网络相关术语
开放式系统互联通信参考模型
开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI 网络模型。
OSI 模型把网络互联的框架分为应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层等七层,每个层负责不同的功能。其中,
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
TCP/IP 网络模型
OSI 模型还是太复杂了,也没能提供一个可实现的方法。所以,在 Linux 中,我们实际上使用的是另一个更实用的四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中,
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
TCP/IP 与 OSI 模型的关系
| OSI 网络模型 | TCP/IP 网络模型 |
|---|---|
| 应用层 | 应用层 |
| 表示层 | |
| 会话层 | |
| 传输层 | 传输层 |
| 网络层 | 网络层 |
| 数据链路层 | 网络接口层 |
| 物理 |
linux 网络栈
有了 TCP/IP 模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层。
以通过 TCP 协议通信的网络包为例,通过下面,我们可以看到,应用程序数据在每个层的封装格式。
[ 应用数据 ] 应用层
[ TCP头 ] [ 应用数据 ] 传输层
[ IP头 ][ TCP头 ][ 应用数据 ] 网络层
[ 帧头 ][ IP头 ][ TCP头 ][ 应用数据 ][ 帧尾 ] 网络接口层
其中:
- 传输层在应用程序数据前面增加了 TCP 头;
- 网络层在 TCP 数据包前增加了 IP 头;
- 而网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
网络接口配置的最大传输单元(MTU),就规定了最大的 IP 包大小。在我们最常用的以太网中,MTU 默认值是 1500(这也是 Linux 的默认值)。
一旦网络包超过 MTU 的大小,就会在网络层分片,以保证分片后的 IP 包不大于 MTU值。显然,MTU 越大,需要的分包也就越少,自然,网络吞吐能力就越好。
Linux 通用 IP 网络栈的示意图
