- 2021-09-20~26
- 2021-09-13~19
- 2021-09-06~12
- 2021-08-30~05
- 2021-07-26~01
- 2021-07-19~25
- 2021-07-12~18
- 2021-07-05~11
- 2021-06-28~04
- 2021-06-21~27
- 2021-06-07~13
- 2021-05-31~06
- 2021-05-24~30
- 2021-05-17~23
- 2021-05-10~16
- 2021-04-19~25
- 2021-04-12~18
- 2021-04-05~11
- 2021-03-29~04
- 2021-03-22~28
- 2021-03-15~21
- 2021-03-08~14
- 2021-03-01~07
- 2021-02-22~28
- 2021-02-18~21
- 2021-02-01~07
- 2021-01-25~31
- 2021-01-18~24
- 2021-01-11~17
- 2021-01-4~10
以每周一个节点,记录知识点。
2021-09-20~26
k8s CPU limit 和 throttling
资源限制配置:
resources:
requests:
memory: 200Mi # 剩余内存大于200MB的节点
cpu: "0.1" # 剩余cpu资源大于0.1核的节点
limits:
memory: 300Mi # 内存使用不多余300MB(超过将被OOM Kill并重新调度POD)
cpu: "0.4" # CPU使用率不能高于0.4核(超过将被限流,即延长响应时间)
CPU 限流:
即使CPU没有其他的工作要做,限流一样会执行
k8s使用CFS(Completely Fair Scheduler,完全公平调度)限制负载的CPU使用率,CFS本身的机制比较复杂,但是k8s的文档中给了一个简明的解释,要点如下:
- CPU使用量的计量周期为100ms;
- CPU limit决定每计量周期(100ms)内容器可以使用的CPU时间的上限;
- 本周期内若容器的CPU时间用量达到上限,CPU限流开始,容器只能在下个周期继续执行;
- 1 CPU = 100ms CPU时间每计量周期,以此类推,0.2 CPU = 20ms CPU时间每计量周期,2.5 CPU = 250ms CPU时间每计量周期;
- 如果程序用了多个核,CPU时间会累加统计。
**避免CPU限流: **
- 监控一段时间应用的CPU利用率,基于利用率设定一个合适的CPU limit(例如,日常利用率的95分位 * 10),同时该limit不要占到节点CPU核数的太大比例,这样可以达到性能和安全的一个平衡。
- 使用automaxprocs一类的工具让程序适配CFS调度环境,各个语言应该都有类似的库或者执行参数,根据CFS的特点调整后,程序更不容易遇到CPU限流。
- 不设 cpu limit,裸奔直接跑 , 这样会有耗尽节点CPU的风险。
参考:
- 内核版本低于4.18的Linux还真有个bug会造成不必要的CPU限流
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu
- https://stackoverflow.com/questions/68846880/azure-kubernetes-cpu-multithreading
- https://cloud.tencent.com/developer/article/1736729
- https://nanmu.me/zh-cn/posts/2021/myth-of-k8s-cpu-limit-and-throttle/
2021-09-13~19
手动实现 IPVS SVC
安装 ipvs 工具
yum install -y ipvsadm curl wget tcpdump ipset conntrack-tools
配置内核模块和参数
cat > /etc/modules-load.d/ipvs.conf << EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
EOF
systemctl restart systemd-modules-load
systemctl enable systemd-modules-load
cat > /etc/sysctl.d/90.ipvs.conf << EOF
# https://github.com/moby/moby/issues/31208
# ipvsadm -l --timout
# 修复ipvs模式下长连接timeout问题 小于900即可
net.ipv4.tcp_keepalive_time=600
net.ipv4.tcp_keepalive_intvl=30
net.ipv4.vs.conntrack=1
net.ipv4.ip_forward = 1
EOF
sysctl --system
清空 lvs 和 iptables 规则
ipvsadm --clear
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
# 确认规则清空
ipvsadm -ln
iptables -S
iptables -t nat -S
操作步骤
# SVC
SVC_IP=169.254.11.2
SVC_Port=80
RS1=192.168.77.140:8080
RS2=192.168.77.141:8080
# lvs 做 DNAT
ipvsadm --add-service --tcp-service ${SVC_IP}:${SVC_Port} --scheduler rr
## 添加 real server
ipvsadm --add-server --tcp-service ${SVC_IP}:${SVC_Port} --real-server $RS1 --masquerading --weight 1
ipvsadm --add-server --tcp-service ${SVC_IP}:${SVC_Port} --real-server $RS2 --masquerading --weight 1
## 添加 NAT GW
ip addr add ${SVC_IP}/32 dev ens33
### 也可以使用dumy接口
ip link add svc type dummy
ip addr add ${SVC_IP}/32 dev svc
# iptables 做 SNAT
iptables -t nat -A POSTROUTING -m ipvs --vaddr ${SVC_IP} --vport 80 -j MASQUERADE
iptables 做 SNAT 还可以选择 iptables mark 方案
利用 iptables 的 mark 和 ipset 配合减少 iptables 规则。
# PREROUTING 阶段处理
## 提供一个入口链,而不是直接添加在 PREROUTING 链上
iptables -t nat -N SVC-SERVICES
iptables -t nat -A PREROUTING -m comment --comment "SVC service portals" -j SVC-SERVICES
## 在 PREROUTING 子链里去 ipset 匹配,跳转到我们 mark 的链
iptables -t nat -N SVC-MARK-MASQ
## 创建存储所有 `SVC_IP:SVC_PORT` 的 ipset
ipset create SVC-CLUSTER-IP hash:ip,port -exist
iptables -t nat -A SVC-SERVICES -m comment --comment "SVC service cluster ip + port for masquerade purpose" -m set --match-set SVC-CLUSTER-IP dst,dst -j SVC-MARK-MASQ
## 专门 mark 的链
iptables -t nat -A SVC-MARK-MASQ -j MARK --set-xmark 0x2000/0x2000
# POSTROUTING 阶段处理
## 提供一个入口链,而不是直接添加在 POSTROUTING 链上
iptables -t nat -N SVC-POSTROUTING
iptables -t nat -A POSTROUTING -m comment --comment "SVC postrouting rules" -j SVC-POSTROUTING
## 在 POSTROUTING 阶段做 snat
iptables -t nat -A SVC-POSTROUTING -m comment --comment "SVC service traffic requiring SNAT" -m mark --mark 0x2000/0x2000 -j MASQUERADE
# OUTPUT 阶段处理
## 本地转发
iptables -t nat -A OUTPUT -m comment --comment "SVC service portals" -j SVC-SERVICES
# 然后添加下 SVC_IP:SVC_PORT 到我们的 ipset 里, 后续有svc,直接加在ipset里就行了。
ipset add SVC-CLUSTER-IP 169.254.11.2,tcp:80 -exist
健康检查:keepalived
https://zhangguanzhang.github.io/2021/09/28/ipvs-svc
2021-09-06~12
Dockerfile ARG 使用
ARG TAG=latest \
APP_ENV=test
FROM alpine:$TAG
ENV APP_ENV=$APP_ENV \
TAG=$TAG
RUN echo $TAG \
&& echo $APP_ENV
上面的 dockerfile 会出现输出 $TAG $APP_ENV 变量为空的情况。
从外部传递过来的参数,在 FROM 引用基础镜像之后,必须使用 ARG 重新声明一次,否则无法生效,此外,如果是 ENTRYPOINT只接受 ENV 所以需要再 ARG 之后再声明为 ENV
ARG TAG=latest
FROM alpine:$TAG
ARG TAG \
APP_ENV=test
ENV APP_ENV=$APP_ENV \
TAG=$TAG
RUN echo $TAG \
&& echo $APP_ENV
2021-08-30~05
磁盘 I/O 调度算法
-
CFQ (Completely Fair Queuing 完全公平的排队)(elevator=cfq):
这是默认算法,对于通用服务器来说通常是最好的选择。它试图均匀地分布对I/O带宽的访问。在多媒体应用, 总能保证audio、video及时从磁盘读取数据。但对于其他各类应用表现也很好。每个进程一个queue,每个queue按照上述规则进行merge 和sort。进程之间round robin调度,每次执行一个进程的4个请求。
-
Deadline (elevator=deadline):
这个算法试图把每次请求的延迟降至最低。该算法重排了请求的顺序来提高性能。
-
NOOP (elevator=noop):
这个算法实现了一个简单FIFO队列。他假定I/O请求由驱动程序或者设备做了优化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有 些SAN环境下,这个选择可能是最好选择。适用于随机存取设备, no seek cost,非机械可随机寻址的磁盘。
-
Anticipatory (elevator=as):
这个算法推迟I/O请求,希望能对它们进行排序,获得最高的效率。同deadline不同之处在于每次处理完读请求之后, 不是立即返回, 而是等待几个微妙在这段时间内, 任何来自临近区域的请求都被立即执行. 超时以后, 继续原来的处理.基于下面的假设: 几个微妙内, 程序有很大机会提交另一次请求.调度器跟踪每个进程的io读写统计信息, 以获得最佳预期。
对 IO 调度使用的建议:
- CFQ I/O scheduler使用QoS策略为所有任务分配等量的带宽,避免进程被饿死并实现了较低的延迟,可以认为是上述两种调度器的折中.适用于有大量进程的多用户系统
- Deadline I/O scheduler 使用轮询的调度器,简洁小巧,提供了最小的读取延迟和尚佳的吞吐量,特别适合于读取较多的环境(比如数据库,Oracle 10G 之类).
- Anticipatory I/O scheduler 假设一个块设备只有一个物理查找磁头(例如一个单独的SATA硬盘),将多个随机的小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量.适用于 大多数环境,特别是写入较多的环境(比如文件服务器)Web,App等应用我们可以采纳as调度.
