0。
--system--系统信息
int:中断次数
csw:上下文切换
ps
查看系统中所有运行进程的详细信息
ps aux # 可以查看系统中所有的进程
ps -ef # 可以查看进程的父进程
ps -le # 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级
ps -l # 只能看到当前 Shell 产生的进程
pstree
查看进程树
# -a 表示输出命令行选项
# p 表 PID
# s 表示指定进程的父进程
$ pstree -aps 3084
strace
strace常用来跟踪进程执行时的系统调用和所接收的信号。
参数
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出,以秒了表示时间.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column
设置返回值的输出位置.默认 为40.
-e expr
指定一个表达式,用来控制如何跟踪.格式如下:
[qualifier=][!]value1[,value2]...
qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:
-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none.
注意有些shell使用!来执行历史记录里的命令,所以要使用\\.
-e trace=set
只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file
只跟踪有关文件操作的系统调用.
-e trace=process
只跟踪有关进程控制的系统调用.
-e trace=network
跟踪与网络有关的所有系统调用.
-e strace=signal
跟踪所有与系统信号有关的 系统调用
-e trace=ipc
跟踪所有与进程通讯有关的系统调用
-e abbrev=set
设定 strace输出的系统调用的结果集.-v 等与 abbrev=none.默认为abbrev=all.
-e raw=set
将指 定的系统调用的参数以十六进制显示.
-e signal=set
指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set
输出从指定文件中读出 的数据.例如:
-e read=3,5
-e write=set
输出写入到指定文件中的数据.
-o filename
将strace的输出写入文件filename
-p pid
跟踪指定的进程pid.
-s strsize
指定输出的字符串的最大长度.默认为32.文件名一直全部输出.
-u username
以username 的UID和GID执行被跟踪的命令
常用命令
strace -p process_id # 跟踪进程
strace -c ping # 跟踪命令执行
strace -e open ping # 指定跟踪open事件
strace -e trace=network nc 127.0.0.1 22 # 指定跟踪trace事件中的network调用
strace -f -F -ff -s 1024 -o strace.txt -p 1234 # 指定跟踪子进程,设置输出长度大小
strace -T -tt -e trace=all -o output.txt -p 28979 # 跟踪调用的时间
perf
perf是Linux下的一款性能分析工具,能够进行函数级与指令级的热点查找。
常用命令
yum -y install perf # 安装
perf top # 实时显示占用 CPU 时钟最多的函数或者指令
perf stat -r 1 -d sleep 5 # 获取命令的执行统计
perf record -g # 采样
perf report # 出报告
字段说明
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
sar
sar是System Activity Reporter(系统活动情况报告)的缩写。sar工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。
常用命令
sar 5 5 // CPU和IOWAIT统计状态
sar -b 5 5 // IO传送速率
sar -B 5 5 // 页交换速率
sar -c 5 5 // 进程创建的速率
sar -d 5 5 // 块设备的活跃信息
sar -n DEV 5 5 // 网路设备的状态信息
sar -n SOCK 5 5 // SOCK的使用情况
sar -n ALL 5 5 // 所有的网络状态信息
sar -P ALL 5 5 // 每颗CPU的使用状态信息和IOWAIT统计状态
sar -q 5 5 // 队列的长度(等待运行的进程数)和负载的状态
sar -r 5 5 // 内存和swap空间使用情况
sar -R 5 5 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
sar -u 5 5 // CPU的使用情况和IOWAIT信息(同默认监控)
sar -v 5 5 // inode, file and other kernel tablesd的状态信息
sar -w 5 5 // 每秒上下文交换的数目
sar -W 5 5 // SWAP交换的统计信息(监控状态同iostat 的si so)
sar -x 2906 5 5 // 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上
sar -y 5 5 // TTY设备的活动状态
tcpdump
TCPDump可以将网络中传送的数据包完全截获下来提供分析。
常用命令
# 输出格式
# 时间戳 协议 源地址. 源端口 > 目的地址. 目的端口 网络包详细信息
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
tcpdump -i eth0 -n tcp port 80
# 源地址是 10.5.2.3,目的端口是 3389 的数据包
tcpdump -nnvS src 10.5.2.3 and dst port 3389
# 从 192.168 网段到 10 或者 172.16 网段的数据包
tcpdump -nvX src net 192.168.0.0/16 and dat net 10.0.0.0/8 or 172.16.0.0/16
# 监听eth0网卡HTTP 80端口的request和response
tcpdump -i eth0 -A -s 0 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
# 监听eth0网卡HTTP 80端口的request(不包括response),指定来源域名"example.com",也可以指定IP"192.168.1.107"
tcpdump -i eth0 -A -s 0 'src example.com and tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
# 监听本机发送至本机的HTTP 80端口的request和response
tcpdump -i lo -A -s 0 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
# 监听eth0网卡HTTP 80端口的request和response,结果另存为cap文件
tcpdump -i eth0 -A -s 0 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)' -w ./dump.cap
参考 极客时间专栏《Linux 性能优化实战》