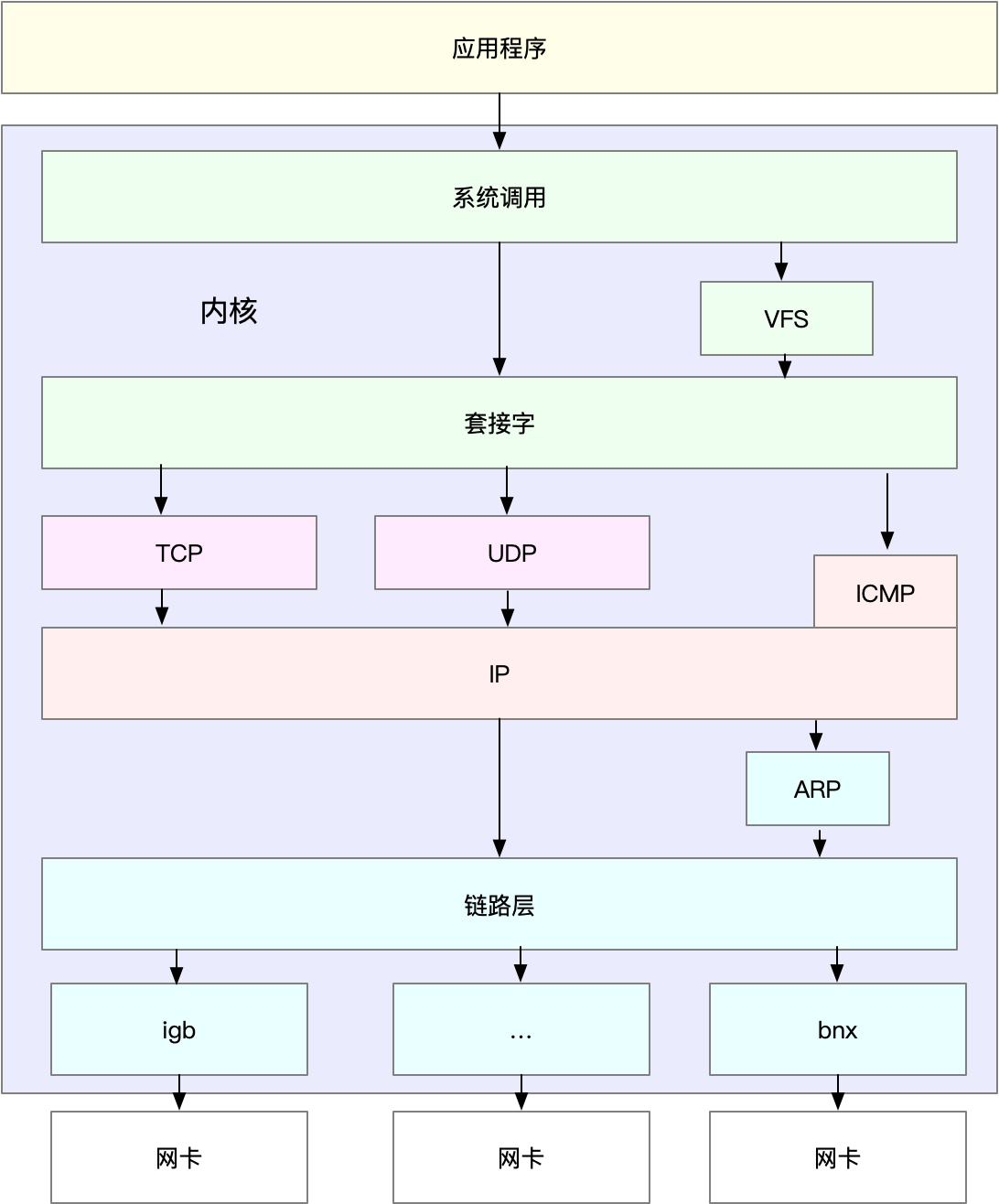
从上到下来看这个网络栈,可以发现,
- 最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
- 套接字的下面,就是前面提到的传输层、网络层和网络接口层;
- 最底层,则是网卡驱动程序以及物理网卡设备。
Linux 网络收发流程
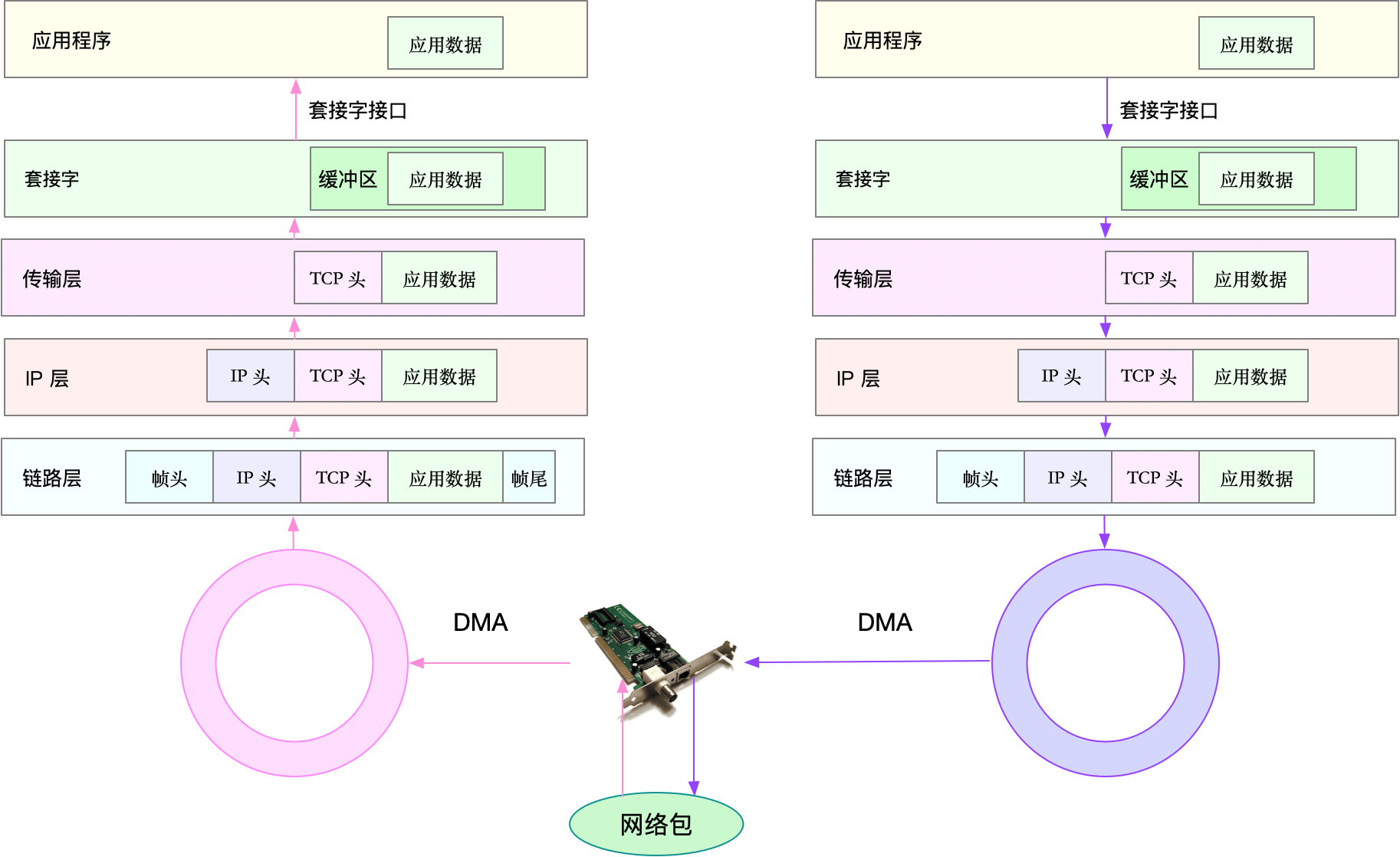
网络包的接收流程
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如,
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 <源 IP、源端口、目的 IP、目的端口> 四元组作为标识,找出对应的 Socket,并把数据拷贝到Socket 的接收缓存中。
最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
网络包的发送流程
了解网络包的接收流程后,就很容易理解网络包的发送流程。网络包的发送流程就是上图的右半部分,很容易发现,网络包的发送方向,正好跟接收方向相反。
- 首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。
- 由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
- 接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
- 分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
- 最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
半连接
所谓半连接,就是还没有完成 TCP 三次握手的连接,连接只进行了一半,而服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送SYN+ACK 包。
全连接
全连接则是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要再被 accept() 系统调用取走,这样,服务器就可以开始真正处理客户端的请求了。
C10K问题
怎么在这样的系统中支持并发 1 万的请求呢?