修改算法
echo "deadline" > /sys/block/${device-name}/queue/scheduler
永久修改
1. 编辑 /boot/grub/grub.cfg
2. 添加 io 算法
linux /vmlinuz-4.4.0-31-generic root=/dev/mapper/ashish--devbox--vg-root ro elevator=deadline
查看某个路径所在的 io 调度算法
DB_DATA_PATH=/data/mysql_data
DEVICE=$( findmnt -T ${DB_DATA_PATH} -o SOURCE --noheadings )
DEVICE=${DEVICE##*/}
DEVICE=$( tr -d '0-9' <<< "${DEVICE}")
# 查看 io 调度算法
cat /sys/block/${DEVICE}/queue/scheduler
通过 systemd 调整算法
cat > /etc/systemd/system/mysql-block.service << EOF
[Unit]
Description=set block scheduler for mysql
After=systemd-remount-fs.service
[Service]
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Type=oneshot
ConditionPathExists=/sys/block/sdb
ExecStart=/bin/bash -c 'echo deadline > /sys/block/sdb/queue/scheduler'
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
EOF
systemctl enable mysql-block.service
测试io
fio --name TEST --eta-newline=5s --filename=fio-tempfile.dat --rw=randwrite --size=500m --io_size=2g --blocksize=4k --ioengine=libaio --fsync=1 --iodepth=1 --direct=1 --numjobs=1 --runtime=60 --group_reporting
https://codeistry.wordpress.com/2020/01/16/ubuntu-18-04-poor-disk-read-performance/
https://zhangguanzhang.github.io/2021/09/01/ubuntu18-and-cfq/
http://blog.chinaunix.net/uid-20618535-id-70900.html
2021-07-26~01
Here-document syntax
Here Document 是在Linux Shell 中的一种特殊的重定向方式,它的基本的形式如下
cmd << delimiter
Here Document Content
delimiter
其作用是将两个 delimiter 之间的内容(Here Document Content 部分) 传递给cmd 作为输入参数
$ cat << EOF
> \$ Working dir "$PWD" `pwd`
> EOF
$ Working dir "/home/user" /home/user
# 格式变形
$ cat << EOF > output.txt
> echo "hello"
> echo "world"
$ EOF
# 转义变量
$ cat << "EOF" > output.sh #注意引号
> echo "This is output"
> echo $1
$ EOF
# 去除制表符 <<-
$ cat <<- "EOF" > output.sh #注意引号
> echo "This is output"
> echo $1
$ EOF
# Here String <<<
$ foo='one two three'
$ LANG=C tr a-z A-Z <<< "$foo"
2021-07-19~25
kubectl port-forward 的工作原理
kubectl port-forward nginx 8080:8080
-
首先,该函数检查
socat和nsenter是否存在// https://github.com/DarkSeid5130/kubernetes14.1/blob/40df9f82d0572a123f5ad13f48312978a2ff5877/pkg/kubelet/dockershim/docker_streaming_others.go#L31 containerPid := container.State.Pid socatPath, lookupErr := exec.LookPath("socat") if lookupErr != nil { return fmt.Errorf("unable to do port forwarding: socat not found.") } args := []string{"-t", fmt.Sprintf("%d", containerPid), "-n", socatPath, "-", fmt.Sprintf("TCP4:localhost:%d", port)} nsenterPath, lookupErr := exec.LookPath("nsenter") if lookupErr != nil { return fmt.Errorf("unable to do port forwarding: nsenter not found.") } -
如果两项检查均通过,它将使用
exec() nsenter将目标进程 id(pause 容器 的 PID)传递给“-t”,并将命令传递给“-n”:// https://github.com/DarkSeid5130/kubernetes14.1/blob/40df9f82d0572a123f5ad13f48312978a2ff5877/pkg/kubelet/dockershim/docker_streaming_others.go#L54 commandString := fmt.Sprintf("%s %s", nsenterPath, strings.Join(args, " ")) glog.V(4).Infof("executing port forwarding command: %s", commandString) command := exec.Command(nsenterPath, args...) command.Stdout = stream这可以使用 Brendan Gregg’s execsnoop 工具进行验证:
$ execsnoop -n nsenter PCOMM PID PPID RET ARGS nsenter 25898 976 0 /usr/bin/nsenter -t 4947 -n /usr/bin/socat - TCP4:localhost:8080
2021-07-12~18
k8s hostPort
hostPort 是直接将容器的端口与所调度的节点上的端口路由。 hostPort, 是由 portmap 这个 cni 提供 portMapping 能力,同时,如果想使用这个能力,在配置文件中一定需要开启 portmap 。
使用 hostPort 后,会在 iptables 的 nat 链中插入相应的规则,而且这些规则是在 KUBE- SERVICES 规则之前插入的,也就是说会优先匹配 hostPort 的规则,我们常用的 NodePort 规则其实是在 KUBE- SERVICES 之中,也排在其后
特征
-
iptables 规则。
-A CNI-DN-xxxx -p tcp -m tcp --dport 3306 -j DNAT --to-destination 10.224.0.222:3306 -A CNI-HOSTPORT-DNAT -m comment --comment "dnat name": \"cni0\" id: \"xxxxxxxxxxxxx\"" -j CNI-DN-xxx -A CNI-HOSTPORT-SNAT -m comment --comment "snat name": \"cni0\" id: \"xxxxxxxxxxxxx\"" -j CNI-SN-xxx -A CNI-SN-xxx -s 127.0.0.1/32 -d 10.224.0.222/32 -p tcp -m tcp --dport 80 -j MASQUERADE -
端口占用。
hostport 是通过 iptables 对请求中的目的端口进行转发的,并不是在主机上通过端口监听。
-
应用调度。
使用 hostPort 的应用在调度时无法调度在已经使用过相同 hostPort 的主机上,也就是说,在调度时会考虑 hostport。
-
创建相同的 nodeport。
使用相同的端口,NodePort 是可以成功创建的,同时监听的端口也出现了。hostPort 通过 portmap 写入的规则排在其之前,所以请求就被转到 hostport 所在的 pod 中。
2021-07-05~11
Rootless containers
runc 具有运行没有root权限的容器。 这被称为无根的。 您需要将一些参数传递给RUNC以运行无源容器。 请参阅下面并与以前的版本进行比较。
echo 28633 > /proc/sys/user/max_user_namespaces
mkdir ~/mycontainer && cd ~/mycontainer
mkdir rootfs
# 镜像的 rootfs
docker export $(docker create busybox) | tar -C rootfs -xvf -
# 生成runc的配置文件
runc spec --rootless
# 启动
runc --root /tmp/runc run --pid-file /run/mycontainerid.pid mycontainerid
# 关闭
runc delete mycontainerid
https://github.com/opencontainers/runc
2021-06-28~04
基于XFS文件系统的 overlayfs 下使用 docker,为何要使用 d_type=1
什么是 overlayfs
首先,overlayfs 是一种文件系统,也是目前 dokcer 在使用的最新的文件系统,其他的文件系统还有:aufs、device mapper等。而 overlayfs 其实和 aufs 是类似的。更准确的说,overlayfs 其实是 Linux 文件系统的一种上层文件系统。下面的底层的文件系统格式,支持overlayfs的:
-
ext4
-
xfs(必须在格式化为xfs的时候指定ftype=1,如果在未使用ftype=1的方式格式化的xfs文件系统上使用,否则docker可能出现未知问题)
xfs 文件系统的 d_type 是什么?
d_type 是 Linux 内核的一个术语,表示 “目录条目类型”,而目录条目,其实是文件系统上目录信息的一个数据结构。d_type 就是这个数据结构的一个字段,这个字段用来表示文件的类型,是文件,还是管道,还是目录还是套接字等。
d_type 从 Linux 2.6 内核开始就已经支持了,只不过虽然 Linux 内核虽然支持,但有些文件系统实现了 d_type,而有些,没有实现,有些是选择性的实现,也就是需要用户自己用额外的参数来决定是否开启 d_type 的支持。
为什么docker在overlay2(xfs文件系统)需要 d_type
不论是 overlay,还是 overlay2,它们的底层文件系统都是 overlayfs 文件系统。而 overlayfs 文件系统,就会用到 d_type 这个东西来确定文件的操作是被正确的处理了。换句话说,docker只要使用 overlay 或者 overlay2,就等于在用 overlayfs,也就一定会用到 d_type。
相关命令
modprobe overlay # 开启 overlay
lsmod | grep over # 查看当前操作是否支持 overlay
xfs_info / # 查看 xfs 文件系统信息
docker info # 查看 docker 信息
mkfs.xfs -f -n ftype=1 /mount-point # 格式化 xfs 文件系统
https://docs.docker.com/storage/storagedriver/select-storage-driver/
2021-06-21~27
容器 NAT网络出现 INVALID 状态包
现象:
docker 容器内应用上传文件到外部服务时,出现失败,超时等异常, 抓包发现有不停重试发送数据的现象。
原因:
netfilter 会把 out of window 的包标记为 INVALID 状态,源码见 net/netfilter/nf_conntrack_proto_tcp.c
如果是 INVALID 状态的包,netfilter 不会对其做 IP 和端口的 NAT 转换,这样协议栈再去根据 ip + 端口去找这个包的连接时,就会找不到,这个时候就会回复一个 RST。
通过 iptables 的规则,把 invalid 的包打印出来
iptables -A INPUT -m conntrack --ctstate INVALID -m limit --limit 1/sec -j LOG --log-prefix "invalid: " --log-level 7
解决:
-
直接屏蔽
INVALID包iptables -A INPUT -m conntrack --ctstate INVALID -j DROP -
更改内核参数
sysctl -w "net.netfilter.nf_conntrack_tcp_be_liberal=1" # https://www.kernel.org/doc/Documentation/networking/nf_conntrack-sysctl.txt把这个参数值设置为 1 以后,对于窗口外的包,将不会被标记为
INVALID,源码见net/netfilter/nf_conntrack_proto_tcp.c
其他问题:
- 但为什么报文会出现在窗口之外? 网络性能是否有问题?
文章:
https://mp.weixin.qq.com/s/phcaowQWFQf9dzFCqxSCJA https://mp.weixin.qq.com/s/LtgGcS9b8X-TqbfaLfBldQ
2021-06-14~20
修改运行后的 Docker 容器端口
# 1. 关闭 容器
docker stop ${CONTAINER_ID}
# 2. 修改 config.v2.json 文件中的 ExposedPorts
/var/lib/docker/containers/${CONTAINER_ID}/config.v2.json
"ExposedPorts": {
"80/tcp": {}
}
# 3. 修改 hostconfig.json 文件中的 PortBindings
/var/lib/docker/containers/${CONTAINER_ID}/hostconfig.json
"PortBindings": {
"80/tcp": [
{
"HostIp": "",
"HostPort": "80"
}
]
}
# 4. 重启 Docker 服务
systemctl restart docker
# 5. 启动 容器
docker start ${CONTAINER_ID}
2021-06-07~13
命令行基准测试工具
https://github.com/sharkdp/hyperfine
# 基准测试
hyperfine 'sleep 0.3'
# --min-runs 执行运行的次数
hyperfine --min-runs 5 ' sleep 0.2 ' ' sleep 3.2 '
# 预热执行
hyperfine --warmup 3 'grep -R TODO *'
# --prepare 清除硬盘缓存
hyperfine --prepare 'sync; echo 3 | sudo tee /proc/sys/vm/drop_caches' 'grep -R TODO *'
2021-05-31~06
磁盘 IO 相关
内核参数
/sys/block/<device>/queue/max_sectors_kb
# 这是块层允许文件系统请求的最大千字节数。必须小于或等于硬件所允许的最大尺寸。
/sys/block/<device>/queue/nomerges
# 这使用户能够禁用块层中涉及IO合并请求的查找逻辑。默认情况下(0),所有的合并都被启用。当设置为1时,只有简单的一击合并会被尝试。当设置为2时,将不会尝试任何合并算法(包括一击即中或更复杂的树/散列查询)。
/sys/block/<device>/queue/rq_affinity
# 如果这个选项是 "1",块层将把请求的完成迁移到最初提交请求的cpu "组"。对于一些工作负载来说,由于缓存效应,这可以大大减少CPU周期。 对于需要最大限度地分配完成处理的存储配置来说,将该选项设置为 "2 "会迫使完成在请求的cpu上运行(绕过 "组 "聚合逻辑)。
/sys/block/<device>/queue/scheduler
# 读取时,该文件将显示该块设备的当前和可用的IO调度器。当前活动的IO调度器将被置于[]括号内。在这个文件中写入一个IO调度器的名字将把这个块设备的控制权切换到那个新的IO调度器。请注意,在这个文件中写入一个IO调度器的名字将试图加载该IO调度器模块,如果它在系统中还没有存在的话。
/sys/block/<device>/queue/read_ahead_kb
# 在这个块设备上为文件系统预读的最大KB数。
# https://www.kernel.org/doc/Documentation/block/queue-sysfs.txt
监控一下磁盘IO处理过程
blktrace /dev/dm-93
# 使用blkparse查看blktrace收集的日志
253,108 1 1 7.263881407 21072 Q R 128 + 128 [dd]
# 在snap3上请求读取一页(64k每页)
253,108 1 2 7.263883907 21072 G R 128 + 128 [dd]
253,108 1 3 7.263885017 21072 I R 128 + 128 [dd]
253,108 1 4 7.263886077 21072 D R 128 + 128 [dd]
# 提交IO到磁盘
253,108 0 1 7.264883548 3 C R 128 + 128 [0]
# 大约1ms之后IO处理完成
253,108 1 5 7.264907601 21072 Q R 256 + 128 [dd]
# 磁盘处理IO完成之后,dd才开始处理下一个IO
253,108 1 6 7.264908587 21072 G R 256 + 128 [dd]
253,108 1 7 7.264908937 21072 I R 256 + 128 [dd]
253,108 1 8 7.264909470 21072 D R 256 + 128 [dd]
253,108 0 2 7.265757903 3 C R 256 + 128 [0]
# 但是在snap1上则完全不同,上一个IO没有完成的情况下,dd紧接着处理下一个IO
253,108 17 1 5.020623706 23837 Q R 128 + 128 [dd]
253,108 17 2 5.020625075 23837 G R 128 + 128 [dd]
253,108 17 3 5.020625309 23837 P N [dd]
253,108 17 4 5.020626991 23837 Q R 256 + 128 [dd]
253,108 17 5 5.020627454 23837 M R 256 + 128 [dd]
253,108 17 6 5.020628526 23837 Q R 384 + 128 [dd]
253,108 17 7 5.020628704 23837 M R 384 + 128 [dd]
kprobe 相关参数
# ra_trace.sh
#!/bin/bash
if [ "$#" != 1 ]; then
echo "Usage: ra_trace.sh <device>"
exit
fi
echo 'p:do_readahead __do_page_cache_readahead mapping=%di offset=%dx pages=%cx' >/sys/kernel/debug/tracing/kprobe_events
echo 'p:submit_ra ra_submit mapping=%si ra=%di rastart=+0(%di) rasize=+8(%di):u32 rapages=+16(%di):u32' >>/sys/kernel/debug/tracing/kprobe_events
echo 'p:sync_ra page_cache_sync_readahead mapping=%di ra=%si rastart=+0(%si) rasize=+8(%si):u32 rapages=+16(%si):u32' >>/sys/kernel/debug/tracing/kprobe_events
echo 'p:async_ra page_cache_async_readahead mapping=%di ra=%si rastart=+0(%si) rasize=+8(%si):u32 rapages=+16(%si):u32' >>/sys/kernel/debug/tracing/kprobe_events
echo 1 >/sys/kernel/debug/tracing/events/kprobes/enable
dd if=$1 of=/dev/null bs=4M count=1024
echo 0 >/sys/kernel/debug/tracing/events/kprobes/enable
cat /sys/kernel/debug/tracing/trace_pipe&
CATPID=$!