C10K 问题最早由 Dan Kegel 在 1999 年提出。那时的服务器还只是 32 位系统,运行着Linux 2.2 版本(后来又升级到了 2.4 和 2.6,而 2.6 才支持 x86_64),只配置了很少的内存(2GB)和千兆网卡。
I/O 模型优化
I/O 事件通知的方式
-
水平触发:只要文件描述符可以非阻塞地执行 I/O ,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作。
-
边缘触发:只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll。
根据刚才水平触发的原理,select 和 poll 需要从文件描述符列表中,找出哪些可以执行I/O ,然后进行真正的网络 I/O 读写。由于 I/O 是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。
优点:api非常简单
缺点:
- select有最大描述符数量的限制。比如,在 32 位系统中,默认限制是 1024。
-
poll使用一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)。但应用程序在使用 poll 时,同样需要对文件描述符列表进行轮询,这样,处理耗时跟描述符数量就是 O(N) 的关系。
- 应用程序每次调用 select 和 poll 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中。这一来一回的内核空间与用户空间切换,也增加了处理成本。
第二种,使用非阻塞 I/O 和边缘触发通知,比如 epoll。
epoll 使用红黑树,在内核中管理文件描述符的集合,这样,就不需要应用程序在每次操作时都传入、传出这个集合。 epoll 使用事件驱动的机制,只关注有 I/O 事件发生的文件描述符,不需要轮询扫描整个集合。
第三种,使用异步 I/O(Asynchronous I/O,简称为 AIO)
异步 I/O 允许应用程序同时发起很多 I/O操作,而不用等待这些操作完成。而在 I/O 完成后,系统会用事件通知(比如信号或者回调函数)的方式,告诉应用程序。这时,应用程序才会去查询 I/O 操作的结果。
工作模型优化
第一种,主进程 + 多个 worker 子进程,这也是最常用的一种模型。
- 主进程执行 bind() + listen() 后,创建多个子进程;
- 然后,在每个子进程中,都通过 accept() 或 epoll_wait() ,来处理相同的套接字。
第二种,监听到相同端口的多进程模型。
在这种方式下,所有的进程都监听相同的接口,并且开启 SO_REUSEPORT 选项,由内核负责将请求负载均衡到这些监听进程中去。
惊群问题
当网络I/O 事件发生时,多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠。
其中,accept() 的惊群问题,已经在 Linux 2.6 中解决了; 而 epoll 的问题,到了 Linux 4.5 ,才通过 EPOLLEXCLUSIVE 解决。
为了避免惊群问题, Nginx 在每个 worker 进程中,都增加一个了全局锁(accept_mutex)。这些 worker 进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到 epoll 中,这样就确保只有一个 worker 子进程被唤醒。
C1000K问题
怎么在这样的系统中支持并发 100 万的请求呢?
首先从物理资源使用上来说,100 万个请求需要大量的系统资源。比如,
- 假设每个请求需要 16KB 内存的话,那么总共就需要大约 15 GB 内存。
- 而从带宽上来说,假设只有 20% 活跃连接,即使每个连接只需要 1KB/s 的吞吐量,总共也需要 1.6 Gb/s 的吞吐量。千兆网卡显然满足不了这么大的吞吐量,所以还需要配置万兆网卡,或者基于多网卡 Bonding 承载更大的吞吐量。
其次,从软件资源上来说,大量的连接也会占用大量的软件资源,比如文件描述符的数量、连接状态的跟踪(CONNTRACK)、网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)等等。
最后,大量请求带来的中断处理,也会带来非常高的处理成本。这样,就需要多队列网卡、中断负载均衡、CPU 绑定、RPS/RFS(软中断负载均衡到多个 CPU 核上),以及将网络包的处理卸载(Offload)到网络设备(如 TSO/GSO、LRO/GRO、VXLANOFFLOAD)等各种硬件和软件的优化。
C1000K 的解决方法,本质上还是构建在 epoll 的非阻塞 I/O 模型上。只不过,除了 I/O模型之外,还需要从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件,来卸载那些原来通过软件处理的大量功能。
C10M问题
怎么在这样的系统中支持并发 1000 万的请求呢?
要解决这个问题,最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。这里有两种常见的机制,DPDK 和 XDP。
-
第一种机制,DPDK,是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收。
-
第二种机制,XDP(eXpress Data Path),则是 Linux 内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。XDP 底层跟我们之前用到的 bcc-tools 一样,都是基于 Linux 内核的 eBPF 机制实现的。
网络性能指标
带宽
表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
吞吐量
表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
延时
表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP握手延时),或一个数据包往返所需的时间(比如 RTT)。
PPS
是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
网络的可用性
网络能否正常通信
并发连接数
TCP 连接数量
丢包率
丢包百分比
重传率
重新传输的网络包比例
网络基准测试
- 基于 HTTP 或者 HTTPS 的 Web 应用程序,显然属于应用层,需要我们测试HTTP/HTTPS 的性能;
- 而对大多数游戏服务器来说,为了支持更大的同时在线人数,通常会基于 TCP 或 UDP,与客户端进行交互,这时就需要我们测试 TCP/UDP 的性能;
- 当然,还有一些场景,是把 Linux 作为一个软交换机或者路由器来用的。这种情况下,你更关注网络包的处理能力(即 PPS),重点关注网络层的转发性能。
各协议层的性能测试
转发性能
pktgen, Linux 内核自带的高性能网络测试工具
$ modprobe pktgen ## 载入模块
$ ps -ef | grep pktgen | grep -v grep
root 26384 2 0 06:17 ? 00:00:00 [kpktgend_0]
root 26385 2 0 06:17 ? 00:00:00 [kpktgend_1]
$ ls /proc/net/pktgen/
kpktgend_0 kpktgend_1 pgctrl
一个发包测试的示例
cat << 'EOF' > pktgen_test.sh
# 定义一个工具函数,方便后面配置各种测试选项
function pgset() {
local result
echo $1 > $PGDEV
result=`cat $PGDEV | fgrep "Result: OK:"`
if [ "$result" = "" ]; then
cat $PGDEV | fgrep Result:
fi
}
# 为 0 号线程绑定 eth0 网卡
PGDEV=/proc/net/pktgen/kpktgend_0
pgset "rem_device_all" # 清空网卡绑定
pgset "add_device ens33" # 添加 eth0 网卡
# 配置 ens33 网卡的测试选项
PGDEV=/proc/net/pktgen/ens33
pgset "count 1000000" # 总发包数量
pgset "delay 5000" # 不同包之间的发送延迟 (单位纳秒)
pgset "clone_skb 0" # SKB 包复制
pgset "pkt_size 64" # 网络包大小
pgset "dst 192.168.77.131" # 目的 IP
pgset "dst_mac 00:0c:29:73:e9:53" # 目的 MAC
# 启动测试
PGDEV=/proc/net/pktgen/pgctrl
pgset "start"
EOF
运行
bash pktgen_test.sh
查看测试报告
# cat /proc/net/pktgen/ens33
Params: count 1000000 min_pkt_size: 64 max_pkt_size: 64
frags: 0 delay: 5000 clone_skb: 0 ifname: ens33
flows: 0 flowlen: 0
queue_map_min: 0 queue_map_max: 0
dst_min: 192.168.77.131 dst_max:
src_min: src_max:
src_mac: 00:0c:29:5d:bb:9c dst_mac: 00:0c:29:73:e9:53
udp_src_min: 9 udp_src_max: 9 udp_dst_min: 9 udp_dst_max: 9
src_mac_count: 0 dst_mac_count: 0
Flags:
Current:
pkts-sofar: 1000000 errors: 0
started: 303132397us stopped: 318989056us idle: 21941us
seq_num: 1000001 cur_dst_mac_offset: 0 cur_src_mac_offset: 0
cur_saddr: 192.168.77.140 cur_daddr: 192.168.77.131
cur_udp_dst: 9 cur_udp_src: 9
cur_queue_map: 0
flows: 0
Result: OK: 15856659(c15834717+d21941) usec, 1000000 (64byte,0frags)
63064pps 32Mb/sec (32288768bps) errors: 0
你可以看到,测试报告主要分为三个部分:
第一部分的 Params 是测试选项; 第二部分的 Current 是测试进度,其中, packts so far(pkts-sofar)表示已经发送了100 万个包,也就表明测试已完成。 第三部分的 Result 是测试结果,包含测试所用时间、网络包数量和分片、PPS、吞吐量以及错误数。
TCP/UDP 性能
iperf 和 netperf 都是最常用的网络性能测试工具
**安装 iperf **
# Ubuntu
apt-get install iperf3
# CentOS
yum install iperf3
然后,在目标机器上启动 iperf 服务端:
# -s 表示启动服务端,-i 表示汇报间隔,-p 表示监听端口
$ iperf3 -s -i 1 -p 10000
接着,在另一台机器上运行 iperf 客户端,运行测试:
# -c 表示启动客户端,192.168.0.30 为目标服务器的 IP
# -b 表示目标带宽 (单位是 bits/s)
# -t 表示测试时间# -P 表示并发数,-p 表示目标服务器监听端口
$ iperf3 -c 192.168.77.131 -b 1G -t 15 -P 2 -p 10000
Connecting to host 192.168.77.131, port 10000
[ 4] local 192.168.77.130 port 47044 connected to 192.168.77.131 port 10000
[ 6] local 192.168.77.130 port 47046 connected to 192.168.77.131 port 10000
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 117 MBytes 985 Mbits/sec 207 990 KBytes
[ 6] 0.00-1.00 sec 115 MBytes 965 Mbits/sec 99 1.11 MBytes
[SUM] 0.00-1.00 sec 233 MBytes 1.95 Gbits/sec 306
- - - - - - - - - - - - - - - - - - - - - - - - -
...