sleep 3
kill $CATPID
IO的预读不再以当前cpu上node上的内存情况来判断:
- https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?id=6d2be915e589b58cb11418cbe1f22ff90732b6ac
https://mp.weixin.qq.com/s/uS7XoIyB4jTHLI0tRaI8gw
2021-05-24~30
校验网站证书
# 新建一个文件夹 github 保存所有的文件
$ mkdir github && cd github
# 首先,我们下载 github.com 发送的证书
$ openssl s_client -connect github.com:443 -showcerts 2>/dev/null </dev/null | sed -n '/-----BEGIN/,/-----END/p' > github.com.crt
# github.com.crt 是 PEM 格式的文本文件
# 打开可以发现里面有两段 -----BEGIN CERTIFICATE----
# 这说明有两个证书,也就是 github.com 把中间证书也一并发过来了
# 接下来我们把两个证书提取出来
$ awk '/BEGIN/,/END/{ if(/BEGIN/){a++}; out="cert"a".tmpcrt"; print >out}' < github.com.crt && for cert in *.tmpcrt; do newname=$(openssl x509 -noout -subject -in $cert | sed -n 's/^.*CN\s*=\s*\(.*\)$/\1/; s/[ ,.*]/_/g; s/__/_/g; s/^_//g;p').pem; mv $cert $newname; done
# 我们得到了两个证书文件
# github_com.pem 和 DigiCert_SHA2_High_Assurance_Server_CA.pem
# 首先,验证 github_com.pem 证书确实
# 是由 DigiCert_SHA2_High_Assurance_Server_CA.pem 签发的
# 提取 DigiCert_SHA2_High_Assurance_Server_CA 的公钥
# 命名为 issuer-pub.pem
$ openssl x509 -in DigiCert_SHA2_High_Assurance_Server_CA.pem -noout -pubkey > issuer-pub.pem
# 查看 github_com.pem 的签名
# 可以看到 hash 算法是 sha256
$ openssl x509 -in github_com.pem -text -noout -certopt ca_default -certopt no_validity -certopt no_serial -certopt no_subject -certopt no_extensions -certopt no_signame
Signature Algorithm: sha256WithRSAEncryption
86:32:8f:9c:15:b8:af:e8:d1:de:08:3a:44:0e:71:20:24:d6:
fc:0e:58:31:cc:aa:b4:ad:1c:d5:0c:c5:af:c4:bb:fe:5f:ac:
90:6a:42:c8:21:eb:25:f1:6b:2c:37:b2:2a:a8:1a:6e:f2:d1:
4f:a6:2f:bc:cf:3a:d8:c1:9f:30:c0:ec:93:eb:0a:5a:dc:cb:
6c:32:1c:60:6e:ec:6e:f8:86:a5:4f:a0:b4:6d:6a:07:4a:21:
58:d0:29:7d:65:8a:c8:da:6a:ba:ab:f0:75:21:33:00:40:6f:
85:c5:13:e6:27:73:6c:ae:ea:e3:96:d0:53:db:c1:21:68:10:
cf:e3:d8:50:b0:14:ec:a9:98:cf:b8:ce:61:5d:3d:a3:6d:93:
34:c4:13:fa:11:66:a3:dd:be:10:19:70:49:e2:04:4d:81:2c:
1f:2e:59:c6:2c:53:45:3b:ee:f6:13:f4:d0:2c:84:6e:28:6d:
e4:e4:ca:e4:48:89:1b:ab:ec:22:1f:ee:12:d4:6c:75:e9:cc:
0b:15:74:e9:6d:9f:db:40:1f:e2:24:85:a3:4b:a4:e9:cd:6b:
c8:77:9f:87:4f:05:73:00:38:a5:23:54:68:fc:a2:3d:bf:18:
19:0e:a8:fd:b9:5e:8c:5c:e8:fc:e4:a2:52:70:ee:79:a7:d2:
27:4a:7a:49
# 提取签名到文件中
$ openssl x509 -in github_com.pem -text -noout -certopt ca_default -certopt no_validity -certopt no_serial -certopt no_subject -certopt no_extensions -certopt no_signame | grep -v 'Signature Algorithm' | tr -d '[:space:]:' | xxd -r -p > github_com-signature.bin
# 使用上级证书的公钥解密签名
$ openssl rsautl -verify -inkey issuer-pub.pem -in github_com-signature.bin -pubin > github_com-signature-decrypted.bin
# 查看解密后的信息
$ openssl asn1parse -inform DER -in github_com-signature-decrypted.bin
0:d=0 hl=2 l= 49 cons: SEQUENCE
2:d=1 hl=2 l= 13 cons: SEQUENCE
4:d=2 hl=2 l= 9 prim: OBJECT :sha256
15:d=2 hl=2 l= 0 prim: NULL
17:d=1 hl=2 l= 32 prim: OCTET STRING [HEX DUMP]:A8AA3F746FE780B1E2E5451CE4383A9633C4399E89AA3637252F38F324DFFD5F
# 可以发现,hash 值是 A8AA...FD5F
# 接下来计算 github_com.pem 的 hash 值
# 提取证书的 body 部分
$ openssl asn1parse -in github_com.pem -strparse 4 -out github_com-body.bin &> /dev/null
# 计算 hash 值
$ openssl dgst -sha256 github_com-body.bin
SHA256(github_com-body.bin)= a8aa3f746fe780b1e2e5451ce4383a9633c4399e89aa3637252f38f324dffd5f
hash 值匹配,我们成功校验了 github.pem 这个证书确实是由 DigiCert_SHA2_High_Assurance_Server_CA.pem 这个证书来签发的。
上面的流程比较繁琐,其实也可以直接让 openssl 来帮我们验证。
$ openssl dgst -sha256 -verify issuer-pub.pem -signature github_com-signature.bin github_com-body.bin
Verified OK
https://cjting.me/2021/03/02/how-to-validate-tls-certificate/
TCP 半连接队列与全连接队列
全连接队列
存储
ESTABLISHED状态的连接, 也称 accepet 队列
可以通过以下计算队列长度
min(somaxconn, backlog)
listen时传入的backlog, 如 nginx 中的 511/proc/sys/net/core/somaxconn,默认为 128
如果全连接队列满了的话:
-
如果设置了
net.ipv4.tcp_abort_on_overflow,那么直接回复 RST,同时,对应的连接直接从半连接队列中删除 -
否则,直接忽略 ACK,然后 TCP 的超时机制会起作用,一定时间以后,Server 会重新发送 SYN/ACK,因为在 Server 看来,它没有收到 ACK
半连接队列
存储
SYN_RCVD状态的连接,也称 SYN 队列
可以通过以下计算队列长度
backlog = min(somaxconn, backlog)
nr_table_entries = backlog
nr_table_entries = min(backlog, sysctl_max_syn_backlog)
nr_table_entries = max(nr_table_entries, 8)
// roundup_pow_of_two: 将参数向上取整到最小的 2^n
// 注意这里存在一个 +1
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1)
max_qlen_log = max(3, log2(nr_table_entries))
max_queue_length = 2^max_qlen_log
3 个参数决定
listen时传入的backlog, 如 nginx 中的 511/proc/sys/net/ipv4/tcp_max_syn_backlog,默认为 1024/proc/sys/net/core/somaxconn,默认为 128
我们假设 listen 传入的 backlog = 511,其他配置都是默认值,我们来计算一下半连接队列的具体长度。
backlog = min(128, 511) = 128
nr_table_entries = 128
nr_table_entries = min(128, 1024) = 128
nr_table_entries = max(128, 8) = 128
nr_table_entries = roundup_pow_of_two(129) = 256
max_qlen_log = max(3, 8) = 8
max_queue_length = 2^8 = 256
最后算出,半连接队列的长度为 256。
当半连接队列溢出时,Server 收到了新的发起连接的 SYN:
-
如果不开启
net.ipv4.tcp_syncookies:直接丢弃这个 SYN -
如果开启
net.ipv4.tcp_syncookies- 如果全连接队列满了,并且
qlen_young(表示目前半连接队列中,没有进行 SYN/ACK 包重传的连接数量。) 的值大于 1:丢弃这个 SYN - 否则,生成 syncookie 并返回 SYN/ACK 包
- 如果全连接队列满了,并且
https://www.cnblogs.com/zengkefu/p/5606696.html
https://www.cnblogs.com/xiaolincoding/p/12995358.html
https://cjting.me/2019/08/28/tcp-queue/
Shell 启动类型
使用如下的命令可以检测当前 Shell 是否是 interactive 的:
[[ $- == *i* ]] && echo 'Interactive shell' || echo 'Non-interactive shell'
而这条命令可以检测 Shell 是否是 login 的:
shopt -q login_shell && echo 'Login shell' || echo 'Non-login shell'
| 测试命令 | 启动文件 | |
|---|---|---|
login + interactive |
SSH 登录以后,输入指令strace -f -e trace=file -o /tmp/login_interactive /bin/bash -l |
- /etc/profile - /etc/profile.d/*- ~/.bash_profile, ~/.bash_login, ~/.profile 按顺序找到的第一个 |
login + non-interactive |
SSH 登录以后,输入指令 bash -l test.sh | - /etc/profile - /etc/profile.d/*- ~/.bash_profile, ~/.bash_login, ~/.profile 按顺序找到的第一个 |
non-login + interactive |
SSH 登录以后,输入 bash or ssh localhost 'echo $-; shopt login_shell' |
- /etc/bash.bashrc - ~/.bashrc |
non-login + non-interactive |
SSH 登录以后,运行 bash test.sh or bash -c 'echo $-; shopt login_shell' |
None |
2021-05-17~23
containerd 镜像下载的过程
接下来以 centos:latest 镜像的拉取过程为例。
-
将镜像名解析成 oci 规范里 descriptor
主要是 HEAD 请求,并且记录下返回中的
Content-Type和Docker-Content-Digest:$ curl -v -X HEAD -H "Accept: application/vnd.docker.distribution.manifest.v2+json, application/vnd.docker.distribution.manifest.list.v2+json, application/vnd.oci.image.manifest.v1+json, application/vnd.oci.image.index.v1+json, */*" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/latest?ns=docker.io ... < HTTP/1.1 200 OK < Date: Mon, 17 May 2021 11:53:29 GMT < Content-Type: application/vnd.docker.distribution.manifest.list.v2+json < Content-Length: 762 < Connection: keep-alive < Docker-Content-Digest: sha256:5528e8b1b1719d34604c87e11dcd1c0a20bedf46e83b5632cdeac91b8c04efc1 -
获取镜像的 list 列表:
$ curl -X GET -H "Accept: application/vnd.docker.distribution.manifest.list.v2+json" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/sha256:5528e8b1b1719d34604c87e11dcd1c0a20bedf46e83b5632cdeac91b8c04efc1 { "manifests":[ { "digest":"sha256:dbbacecc49b088458781c16f3775f2a2ec7521079034a7ba499c8b0bb7f86875", "mediaType":"application\/vnd.docker.distribution.manifest.v2+json", "platform":{ "architecture":"amd64", "os":"linux" }, "size":529 }, { "digest":"sha256:7723d6b5d15b1c64d0a82ee6298c66cf8c27179e1c8a458e719041ffd08cd091", "mediaType":"application\/vnd.docker.distribution.manifest.v2+json", "platform":{ "architecture":"arm64", "os":"linux", "variant":"v8" }, "size":529 }, ... "mediaType":"application\/vnd.docker.distribution.manifest.list.v2+json", "schemaVersion":2 } -
获取特定操作系统上的镜像 manifest。由于宿主机的环境是 linux,所以
containerd会选择适合该平台的镜像进行拉取:$ curl -X GET -H "Accept: application/vnd.docker.distribution.manifest.v2+json" https://mirror.ccs.tencentyun.com/v2/library/centos/manifests/sha256:dbbacecc49b08458781c16f3775f2a2ec7521079034a7ba499c8b0bb7f86875 { "schemaVersion": 2, "mediaType": "application/vnd.docker.distribution.manifest.v2+json", "config": { "mediaType": "application/vnd.docker.container.image.v1+json", "size": 2143, "digest": "sha256:300e315adb2f96afe5f0b2780b87f28ae95231fe3bdd1e16b9ba606307728f55" }, "layers": [ { "mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip", "size": 75181999, "digest": "sha256:7a0437f04f83f084b7ed68ad9c4a4947e12fc4e1b006b38129bac89114ec3621" } ] } -
拉取镜像的 config 和 layers。最后一步就是解析第三步中获取的 manifest,分别再下载镜像的 config 和 layers 就可以。
2021-05-10~16
stdout-buffering
GNU libc (glibc) uses the following rules for buffering:
| Stream | Type | Behavior |
|---|---|---|
| stdin | input | line-buffered |
| stdout (TTY) | output | line-buffered |
| stdout (not a TTY) | output | fully-buffered |
| stderr | output | unbuffered |
https://eklitzke.org/stdout-buffering
LD_PRELOAD
LD_PRELOAD 是 Linux 系统的一个环境变量,它可以影响程序的运行时的链接(Runtime linker),它允许你定义在程序运行前优先加载的动态链接库。
这个功能主要就是用来有选择性的载入不同动态链接库中的相同函数。通过这个环境变量,我们可以在主程序和其动态链接库的中间加载别的动态链接库,甚至覆盖正常的函数库。
https://www.freebuf.com/articles/web/271281.html
2021-04-19~25
磁盘大小计算
因为文件系统采用了存储单元的二进制定义,而硬盘驱动器制造商采用了十进制定义。所以大家看到实际使用空间与硬盘标注空间不同。
| 十进制定义(硬盘制造商采用): | 二进制定义(由文件系统采用): |
|---|---|
| 1 TB = 1000 GB; 1 GB = 1000 MB; 1 MB = 1000 KB; 1 KB=1000 Bytes | 1 TB = 1024 GB; 1 GB = 1024 MB; 1 MB = 1024 KB; 1 KB=1024 Bytes |
| 相对大小: 1 TB = 10004 Bytes and 1 GB = 10003 Bytes. | 相对大小: 1 TB = 10244 Bytes and 1 GB = 10243 Bytes. |
单块硬盘实际可用存储简单计算
| 硬盘原始存储 | 实际可用空间 |
|---|---|
| 500GB | 500 GB x 1000^3 / 1024^3 = 465 GB |
| 1000GB | 1000 GB x 1000^3 / 1024^3 = 931 GB |
RAID 可用空间计算
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。
| 硬盘原始存储 | 阵列级别 | 别名 | 最少个数 | 实际可用空间 |
|---|---|---|---|---|
| 500GB | 0 | 条带 | 2 | 500 GB x 1000^3 / 1024^3 = 465 GB * 2 |
| 500GB | 1 | 镜像 | 2 | 500 GB x 1000^3 / 1024^3 = 931 GB * 1 |
| 500GB | 5 | 分布奇偶校验条带 | 3 | 500 GB x 1000^3 / 1024^3 = 931 GB * (3-1) |
| 500GB | 6 | 双重奇偶校验条带 | 4 | 500 GB x 1000^3 / 1024^3 = 931 GB * (4-2) |
| 500GB | 10 | 镜像加条带 | 4 | 500 GB x 1000^3 / 1024^3 = 931 GB * (4*50%) |
2021-04-12~18
配置管理中心应该能做到
- 配置项的定义与配置的存储的解耦。比如应用可能会从Nacos中读取,也可以从环境变量里读取。
- 配置项之间的相互引用:消除重复配置项。比如MySQL的连接字符串,可能同时在应用a的配置和应用b的配置中出现。
- 配置项版本化:配置项变更跟踪;
- 配置项的定义与配置的格式的解耦。比如同一个配置项在应用a使用的是XML格式,但是应用b使用的是YAML格式。
- 配置项的自动化校验:当用户引入一个错误的配置项时,我们应该可以知道。
- 配置项的作用域功能。
- 配置项分组功能:比如按环境对配置项进行分组。
- 配置项加密功能。
https://mp.weixin.qq.com/s/aY5c4K5qkmU4X1lqXFZXRA
watchdog
watchdog的主要功能是检查系统是否仍在响应(例如,保持活动消息)。假设系统陷入内核崩溃,watchdog 将在达到宽限期后自动重启。 因此,根本不需要通过拔下电源适配器进行手动重启。
加载 watchdog
root@debian:~# modprobe softdog
root@debian:~# ls -al /dev/watchdog
crw------- 1 root root 10, 130 4月 12 18:37 /dev/watchdog
初始化 watchdog
echo "." > /dev/watchdog
如果你不发送 V 字符给watchdog或者发出中断语句,系统会在15秒内自动重启。
echo "V" > /dev/watchdog
可编写小脚本来负责系统的监控。
#!/usr/bin/env bash
# Activate watchdog and run periodically a keep-alive
modprobe softdog
while true; do
echo "." > /dev/watchdog
sleep 14
done
也可以用 python 脚本
import os
import time
_ = os.system("modprobe softdog")
watchdog = '/dev/watchdog'
while True:
with open(watchdog, 'w+') as wf: wf.write('.')