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-15.00 sec 1.74 GBytes 995 Mbits/sec 268 sender
[ 4] 0.00-15.00 sec 1.74 GBytes 995 Mbits/sec receiver
[ 6] 0.00-15.00 sec 1.74 GBytes 995 Mbits/sec 175 sender
[ 6] 0.00-15.00 sec 1.74 GBytes 995 Mbits/sec receiver
[SUM] 0.00-15.00 sec 3.47 GBytes 1.99 Gbits/sec 443 sender
[SUM] 0.00-15.00 sec 3.47 GBytes 1.99 Gbits/sec receiver
iperf Done.
最后的 SUM 行就是测试的汇总结果,包括测试时间、数据传输量以及带宽等。按照发送和接收,这一部分又分为了 sender 和 receiver 两行。
HTTP 性能
ab 是 Apache 自带的 HTTP 压测工具,主要测试 HTTP 服务的每秒请求数、请求延迟、吞吐量以及请求延迟的分布情况等。
安装 ab
# Ubuntu
$ apt-get install -y apache2-utils
# CentOS
$ yum install -y httpd-tools
在目标机器上,启动一个http服务
docker run -p 80:80 -itd nginx
而在另一台机器上,运行 ab 命令
# -c 表示并发请求数为 1000,-n 表示总的请求数为 10000
$ ab -c 1000 -n 10000 http://192.168.77.131/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.77.131 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.17.8
Server Hostname: 192.168.77.131
Server Port: 80
Document Path: /
Document Length: 612 bytes
Concurrency Level: 1000
Time taken for tests: 3.363 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 8450000 bytes
HTML transferred: 6120000 bytes
Requests per second: 2973.36 [#/sec] (mean)
Time per request: 336.320 [ms] (mean)
Time per request: 0.336 [ms] (mean, across all concurrent requests)
Transfer rate: 2453.60 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 94 233.0 38 1112
Processing: 6 104 198.6 53 2268
Waiting: 1 101 198.6 50 2267
Total: 38 198 299.0 93 2302
Percentage of the requests served within a certain time (ms)
50% 93
66% 105
75% 118
80% 143
90% 366
95% 1105
98% 1138
99% 1163
100% 2302 (longest request)
在请求汇总部分,你可以看到:
Requests per second 为 2973.36;
每个请求的延迟(Time per request)分为两行,第一行的 336.320 ms 表示平均延迟,包括了线程运行的调度时间和网络请求响应时间,而下一行的 0.336ms ,则表示实际请求的响应时间;
Transfer rate 表示吞吐量(BPS)为 2453.60 KB/s。
应用负载性能
为了得到应用程序的实际性能,就要求性能工具本身可以模拟用户的请求负载,而iperf、ab 这类工具就无能为力了。幸运的是,我们还可以用 wrk、TCPCopy、Jmeter 或者 LoadRunner 等实现这个目标。
以 wrk 为例,它是一个 HTTP 性能测试工具,内置了 LuaJIT,方便你根据实际需求,生成所需的请求负载,或者自定义响应的处理方法。
安装wrk
wget https://codeload.github.com/wg/wrk/zip/master
$ cd wrk
$ apt-get install build-essential -y
$ make
$ sudo cp wrk /usr/local/bin/
wrk 的命令行参数比较简单。比如,我们可以用 wrk ,来重新测一下前面已经启动的Nginx 的性能。
# -c 表示并发连接数 1000,-t 表示线程数为 2
# wrk -c 1000 -t 2 http://192.168.77.131/
Running 10s test @ http://192.168.77.131/
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 125.73ms 70.26ms 898.04ms 91.56%
Req/Sec 3.99k 1.73k 9.33k 63.78%
78868 requests in 10.09s, 63.93MB read
Requests/sec: 7815.96
Transfer/sec: 6.34MB
这里使用 2 个线程、并发 1000 连接,重新测试了 Nginx 的性能。你可以看到,每秒请求数为 7815.96,吞吐量为6.34MB,平均延迟为125.73ms,比前面 ab 的测试结果要好很多。
wrk 最大的优势,是其内置的 LuaJIT,可以用来实现复杂场景的性能测试。
cat <<EOF >> auth.lua
-- example script that demonstrates response handling and
-- retrieving an authentication token to set on all future
-- requests
token = nil
path = "/authenticate"
request = function()
return wrk.format("GET", path)
end
response = function(status, headers, body)
if not token and status == 200 then
token = headers["X-Token"]
path = "/resource"
wrk.headers["X-Token"] = token
end
end
EOF
网络性能工具
根据指标找工具
| 性能指标 | 工具 | 说明 |
|---|---|---|
| 吞吐量(BPS) | sar nethogs iftop |
分别可以查看网络接口、进程以及IP地址的网络吞吐量 |
| PPS | sar /proc/net/dev |
查看网络接口的PPS |
| 连接数 | netstat ss |
查看网络连接数 |
| 延迟 | ping hping3 |
通过ICMP、TCP等测试网络延迟 |
| 连接跟踪数 | conntrack | 查看和管理连接跟踪状况 |