time.sleep(14)
还可以使用 watchdog 程序
apt install watchdog -y
cat <<EOF>> /etc/watchdog.conf
max-load-1 = 24
min-memory = 1
watchdog-device = /dev/watchdog
watchdog-timeout = 15
EOF
systemctl start watchdog && systemctl enable watchdog
测试系统异常
# 深水炸弹
: ( ){ : | : & }; :
# 内核恐慌
echo 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
避免 Docker / Kubernetes 的 PID 1 问题
PID 1的问题是,当您运行容器时,应用程序的进程将以PID 1(进程号1)运行,即使将诸如SIGTERM之类的信号发送到容器,容器内部的进程也不会正常结束。以下是如何分别解决截至2020年3月的Docker和Kubernetes的PID 1问题。
-
有两种解决方法:”显式处理信号” 或 “防止其在PID 1上运行”
显式处理信号: 就是让程序自己处理信号,比如使用
CMD ["npm", "start"]启动程序,因为 npm 现在可以显式处理信号。 -
如果要阻止应用程序进程以PID 1运行,则可以使用
Tini之类的轻量级init 或Docker 1.13及更高版本docker run的--init选件来解决Docker的问题。ENV TINI_VERSION v0.19.0 ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini RUN chmod +x /tini ENTRYPOINT ["/tini", "--"] CMD ["/your/program", "-and", "-its", "arguments"]docker run --rm -d --init --name node-hello docker.io/superbrothers/node-hello -
Kubernetes可以通过使用Pod
shareProcessNamespace解决此问题cat <<EOL | kubectl apply -f- apiVersion: v1 kind: Pod metadata: name: node-hello spec: shareProcessNamespace: true containers: - name: node-hello image: docker.io/superbrothers/node-hello EOL
2021-04-05~11
k8s 指定用于输出日志的容器
如果pod包含多个容器kubectl logs,运行命令将导致错误,要求您选择一个容器,如下所示:
$ kubectl logs nginx
error: a container name must be specified for pod nginx, choose one of: [app sidecar]
kubectl logs使用--container(-c)标志在命令中指定目标容器。
$ kubectl logs nginx --container app
但是,对于主容器和sidecar容器配置,大多数情况下您可能希望查看的日志是主容器的日志。每次必须指定它也是麻烦的。
从Kubernetes 1.18中的kubectl开始,您现在可以指定默认容器来记录带有kubectl.kubernetes.io/default-logs-container注释的kubectl logs命令。
例如,以下Pod清单,app并sidecar包含两个容器。
apiVersion: v1
kind: Pod
metadata:
name: nginx
annotations:
kubectl.kubernetes.io/default-logs-container: app
spec:
containers:
- name: app
image: nginx
- name: sidecar
image: busybox
command:
- sh
- -c
- 'while true; do echo $(date); sleep 1; done'
kubectl.kubernetes.io/default-logs-container由于app指定kubectl logs了注释,因此在执行命令时将app选择容器,而不指定容器,如下所示。
$ kubectl logs nginx
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
https://github.com/kubernetes/kubernetes/pull/87809
k8s get all
kubectl get all 只显示以下资源
$ kubectl get --raw /apis | jq -r '.groups[].versions[] | "/apis/"+.groupVersion' | cat <(echo /api/v1) - | xargs -I{} kubectl get --raw {} | jq -r '.groupVersion as $groupVersion | .resources[] | if (.categories | type == "array" and contains(["all"])) then .name + "." + $groupVersion else empty end' | sed -e 's/\/.*$//g' | sort | uniq
cronjobs.batch
daemonsets.apps
deployments.apps
horizontalpodautoscalers.autoscaling
jobs.batch
pods.v1
replicasets.apps
replicationcontrollers.v1
services.v1
statefulsets.apps
- Kubernetes API具有一个
Categories别名组,该别名组与称为以下资源的资源相关联
all默认情况下是否定义了一个别名组CustomResourceDefinition允许spec.names.categories []string您使用以下命令为自定义资源设置任何类别
- 换句话说,您可以创建自己喜欢的任何类别,也可以向该
all类别添加任何自定义资源。
但我们想要获取所有的资源信息。
可以通过获取先所有 api-resources 资源名称,然后在获取对应的资源信息。
$ kubectl get "$(kubectl api-resources --namespaced=true --verbs=list --output=name | tr "\n" "," | sed -e 's/,$//')"
还可以添加到 kubelet plugin,方便我们使用。
cat <<'EOF' > /usr/bin/kubectl-get_all
#!/usr/bin/env bash
set -e -o pipefail; [[ -n "$DEBUG" ]] && set -x
exec kubectl get "$(kubectl api-resources --namespaced=true --verbs=list --output=name | tr "\n" "," | sed -e 's/,$//')" "$@"
EOF
chmod +x /usr/bin/kubectl-get_all
就可以通过命令 kubectl get-all 方便的获取所有资源信息
# 获取所有资源信息
$ kubectl get-all
# 获取 kube-system 命名空间的所有资源信息
$ kubectl get-all -n kube-system
2021-03-29~04
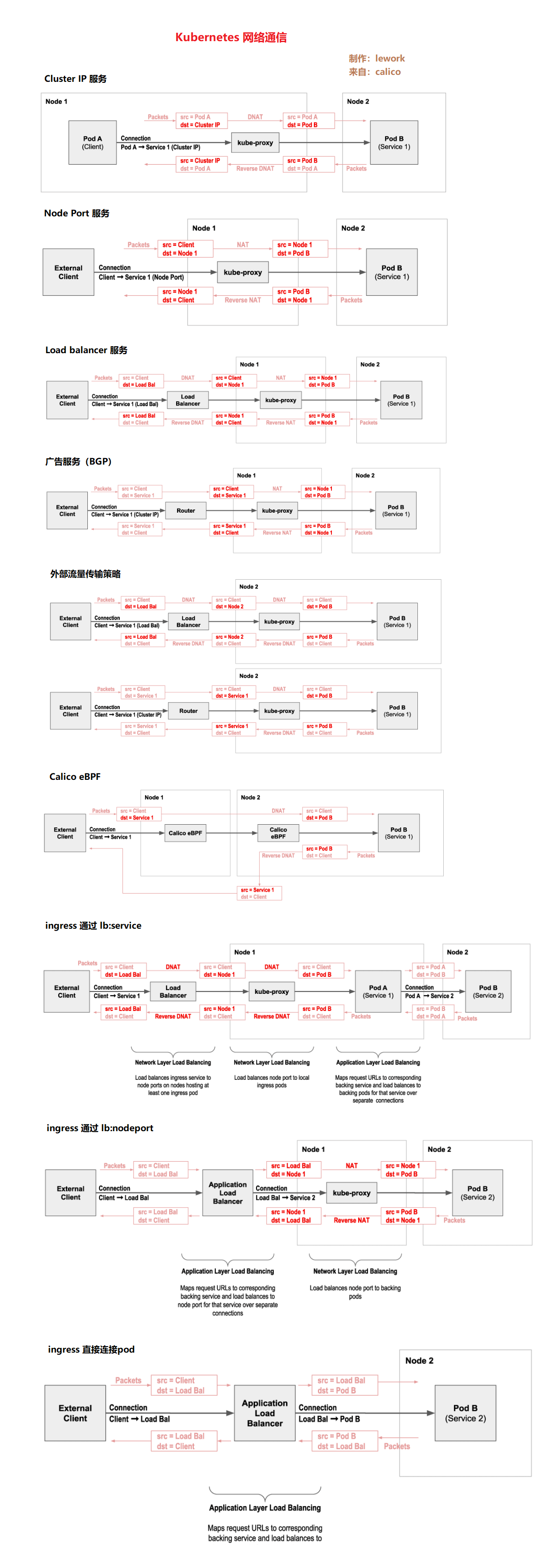
kubenetres network
2021-03-22~28
kubeadm 接口信息
https://pkg.go.dev/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2
k8s.gcr.io 镜像下载
#[直接代理]
echo '104.16.161.131 k8sgcr.lework.workers.dev' >> /etc/hosts
docker pull k8sgcr.lework.workers.dev/kube-proxy:v1.20.5
docker tag k8sgcr.lework.workers.dev/kube-proxy:v1.20.5 k8s.gcr.io/kube-proxy:v1.20.5
#[国内镜像]
docker pull registry.cn-hangzhou.aliyuncs.com/kainstall/kube-proxy:v1.20.5
docker tag registry.cn-hangzhou.aliyuncs.com/kainstall/kube-proxy:v1.20.5 k8s.gcr.io/kube-proxy:v1.20.5
2021-03-15~21
k8s 认证方式
证书认证
USER="test"
NAMESPACE="default"
CLUSTER_NAME="kubernetes"
CA="/etc/kubernetes/pki/ca.crt"
CA_KEY="/etc/kubernetes/pki/ca.key"
KUBE_CONFIG="/etc/kubernetes/${USER}.kubeconfig"
KUBE_APISERVER="https://192.168.77.130:6443"
# 证书生成
(umask 077;openssl genrsa -out ${USER}.key 2048)
openssl req -new -key ${USER}.key -out ${USER}.csr -subj "/CN=${USER}"
openssl x509 -req -in ${USER}.csr -CA ${CA} -CAkey ${CA_KEY} -CAcreateserial -out ${USER}.crt -days 365
openssl x509 -in ${USER}.crt -text -noout
# 配置 kubeconfig
kubectl config set-cluster ${CLUSTER_NAME} --certificate-authority=${CA} --embed-certs=true --server=${KUBE_APISERVER} --kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials ${USER} --client-certificate=${USER}.crt --client-key=${USER}.key --embed-certs=true --kubeconfig=${KUBE_CONFIG}
kubectl config set-context ${USER}@${CLUSTER_NAME} --cluster=${CLUSTER_NAME} --user=${USER} --kubeconfig=${KUBE_CONFIG}
kubectl config use-context ${USER}@${CLUSTER_NAME} --kubeconfig=${KUBE_CONFIG}
kubectl config view --kubeconfig=${KUBE_CONFIG}
# RBAC
kubectl create clusterrole pods-read --verb=get,list,watch --resource=pods
kubectl create clusterrolebinding read-all-pods --clusterrole=pods-read --user=test
# GET
kubectl get pods --kubeconfig=${KUBE_CONFIG}
Token认证
USER="test"
NAMESPACE="default"
CLUSTER_NAME="kubernetes"
CA="/etc/kubernetes/pki/ca.crt"
KUBE_CONFIG="/etc/kubernetes/${USER}.kubeconfig"
KUBE_APISERVER="https://192.168.77.130:6443"
# RBAC
kubectl create sa ${USER}
kubectl create clusterrole pods-read --verb=get,list,watch --resource=pods
kubectl create clusterrolebinding read-all-pods --clusterrole=pods-read --serviceaccount=${USER}
# User Token
SECRET=$(kubectl -n ${NAMESPACE} get sa/${USER} --output=jsonpath='{.secrets[0].name}')
JWT_TOKEN=$(kubectl -n ${NAMESPACE} get secret/$SECRET --output=jsonpath='{.data.token}' | base64 -d)
# kubeconfig
kubectl config set-cluster ${CLUSTER_NAME} --certificate-authority=${CA} --embed-certs=true --server=${KUBE_APISERVER} --kubeconfig=${KUBE_CONFIG}
kubectl config set-context ${USER}@${CLUSTER_NAME} --cluster=${CLUSTER_NAME} --user=${USER} --kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials ${USER} --token=${JWT_TOKEN} --kubeconfig=${KUBE_CONFIG}
kubectl config use-context ${USER}@${CLUSTER_NAME} --kubeconfig=${KUBE_CONFIG}
kubectl config view --kubeconfig=${KUBE_CONFIG}
# GET
kubectl get pods --kubeconfig=${KUBE_CONFIG}
2021-03-08~14
linux oom
https://learning-kernel.readthedocs.io/en/latest/mem-management.html
https://man7.org/linux/man-pages/man5/proc.5.html
-
What(什么是OOM):
Linux下面有个特性叫OOM killer(Out Of Memory killer),这个东西会在系统内存耗尽的情况下跳出来,选择性的干掉一些进程以求释放一些内存。具体的记录日志是在/var/log/messages中,如果出现了Out of memory字样,说明系统曾经出现过OOM!
-
When(什么时候出现):
Linux下允许程序申请比系统可用内存更多的内存,这个特性叫Overcommit。这样做是出于优化系统考虑,因为不是所有的程序申请了内存就立刻使用的,当你使用的时候说不定系统已经回收了一些资源了。不幸的是,当你用到这个Overcommit给你的内存的时候,系统还没有资源的话,OOM killer就跳出来了。
参数
/proc/sys/vm/overcommit_memory可以控制进程对内存过量使用的应对策略- 当overcommit_memory=0 允许进程轻微过量使用内存,但对于大量过载请求则不允许,也就是当内存消耗过大就是触发OOM killer。
- 当overcommit_memory=1 永远允许进程overcommit,不会触发OOM killer。
- 当overcommit_memory=2 永远禁止overcommit,不会触发OOM killer。
-
How(系统会怎么样):
当然,如果触发了OOM机制,系统会杀掉某些进程,那么什么进程会被处理掉呢?kernel提供给用户态的/proc下的一些参数:
-
/proc/[pid]/oom_adj,该pid进程被oom killer杀掉的权重,介于[-17,15](具体具体权重的范围需要查看内核确认)之间,越高的权重,意味着更可能被oom killer选中,-17表示禁止被kill掉。其值在修改后,oom_score_adj会一起改变。 /proc/[pid]/oom_score,当前该pid进程的被kill的分数,越高的分数意味着越可能被kill,这个数值是根据oom_adj运算(2ⁿ,n就是oom_adj的值)后的结果, 为0时禁止内核杀死该进程。/proc/[pid]/oom_score_adj不良因素分数,范围[-1000,1000],越高的分数意味着越可能被kill。与oom_adj数值联动。
oom_score是oom_killer的主要参考值, 如果oom_score_adj = -1000或oom_adj = -17,则可以将其从OOM Killer的杀死目标中排除。 -
-
So(我们能做什么):
-
保护我们重要的进程,避免被处理掉
ps -ef | grep app #(获得重要进程的PID) echo -17 > /proc/<PID>/oom_adj #(输入-17,禁止被OOM机制处理) echo -1000 > /proc/<PID>/oom_score_adj #(输入-1000,禁止被OOM机制处理) -
关闭OOM机制(不推荐,如果不启动OOM机制,内存使用过大,会让系统产生很多异常数据)
echo "vm.panic_on_oom=1" >> /etc/sysctl.conf echo "vm.oom-kill = 0" >> /etc/sysctl.conf systcl -p -
增加 swap 内存,提高
/proc/sys/vm/swappiness值,使其使用尽可能的使用swap内存。 -
增加系统内存。
-
优化进程,使其占用内存降低。
-
-
其他
# 打印当前系统上 oom_score 分数最高(最容易被 OOM Killer 杀掉)的进程
printf 'PID\tOOM Score\tOOM Adj\tCommand\n'
while read -r pid comm; do [ -f /proc/$pid/oom_score ] && [ $(cat /proc/$pid/oom_score) != 0 ] && printf '%d\t%d\t\t%d\t%s\n' "$pid" "$(cat /proc/$pid/oom_score)" "$(cat /proc/$pid/oom_score_adj)" "$comm"; done < <(ps -e -o pid= -o comm=) | sort -k 2nr
k8s pod 抓包
-
从容器本身抓取封包
-
kubectl进入容器内部直接执行tcpdump命令# 可以通过ksniff向容器中上传tcpdump命令 wget https://github.com/eldadru/ksniff/releases/download/v1.5.0/ksniff.zip unzip ksniff.zip mv kubectl-sniff static-tcpdump /usr/local/sbin/ chmod +x /usr/local/sbin/kubectl-sniff yum -y install wireshark # 将监听结果传递给tshark kubectl sniff busybox -f "port 80" -o - | tshark -r - -
在
pod中的sidecar container容器上运行tcpdump命令kubectl patch deployment $deployment_name --patch '{"spec": {"template": {"spec": {"containers": [{"name": "debug-netshoot","image": "nicolaka/netshoot", "command": ["sleep","infinity"]}]}}}}' kubectl exec $pod_name default -- tcpdump -vvvn -i eth0 -
与
pod共享命名空间的docker container容器上运行tcpdump命令pause_id=$(docker ps | grep $pod_name | grep pause | awk '{print $1}') docker run -it --rm --net=container:$pause_id --entrypoint /usr/bin/tcpdump nicolaka/netshoot -vvvn -i eth0 icmp
-
-
从上游精准抓取封包
-
flannel# flannel vxlan方式,可以通过veth接口来抓包 tcpdump -vvv -i vethe281cd54 icmp -
calico# calico 路由,可以通过虚拟网卡来抓包 tcpdump -vvv -i cali60337b1a8c1 icmp
https://www.hwchiu.com/k8s-tcpdump.html
-
在k8s中,什么情况下会出现相同的pod ip?