| 路由 | mtr route traceroute |
查看路由并测试链路信息 |
| DNS | dig nslookup |
排查DNS解析问题 |
| 防火墙和NAT | iptables | 配置和管理防火墙及NAT规则 |
| 网卡功能 | ethtool | 查看和配置网络接口的功能 |
| 抓包 | tcpdump Wireshark |
抓包分析网络流量 |
| 内核协议栈跟踪 | bcc systemtap |
动态跟踪内核协议栈的行为 |
根据工具找指标
| 性能工具 | 主要功能 |
|---|---|
| ifconfig ip |
配置和查看网络接口 |
| ss | 查看网络连接数 |
| sar /proc/net /dev/sys/class/net/eth0/statistics/ |
查看网络接口的网络收发情况 |
| nethogs | 查看进程的网络收发情况 |
| iftop | 查看IP的网络收发情况 |
| ethool | 查看和配置网络接口 |
| conntrack | 查看和管理连接跟踪状况 |
| nslookup dig |
排查DNS解析问题 |
| mtr route traceroute |
查看路由并测试链路信息 |
| ping hping3 |
测试网络延迟 |
| tcpdump | 网络抓包工具 |
| Wireshark | 网络抓包和图形界面分析工具 |
| iptables | 配置和管理防火墙及NAT规则 |
| perf | 剖析内核协议栈的性能 |
| systemtap bcc |
动态追踪内核协议栈的行为 |
网络性能优化
应用程序优化
从网络 I/O 的角度来说,主要有下面两种优化思路。
- 第一种是最常用的 I/O 多路复用技术 epoll,主要用来取代 select 和 poll。这其实是解决C10K 问题的关键,也是目前很多网络应用默认使用的机制。
- 第二种是使用异步 I/O(Asynchronous I/O,AIO)。AIO 允许应用程序同时发起很多I/O 操作,而不用等待这些操作完成。等到 I/O 完成后,系统会用事件通知的方式,告诉应用程序结果。不过,AIO 的使用比较复杂,你需要小心处理很多边缘情况。
从进程的工作模型来说,也有两种不同的模型用来优化。
- 第一种,主进程 + 多个 worker 子进程。其中,主进程负责管理网络连接,而子进程负责实际的业务处理。这也是最常用的一种模型。
- 第二种,监听到相同端口的多进程模型。在这种模型下,所有进程都会监听相同接口,并且开启
SO_REUSEPORT选项,由内核负责,把请求负载均衡到这些监听进程中去。
应用层的网络协议优化
- 使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式,来缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络I/O 的整体速度。
套接字优化
每个套接字,都有一个读写缓冲区。
- 读缓冲区,缓存了远端发过来的数据。如果读缓冲区已满,就不能再接收新的数据。
- 写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会被阻塞。
为了提高网络的吞吐量,通常需要调整这些缓冲区的大小:
- 增大每个套接字的缓冲区大小 net.core.optmem_max;
- 增大套接字接收缓冲区大小 net.core.rmem_max 和发送缓冲区大小net.core.wmem_max;
- 增大 TCP 接收缓冲区大小 net.ipv4.tcp_rmem 和发送缓冲区大小net.ipv4.tcp_wmem。
除此之外,套接字接口还提供了一些配置选项,用来修改网络连接的行为。
- 为 TCP 连接设置 TCP_NODELAY 后,就可以禁用 Nagle 算法;
- 为 TCP 连接开启 TCP_CORK 后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
网络性能优化
传输层
第一类,在请求数比较大的场景下,可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
- 增大处于 TIME_WAIT 状态的连接数量
net.ipv4.tcp_max_tw_buckets,并增大连接跟踪表的大小net.netfilter.nf_conntrack_max。 - 减小
net.ipv4.tcp_fin_timeout和net.netfilter.nf_conntrack_tcp_timeout_time_wait,让系统尽快释放它们所占用的资源。 - 开启端口复用
net.ipv4.tcp_tw_reuse。这样,被TIME_WAIT状态占用的端口,还能用到新建的连接中。 - 增大本地端口的范围
net.ipv4.ip_local_port_range。这样就可以支持更多连接,提高整体的并发能力。 - 增加最大文件描述符的数量。你可以使用
fs.nr_open,设置系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置LimitNOFILE,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
- 增大 TCP 半连接的最大数量
net.ipv4.tcp_max_syn_backlog,或者开启 TCP SYNCookiesnet.ipv4.tcp_syncookies,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。 - 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数
net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间
net.ipv4.tcp_keepalive_time; - 缩短发送 Keepalive 探测包的间隔时间
net.ipv4.tcp_keepalive_intvl; - 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数
net.ipv4.tcp_keepalive_probes。
网络层
第一种,从路由和转发的角度出发,你可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启IP 转发,即设置
net.ipv4.ip_forward = 1。 - 调整数据包的生存周期 TTL,比如设置
net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。 - 开启数据包的反向地址校验,比如设置
net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的大小。
通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。 在使用 VXLAN、GRE 等叠加网络技术时,要注意,网络叠加会使原来的网络包变大,导致 MTU 也需要调整。比如,就以 VXLAN 为例,它在原来报文的基础上,增加了 14B 的以太网头部、 8B 的VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包比原来增大了50B。就需要把 VXLAN 封包前(比如虚拟化环境中的虚拟网卡)的 MTU 减小为 1450。 另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把 MTU 调大为 9000,以提高网络吞吐量。