pod使用node网络的时候-
kubelet不负责pod ip的分配,而是通过cni获取pod的ip地址,而cni标准默认通过host-local方式将pod ip信息存储在/var/lib/cni/networks/目录中。所以,当我们人为或意外的情况下删除/var/lib/cni/networks目录,这时拥有ip的pod还在运行,并重启了kubelet,那么新pod调度此节点时,会有重复分配ip的情况出现。其他信息:
-
/etc/cni/cni插件配置目录 -
/var/lib/cni/flannel/flannel数据目录 -
/var/lib/cni/networks/host-local数据目录 -
/var/run/flannel/flannel运行目录 -
代码: https://github.com/containernetworking/plugins/blob/master/plugins/ipam/host-local/backend/disk/backend.go#L31
-
清除不存在的 pod 的 ip
cd /var/lib/cni/networks/cbr0 for hash in $(tail -n +1 * | egrep '^[A-Za-z0-9]{64,64}$'); do if [ -z $(docker ps --no-trunc | grep $hash | awk '{print $1}') ]; then grep -ilr $hash ./ | xargs rm fi; done
-
2021-03-01~07
nsenter 使用
# 进入docker 容器命名空间
PID=$(docker inspect --format {{.State.Pid}} <container_name_or_ID>)
nsenter -m -u -i -n -p -t $PID <command>
nsenter -a -t $PID <command> # 有的版本不一定有 -a 这个参数
# 参数
# -a, --all enter all namespaces of the target process by the default /proc/[pid]/ns/* namespace paths.
# -t, --target <pid> target process to get namespaces from
# -m, --mount[=<file>] enter mount namespace
# -u, --uts[=<file>] enter UTS namespace (hostname etc)
# -i, --ipc[=<file>] enter System V IPC namespace
# -n, --net[=<file>] enter network namespace
# -p, --pid[=<file>] enter pid namespace
# -U, --user[=<file>] enter user namespace
lsns -p $PID # 列出与给定进程相关联的名称空间。
# 进入 network 命名空间
nsenter -t $PID -n ip a s
# 进入 process 命名空间
nsenter -t $PID -p ps -ef
# 进入 UTC 命名空间
nsenter -t 7172 -u hostname
# 进入所有命名空间
nsenter -t 7172 -a
MySQL 索引长度限制
错误现象
Specified key was too long; max key length is 767 bytes
原因
由于索引前缀限制,将发生此错误。
-
在5.7之前的MySQL版本中,
InnoDB表的前缀限制为767个字节。MyISAM表的长度为1,000字节。 -
在MySQL 5.7及更高版本中,此限制已增加到3072字节。
https://dev.mysql.com/doc/refman/8.0/en/innodb-limits.html
编码限制
INNODB utf8 VARCHAR(255) # UTF8(每个字符使用3个字节)的限制为767/3 = 255个字符,
INNODB utf8mb4 VARCHAR(191) # UTF8mb4(每个字符使用4个字节),则为767/4 = 191个字符。
解决
可以通过以下方式解除限制
-
使用存储更小的编码,比如
latin-1(每个字符使用1个字节), 可以使用下面语句可以转换-- 查看系统编码 SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; -- 转换库的编码 ALTER DATABASE #{database_name} CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; -- 转换表编码 ALTER TABLE #{table_name} CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -- 转换字段 -- For VARCHAR columns that have lengths between 1 and 255: ALTER TABLE #{table_name} CHANGE #{column_name} #{column_name]} VARCHAR(#{column_length}) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci -- For TEXT columns that have the lengths smaller than 65535/4: ALTER TABLE #{table_name} CHANGE #{column_name} #{column_name]} TEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci -- For TEXT columns that have the lengths greater than 65535/4: ALTER TABLE #{table_name} CHANGE #{column_name} #{column_name]} MEDIUMTEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci -- For TEXT columns that have the lengths smaller than 65535/4: ALTER TABLE #{table_name} CHANGE #{column_name} #{column_name]} TEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci -- For TEXT columns that have the lengths greater than 65535/4: ALTER TABLE #{table_name} CHANGE #{column_name} #{column_name]} MEDIUMTEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci -
限制
vachar的索引长度比较推荐这种
-- 只使用字段的前10个字符索引 CREATE INDEX part_of_name ON customer (name(10)); -
扩大索引长度,最长为3072
为什么是3072,因为是基于
InnoDB16KB 页面大小的 3072 字节限制。-- 开启 innodb 大前缀 set global innodb_large_prefix=on; -- 设置innodb 表单独存放 set global innodb_file_per_table=on; -- innodb 文件格式 set global innodb_file_format=Barracuda; -- 设置默认存储引擎 SET global default_storage_engine = 'InnoDB'; -- 查看当前配置 SHOW VARIABLES LIKE "%innodb_large_prefix%"; SHOW VARIABLES LIKE "%innodb_file_per_table%"; SHOW VARIABLES LIKE "%innodb_file_format%"; SHOW VARIABLES LIKE "%default_storage_engine%"; -- 转换数据表行格式为动态 ALTER TABLE #{table_name} ROW_FORMAT=DYNAMIC;my.cnf配置[client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci innodb_large_prefix=on innodb_file_per_table=on innodb_file_format=Barracuda default_storage_engine = InnoDB
2021-02-22~28
k8s api server 限流
- MaxInFlightLimit,server级别整体限流
- Client限流
- EventRateLimit, 限制event
- APF,更细力度的限制配置
https://qingwave.github.io/k8s-rate-limit/
Ingress获取真实IP
-
use-forwarded-headers
kind: ConfigMap apiVersion: v1 metadata: name: nginx-configuration data: compute-full-forwarded-for: 'true' use-forwarded-headers: 'true' -
使用 real_ip_header
kind: ConfigMap apiVersion: v1 metadata: name: nginx-configuration data: http-snippet: | real_ip_header X-Forwarded-For; -
golang中获取真实ip
func RemoteIP(r *http.Request) string { // ingress 行为,将真实ip放到header `X-Original-Forwarded-For`, 普通nginx可去掉此条 ip := strings.TrimSpace(strings.Split(r.Header.Get("X-Original-Forwarded-For"), ",")[0]) if ip != "" { return ip } ip = strings.TrimSpace(strings.Split(r.Header.Get("X-Forwarded-For"), ",")[0]) if ip != "" { return ip } ip = strings.TrimSpace(r.Header.Get("X-Real-Ip")) if ip != "" { return ip } if ip, _, err := net.SplitHostPort(strings.TrimSpace(r.RemoteAddr)); err == nil { return ip } return "" }
快速进入容器命名空间
function e() {
# 快速进入容器命名空间
# exp: e POD_NAME NAMESPACE
set -eu
pod_name=${1}
ns=${2-"default"}
host_ip=$(kubectl -n $ns get pod $pod_name -o jsonpath='{.status.hostIP}')
container_id=$(kubectl -n $ns describe pod $pod_name | grep -A10 "^Containers:" | grep -Eo 'docker://.*$' | head -n 1 | sed 's/docker:\/\/\(.*\)$/\1/')
container_pid=$(docker inspect -f {{.State.Pid}} $container_id)
cmd="nsenter -n --target $container_pid"
echo "entering pod netns for [${host_ip}] $ns/$pod_name"
echo $cmd
$cmd
}
保留Exit Code
| Exit Code Number | Meaning | Example | Comments |
|---|---|---|---|
1 |
Catchall for general errors | let “var1 = 1/0” | Miscellaneous errors, such as “divide by zero” and other impermissible operations |
2 |
Misuse of shell builtins (according to Bash documentation) | empty_function() {} | Missing keyword or command, or permission problem (and diff return code on a failed binary file comparison). |
126 |
Command invoked cannot execute | /dev/null | Permission problem or command is not an executable |
127 |
“command not found” | illegal_command | Possible problem with $PATH or a typo |
128 |
Invalid argument to exit | exit 3.14159 | exit takes only integer args in the range 0 - 255 (see first footnote) |
128+n |
Fatal error signal “n” | kill -9 $PPID of script |
**$?** returns 137 (128 + 9) |
130 |
Script terminated by Control-C | Ctl-C | Control-C is fatal error signal 2, (130 = 128 + 2, see above) |
255* |
Exit status out of range | exit -1 | exit takes only integer args in the range 0 - 255 |
- 状态码需在0 - 255之间。0表示正常退出。
- 若因外界中断导致程序退出,则状态码区间为129 - 255。例如,操作系统给程序发送中断信号 kill -9 或ctrl+c,导致程序状态变为 SIGKILL 或 SIGINT。
- 通常因程序自身原因导致的异常退出,状态码区间在1 - 128。
- 在某些场景下,也允许程序设置使用129 - 255区间的状态码。
- 若指定的退出状态码不在0 - 255之间(例如,设置 exit(-1)),此时将会自动执行转换,最终呈现的状态码仍会在0 - 255之间。
Pod异常状态的常见原因
- Pod 一直处于 ContainerCreating 或Waiting 状态