第三种,从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问题,你可以通过内核选项,来限制 ICMP 的行为。
- 禁止 ICMP 协议,即设置
net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就无法通过 ICMP 来探测主机。 - 禁止广播 ICMP,即设置
net.ipv4.icmp_echo_ignore_broadcasts =1。
链路层
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。这通常可以采用下面两种方法。
- 可以为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance服务。
- 可以开启 RPS(Receive Packet Steering)和 RFS(Receive FlowSteering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU缓存命中率,减少网络延迟。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。
最后,对于网络接口本身,也有很多方法,可以优化网络的吞吐量。
- 可以开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 可以增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 可以使用 Traffic Control 工具,为不同网络流量配置 QoS。
内核协议栈
跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。
- 第一种,使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
- 第二种,使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
ip -s addr show dev eth0
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。 第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。 第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。 第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。
性能工具的使用
ss
ss是Socket Statistics的缩写。顾名思义,ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。在iproute2工具包中
ss -ltnp
当套接字处于连接状态(Established)时,
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时,
- Recv-Q 表示 syn backlog 的当前值。
- 而 Send-Q 表示最大的 syn backlog 值。
常用命令
# 显示TCP连接
ss -t -a
#显示 Sockets 摘要
ss -s
#列出当前的established, closed, orphaned and waiting TCP sockets
ss -l
#查看进程使用的socket
ss - pl
#显示所有UDP Sockets
ss -u -a
# 显示所有状态为Established的HTTP连接
ss -o state established '( dport = :http or sport = :http )'
# 列举出处于 FIN-WAIT-1状态的源端口为 80或者 443,目标网络为 193.233.7/24所有 tcp套接字
ss -o state fin-wait-1 '( sport = :http or sport = :https )' dst 193.233.7/24
#用TCP 状态过滤Sockets
ss -4 state closing
#匹配远程地址和端口号
ss dst 192.168.119.113
#将本地或者远程端口和一个数比较
ss sport eq :22
ss dport \> :1024
sar
sar是System Activity Reporter(系统活动情况报告)的缩写。sar工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。
sar -n DEV 1
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
ping
ping 命令基于IMCP协议,通常用来测试与目标主机的连通性
常见命令参数
- -q 不显示任何传送封包的信息,只显示最后的结果
- -n 只输出数值
- -R 记录路由过程
- -c count 总次数
- -i 时间间隔
- -t 存活数值:设置存活数值TTL的大小
ping -c3 114.114.114.114
- 第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
- 第二部分,则是三次 ICMP 请求的汇总。
netstat
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 288 0 0 0 249 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU
输出中的 RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
netstat -s
Ip:
190 total packets received # 总收包数
0 forwarded # 是否转发
0 incoming packets discarded # 接收丢包数
148 incoming packets delivered # 接收的数据包数
143 requests sent out # 发出的数据包数
Icmp:
0 ICMP messages received # 收到的 ICMP 包数
0 input ICMP message failed. # 收到 ICMP 失败数
ICMP input histogram:
0 ICMP messages sent # ICMP 发送数
0 ICMP messages failed # ICMP 失败数
ICMP output histogram:
Tcp:
0 active connections openings # 主动连接数
2 passive connection openings # 被动连接数
0 failed connection attempts # 失败连接尝试数
0 connection resets received # 接收的连接重置数
2 connections established # 建立连接数
144 segments received # 已接收报文数
138 segments send out # 已发送报文数
0 segments retransmited # 重传报文数
0 bad segments received. # 错误报文数
0 resets sent # 发出的连接重置数
Udp:
4 packets received
0 packets to unknown port received.
0 packet receive errors
5 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
5 delayed acks sent
2 packets directly queued to recvmsg prequeue.
99 packet headers predicted
17 acknowledgments not containing data payload received
16 predicted acknowledgments
TCPRcvCoalesce: 8
TCPOrigDataSent: 42
IpExt:
InBcastPkts: 42
InOctets: 18717
OutOctets: 13907
InBcastOctets: 3276
InNoECTPkts: 190
常用命令
#列出所有端口
netstat -a
#列出所有 tcp 端口
netstat -at
#列出所有 udp 端口
netstat -au
#只显示监听端口
netstat -l
#只列出所有监听 tcp 端口
netstat -lt
#只列出所有监听 udp 端口
netstat -lu
#列出所有监听 UNIX 端口
netstat -lx
#显示所有端口的统计信息
netstat -s
#显示 TCP 或 UDP 端口的统计信息
netstat -st 或 -su
#输出中显示 PID 和进程名称
netstat -p
tc
流量控制器TC(Traffic Control)用于Linux内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。
# 查看网口的规则
tc -s qdisc show dev ens33
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 20439 bytes 246 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
ftrace
ftrace 是内建于 Linux 内核的跟踪工具,从 2.6.27 开始加入主流内核。使用 ftrace 可以调试或者分析内核中发生的事情。ftrace 提供了不同的跟踪器,以用于不同的场合,比如跟踪内核函数调用、对上下文切换进行跟踪、查看中断被关闭的时长、跟踪内核态中的延迟以及性能问题等。系统开发人员可以使用 ftrace 对内核进行跟踪调试,以找到内核中出现的问题的根源,方便对其进行修复。另外,对内核感兴趣的读者还可以通过 ftrace 来观察内核中发生的活动,了解内核的工作机制。
使用 ftrace,需要切换到 debugfs 的挂载点开始。
# cd /sys/kernel/debug/tracing
# ls
available_events current_tracer function_profile_enabled
...
# echo 1 > /proc/sys/kernel/ftrace_enabled
如果目录不存在,则需要挂载debugfs
mount -t debugfs nodev /sys/kernel/debug
常用文件说明
-
available_tracers 支持的跟踪器
-
available_filter_functions 支持的函数
-
available_events 支持的事件
操作方法
使用 ftrace 提供的跟踪器来调试或者分析内核时需要如下操作:
- 切换到目录 /sys/kernel/debug/tracing/ 下
- 查看 available_tracers 文件,获取当前内核支持的跟踪器列表
- 关闭 ftrace 跟踪,即将 0 写入文件 tracing_enabled
-
激活 ftrace_enabled ,否则 function 跟踪器的行为类似于 nop;另外,激活该选项还可以让一些跟踪器比如 irqsoff 获取更丰富的信息。建议使用 ftrace 时将其激活。要激活 ftrace_enabled ,可以通过 proc 文件系统接口来设置:
echo 1 > /proc/sys/kernel/ftrace_enabled - 将所选择的跟踪器的名字写入文件 current_tracer
- 将要跟踪的函数写入文件 set_ftrace_filter ,将不希望跟踪的函数写入文件 set_ftrace_notrace。通常直接操作文件 set_ftrace_filter 就可以了
- 激活 ftrace 跟踪,即将 1 写入文件 tracing_enabled。还要确保文件 tracing_on 的值也为 1,该文件可以控制跟踪的暂停
- 如果是对应用程序进行分析的话,启动应用程序的执行,ftrace 会跟踪应用程序运行期间内核的运作情况
- 通过将 0 写入文件 tracing_on 来暂停跟踪信息的记录,此时跟踪器还在跟踪内核的运行,只是不再向文件 trace 中写入跟踪信息;或者将 0 写入文件 tracing_enabled 来关闭跟踪
- 查看文件 trace 获取跟踪信息,对内核的运行进行分析调试
使用方法
-
把要跟踪的函数设置为 do_sys_open
echo do_sys_open > set_graph_function -
配置跟踪选项,开启函数调用跟踪,并跟踪调用进程
echo function_graph > current_tracer echo funcgraph-proc > trace_options -
开启跟踪
echo 1 > tracing_on echo 1 > tracing_enabled -
执行一个 ls 命令后,再关闭跟踪
ls echo 0 > tracing_on echo 0 > tracing_enabled -
查看跟踪结果
cat trace
在最后得出的结果
- 第一列表示运行的 CPU;
- 第二列是任务名称和进程 PID;
- 第三列是函数执行延迟;
- 最后一列,则是函数调用关系图。