- Pod 配置错误
- 挂载 Volume 失败
- 磁盘空间不足
- 节点内存碎片化
- Limit 设置过小或单位错误
- 拉取镜像失败
- CNI 网络错误
- controller-manager 异常
- 安装 docker 时未完全删除旧版本
- 存在同名容器
- Pod 一直处于 ImagePullBackOff 状态
- HTTP 类型 Registry 地址未加入 insecure-registry
- HTTPS 自签发类型 Registry CA 证书未添加至节点
- 私有镜像仓库认证失败
- 镜像文件损坏镜像
- 拉取超时镜像不存在
- Pod 一直处于 Pending 状态
- 节点资源不足不满足
- nodeSelector 与 affinity
- Node 存在 Pod 没有容忍的污点
- 低版本 kube-scheduler 的 bug
- kube-scheduler 未正常运行
- 驱逐后其他可用节点与当前节点的有状态应用不在相同可用区
- Pod 一直处于 Terminating 状态
- 磁盘空间不足
- 存在 “i” 文件属性
- Docker 17 版本 bug存在 Finalizers
- 低版本 kubelet list-watch 的 bug
- Dockerd 与 containerd 状态不同步
- Daemonset Controller Bug
- Pod 健康检查失败
- 健康检查配置不合理
- 节点负载过高
- 容器进程被木马进程停止
- 容器内进程端口监听故障
- SYN backlog 设置过小
- Pod 处于 CrashLoopBackOff 状态
- 容器进程主动退出
- 系统 OOM
- cgroup OOM
- 节点内存碎片化
- 健康检查失败
- 容器进程主动退出
- DNS 无法解析
- 程序配置有误
https://cloud.tencent.com/document/product/457/42945
istio 端到端请求处理流程

2021-02-18~21
Kubernetes api resources

https://twitter.com/iximiuz/status/1353045442087571456
istio网络问题
-
Envoy 启动后会通过 xDS 协议向 pilot 请求服务和路由配置信息,Pilot 收到请求后会根据 Envoy 所在的节点(pod或者VM)组装配置信息,包括 Listener、Route、Cluster等,
- 然后再通过 xDS 协议下发给 Envoy。
- 根据 Mesh 的规模和网络情况,该配置下发过程需要数秒到数十秒的时间。
- 由于初始化容器已经在 pod 中创建了 Iptables rule 规则,因此这段时间内应用向外发送的网络流量会被重定向到 Envoy ,而此时 Envoy 中尚没有对这些网络请求进行处理的监听器和路由规则,无法对此进行处理,导致网络请求失败。
在应用启动命令中判断 Envoy 初始化状态
最直接的解决思路就是:在应用进程启动时判断 Envoy sidecar 的初始化状态,待其初始化完成后再启动应用进程。
Envoy 的健康检查接口 localhost:15020/healthz/ready 会在 xDS 配置初始化完成后才返回 200,否则将返回 503,因此可以根据该接口判断 Envoy 的配置初始化状态,待其完成后再启动应用容器。我们可以在应用容器的启动命令中加入调用 Envoy 健康检查的脚本,如下面的配置片段所示。在其他应用中使用时,将 start-awesome-app-cmd 改为容器中的应用启动命令即可。
apiVersion: apps/v1
kind: Deployment
metadata:
name: awesome-app-deployment
spec:
selector:
matchLabels:
app: awesome-app
replicas: 1
template:
metadata:
labels:
app: awesome-app
spec:
containers:
- name: awesome-app
image: awesome-app
ports:
- containerPort: 80
command: ["/bin/bash", "-c"]
args: ["while [[ \"$(curl -s -o /dev/null -w ''%{http_code}'' localhost:15020/healthz/ready)\" != '200' ]]; do echo Waiting for Sidecar;sleep 1; done; echo Sidecar available; start-awesome-app-cmd"]
该流程的执行顺序如下:
- Kubernetes 启动 应用容器。
- 应用容器启动脚本中通过
curl get localhost:15020/healthz/ready查询 Envoy sidcar 状态,由于此时 Envoy sidecar 尚未就绪,因此该脚本会不断重试。 - Kubernetes 启动 Envoy sidecar。
- Envoy sidecar 通过 xDS 连接 Pilot,进行配置初始化。
- 应用容器启动脚本通过 Envoy sidecar 的健康检查接口判断其初始化已经完成,启动应用进程。
通过 pod 容器启动顺序进行控制
Kubernetes 会在启动容器后调用该容器的 postStart hook,postStart hook 会阻塞 pod 中的下一个容器的启动,直到 postStart hook 执行完成。因此如果在 Envoy sidecar 的 postStart hook 中对 Envoy 的配置初始化状态进行判断,待完成初始化后再返回,就可以保证 Kubernetes 在 Envoy sidecar 配置初始化完成后再启动应用容器。该流程的执行顺序如下:
- Kubernetes 启动 Envoy sidecar 。
- Kubernetes 执行 postStart hook。
- postStart hook 通过 Envoy 健康检查接口判断其配置初始化状态,直到 Envoy 启动完成 。
- Kubernetes 启动应用容器。
apiVersion: v1
kind: Pod
metadata:
name: sidecar-starts-first
spec:
containers:
- name: istio-proxy
image:
lifecycle:
postStart:
exec:
command:
- pilot-agent
- wait
- name: application
image: my-application
该解决方案对 Kubernetes 有两个隐式依赖条件:
- Kubernetes 在一个线程中按定义顺序依次启动 pod 中的多个容器
- 以及前一个容器的 postStart hook 执行完毕后再启动下一个容器。
这两个前提条件在目前的 Kuberenetes 代码实现中是满足的,但由于这并不是 Kubernetes的 API 规范,因此该前提在将来 Kubernetes 升级后很可能被打破,导致该问题再次出现。
istio 无头服务问题
问题1:
问题现状:从带 Envoy Sidecar 的 Pod 中不能访问 Redis 服务器,但在没有安装 Sidecar 的 Pod 中可以正常访问该 Redis 服务器。
问题原因:问题是由于 Istio 1.6 版本前对 Headless Service 处理的一个 Bug,客户端的 Envoy 采用 mTLS 方式向只支持plain TCP服务器端发起连接, 从而导致无法连接。
解决方式:可以通过创建Destination Rule 禁用 Headless Service 的 mTLS 来规避该问题。
问题2:
问题现状: 在 Spring Cloud 应用迁移到 Istio 中后,服务提供者向 Eureka Server 发送心跳失败。
问题原因: Envoy Cluster 的默认类型为 “ORIGINAL_DST”,该选项表明 Enovy 在转发请求时会直接采用 downstream 原始请求中的地址。在这种情况下,当 Pod 的 IP 变化后,Envoy 并不会立即主动断开和 Client 端的链接。此时从 Client 的角度来看,到 Pod 的 TCP 链接依然是正常的,因此 Client 会继续使用该链接发送 HTTP 请求。同时由于 Cluster 类型为 “ORIGINAL_DST” ,Envoy 会继续尝试连接 Client 请求中的原始目地地址 POD IP。但是由于该 IP 上的 Pod 已经被销毁,Envoy 会连接失败,并在失败后向 Client 端返回一个这样的错误信息:“upstream connect error or disconnect/reset before headers. reset reason: connection failure HTTP/1.1 503” 。
问题解决: Envoy Cluster 类型修改为 EDS (Endopoint Discovery Service),普通服务采用 EDS 服务发现,根据 LB 算法从 EDS 下发的 endpoint 中选择一个进行连接。有状态的应用需要关闭envoy注入,以避免集群同步错误。
kubernetes 中主要使用到的证书
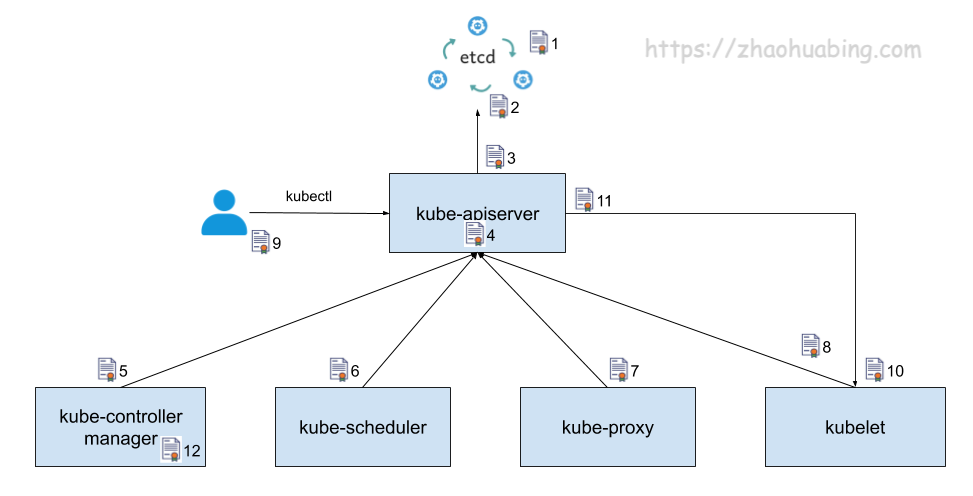 上图中使用序号对证书进行了标注。图中的箭头表明了组件的调用方向,箭头所指方向为服务提供方,另一头为服务调用方。为了实现 TLS 双向认证,服务提供方需要使用一个服务器证书,服务调用方则需要提供一个客户端证书,并且双方都需要使用一个 CA 证书来验证对方提供的证书。为了简明起见,上图中只标注了证书使用方提供的证书,并没有标注证书的验证方验证使用的 CA 证书。图中标注的这些证书的作用分别如下:
上图中使用序号对证书进行了标注。图中的箭头表明了组件的调用方向,箭头所指方向为服务提供方,另一头为服务调用方。为了实现 TLS 双向认证,服务提供方需要使用一个服务器证书,服务调用方则需要提供一个客户端证书,并且双方都需要使用一个 CA 证书来验证对方提供的证书。为了简明起见,上图中只标注了证书使用方提供的证书,并没有标注证书的验证方验证使用的 CA 证书。图中标注的这些证书的作用分别如下:
- etcd 集群中各个节点之间相互通信使用的证书。由于一个 etctd 节点既为其他节点提供服务,又需要作为客户端访问其他节点,因此该证书同时用作服务器证书和客户端证书。
- etcd 集群向外提供服务使用的证书。该证书是服务器证书。
- kube-apiserver 作为客户端访问 etcd 使用的证书。该证书是客户端证书。
- kube-apiserver 对外提供服务使用的证书。该证书是服务器证书。
- kube-controller-manager 作为客户端访问 kube-apiserver 使用的证书,该证书是客户端证书。
- kube-scheduler 作为客户端访问 kube-apiserver 使用的证书,该证书是客户端证书。
- kube-proxy 作为客户端访问 kube-apiserver 使用的证书,该证书是客户端证书。
- kubelet 作为客户端访问 kube-apiserver 使用的证书,该证书是客户端证书。
- 管理员用户通过 kubectl 访问 kube-apiserver 使用的证书,该证书是客户端证书。
- kubelet 对外提供服务使用的证书。该证书是服务器证书。
- kube-apiserver 作为客户端访问 kubelet 采用的证书。该证书是客户端证书。
- kube-controller-manager 用于生成和验证 service-account token 的证书。该证书并不会像其他证书一样用于身份认证,而是将证书中的公钥/私钥对用于 service account token 的生成和验证。kube-controller-manager 会用该证书的私钥来生成 service account token,然后以 secret 的方式加载到 pod 中。pod 中的应用可以使用该 token 来访问 kube-apiserver, kube-apiserver 会使用该证书中的公钥来验证请求中的 token。我们将在文中稍后部分详细介绍该证书的使用方法。
etcd 证书配置
/usr/local/bin/etcd \\
--cert-file=/etc/etcd/kube-etcd.pem \\ # 对外提供服务的服务器证书
--key-file=/etc/etcd/kube-etcd-key.pem \\ # 服务器证书对应的私钥
--peer-cert-file=/etc/etcd/kube-etcd-peer.pem \\ # peer 证书,用于 etcd 节点之间的相互访问
--peer-key-file=/etc/etcd/kube-etcd-peer-key.pem \\ # peer 证书对应的私钥
--trusted-ca-file=/etc/etcd/cluster-root-ca.pem \\ # 用于验证访问 etcd 服务器的客户端证书的 CA 根证书
--peer-trusted-ca-file=/etc/etcd/cluster-root-ca.pem\\ # 用于验证 peer 证书的 CA 根证书
kubeapiserver 证书配置
/usr/local/bin/kube-apiserver \\
--tls-cert-file=/var/lib/kubernetes/kube-apiserver.pem \\ # 用于对外提供服务的服务器证书
--tls-private-key-file=/var/lib/kubernetes/kube-apiserver-key.pem \\ # 服务器证书对应的私钥
--etcd-certfile=/var/lib/kubernetes/kube-apiserver-etcd-client.pem \\ # 用于访问 etcd 的客户端证书
--etcd-keyfile=/var/lib/kubernetes/kube-apiserver-etcd-client-key.pem \\ # 用于访问 etcd 的客户端证书的私钥
--kubelet-client-certificate=/var/lib/kubernetes/kube-apiserver-kubelet-client.pem \\ # 用于访问 kubelet 的客户端证书
--kubelet-client-key=/var/lib/kubernetes/kube-apiserver-kubelet-client-key.pem \\ # 用于访问 kubelet 的客户端证书的私钥
--client-ca-file=/var/lib/kubernetes/cluster-root-ca.pem \\ # 用于验证访问 kube-apiserver 的客户端的证书的 CA 根证书
--etcd-cafile=/var/lib/kubernetes/cluster-root-ca.pem \\ # 用于验证 etcd 服务器证书的 CA 根证书
--kubelet-certificate-authority=/var/lib/kubernetes/cluster-root-ca.pem \\ # 用于验证 kubelet 服务器证书的 CA 根证书
--service-account-key-file=/var/lib/kubernetes/service-account.pem \\ # 用于验证 service account token 的公钥
...
kubeconfig里的证书配置
apiVersion: v1
clusters:
- cluster:
# 用于验证 kube-apiserver 服务器证书的 CA 根证书
certificate-authority-data: ...省略...
server: https://localhost:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: system:kube-controller-manager
name: system:kube-controller-manager@kubernetes
current-context: system:kube-controller-manager@kubernetes
kind: Config
preferences: {}
users:
- name: system:kube-controller-manager
user:
# 用于访问 kube-apiserver 的客户端证书
client-certificate-data: ...省略...
# 客户端证书对应的私钥
client-key-data: ...省略...
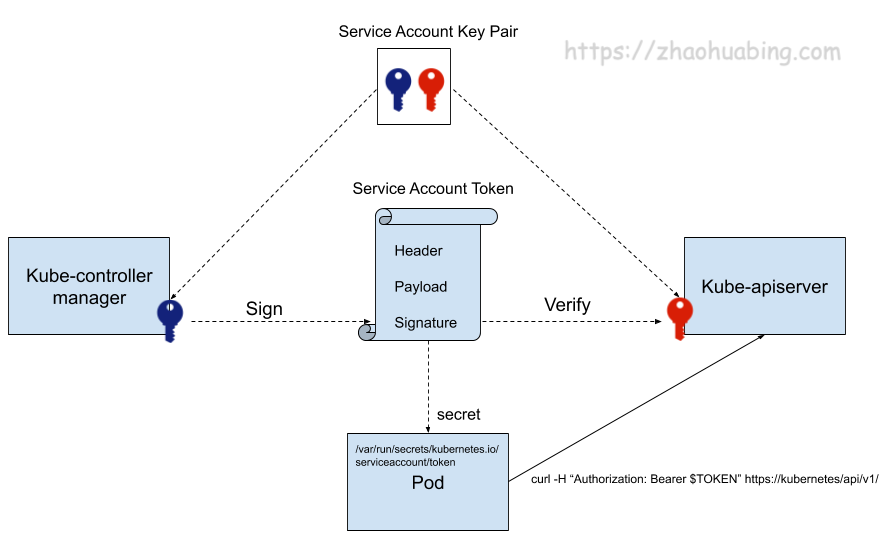
Service Account 证书
service account 主要被 pod 用于访问 kube-apiserver。 在为一个 pod 指定了 service account 后,kubernetes 会为该 service account 生成一个 JWT token,并使用 secret 将该 service account token 加载到 pod 上。pod 中的应用可以使用 service account token 来访问 api server。service account 证书被用于生成和验证 service account token。该证书的用法实际上使用的是其公钥和私钥,而并不需要对证书进行验证。
/usr/local/bin/kube-apiserver \\
--service-account-key-file=/var/lib/kubernetes/service-account.pem \\ # 用于验证 service account token 的公钥
...
/usr/local/bin/kube-controller-manager \\
--service-account-private-key-file=/var/lib/kubernetes/service-account-key.pem # 用于对 service account token 进行签名的私钥
...
下图展示了 kubernetes 中生成、使用和验证 service account token 的过程。
Kubernetes 证书签发
Kubernetes 提供了一个 certificates.k8s.io API,可以使用配置的 CA 根证书来签发用户证书。该 API 由 kube-controller-manager 实现,其签发证书使用的根证书在下面的命令行中进行配置。我们希望 Kubernetes 采用集群根 CA 来签发用户证书,因此在 kube-controller-manager 的命令行参数中将相关参数配置为了集群根 CA。
/usr/local/bin/kube-controller-manager \\
--cluster-signing-cert-file=/var/lib/kubernetes/cluster-root-ca.pem # 用于签发证书的 CA 根证书
--cluster-signing-key-file=/var/lib/kubernetes/cluster-root-ca-key.pem # 用于签发证书的 CA 根证书的私钥
...
使用 TLS bootstrapping 简化 Kubelet 证书制作
Kubernetes 提供了 TLS bootstrapping 的方式来简化 Kubelet 证书的生成过程。其原理是预先提供一个 bootstrapping token,kubelet 采用该 bootstrapping token 进行客户端验证,调用 kube-apiserver 的证书签发 API 来生成 自己需要的证书。要启用该功能,需要在 kube-apiserver 中启用 --enable-bootstrap-token-auth ,并创建一个 kubelet 访问 kube-apiserver 使用的 bootstrap token secret。如果使用 kubeadmin 安装,可以使用 kubeadm token create命令来创建 token。
采用TLS bootstrapping 生成证书的流程如下:
- 调用 kube-apiserver 生成一个 bootstrap token。
- 将该 bootstrap token 写入到一个 kubeconfig 文件中,作为 kubelet 调用 kube-apiserver 的客户端验证方式。
- 通过
--bootstrap-kubeconfig启动参数将 bootstrap token 传递给 kubelet 进程。 - Kubelet 采用bootstrap token 调用 kube-apiserver API,生成自己所需的服务器和客户端证书。
- 证书生成后,Kubelet 采用生成的证书和 kube-apiserver 进行通信,并删除本地的 kubeconfig 文件,以避免 bootstrap token 泄漏风险。
Istio 证书分发流程

- Envoy 向 pilot-agent 发起一个 SDS (Secret Discovery Service) 请求,要求获取自己的证书和私钥。
- Pilot-agent 生成私钥和 CSR (Certificates Signing Request,证书签名请求),向 Istiod 发送证书签发请求,请求中包含 CSR 和该 pod 中服务的身份信息。
- Istiod 根据请求中服务的身份信息(Service Account)为其签发证书,将证书返回给 Pilot-agent。
- Pilot-agent 将证书和私钥通过 SDS 接口返回给 Envoy。
Istio 数据面使用到的所有证书

Nginx Ingress 高并发实践
系统内核调整
-
调大连接队列的大小
进程监听的 socket 的连接队列最大的大小受限于内核参数
net.core.somaxconn,在高并发环境下,如果队列过小,可能导致队列溢出,使得连接部分连接无法建立。backlog 在 linux 上默认为 511。 Nginx 监听 socket 时没有读取 somaxconn,而是有自己单独的参数配置。如下配置server { listen 80 backlog=1024; ...Nginx Ingress Controller 会自动读取 linux的somaxconn 的值作为 backlog 参数写到生成的 nginx.conf 中,所以设置系统内核参数就可以了。
sysctl -w net.core.somaxconn=65535 -
扩大源端口范围
在高并发环境下,端口范围小容易导致源端口耗尽,使得部分连接异常。建议调整为 1024-65535:
sysctl -w net.ipv4.ip_local_port_range="1024 65535" -
TIME_WAIT 复用
如果短连接并发量较高,它所在 netns 中 TIME_WAIT 状态的连接就比较多,而 TIME_WAIT 连接默认要等 2MSL 时长才释放,长时间占用源端口,当这种状态连接数量累积到超过一定量之后可能会导致无法新建连接。
建议给 Nginx Ingress 开启 TIME_WAIT 重用,即允许将 TIME_WAIT 连接重新用于新的 TCP 连接:
sysctl -w net.ipv4.tcp_tw_reuse=1 -
调大最大文件句柄数
Nginx 作为反向代理,对于每个请求,它会与 client 和 upstream server 分别建立一个连接,即占据两个文件句柄,所以理论上来说 Nginx 能同时处理的连接数最多是系统最大文件句柄数限制的一半。
系统最大文件句柄数由
fs.file-max这个内核参数来控制,建议调大:sysctl -w fs.file-max=1048576。
通过 initContainers修改 nginx ingress 容器的内核参数
initContainers:
- name: setsysctl
image: busybox
securityContext:
privileged: true
command:
- sh
- -c
- |
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w fs.file-max=1048576
securityContext:
capabilities:
add:
- SYS_ADMIN
drop:
- ALL
- /bin/sh
- '-c'
- |
mount -o remount rw /proc/sys
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w fs.file-max=1048576
sysctl -w fs.inotify.max_user_instances=16384
sysctl -w fs.inotify.max_user_watches=524288
sysctl -w fs.inotify.max_queued_events=16384
nginx 配置调整
-
调高 keepalive 连接最大请求数
ginx 针对 client 和 upstream 的 keepalive 连接,均有 keepalive_requests 这个参数来控制单个 keepalive 连接的最大请求数,且默认值均为 100。当一个 keepalive 连接中请求次数超过这个值时,就会断开并重新建立连接。通过下列配置,调高默认值。
keepalive_requests 10000 -
调高 keepalive 最大空闲连接数
它的默认值为 320,在高并发下场景下会产生大量请求和连接,而现实世界中请求并不是完全均匀的,有些建立的连接可能会短暂空闲,而空闲连接数多了之后关闭空闲连接,就可能导致 Nginx 与 upstream 频繁断连和建连,引发 TIME_WAIT 飙升。在高并发场景下可以调到 1000.
keepalive 1000 -
调高单个 worker 最大连接数
max-worker-connections控制每个 worker 进程可以打开的最大连接数,默认 16384,在高并发环境建议调高,比如设置到 65536,这样可以让 nginx 拥有处理更多连接的能力。worker_connections 65536
Nginx 全局配置通过 configmap 配置(Nginx Ingress Controller 会 watch 并自动 reload 配置):
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-ingress-controller
# nginx ingress 性能优化: https://www.nginx.com/blog/tuning-nginx/
data:
# nginx 与 client 保持的一个长连接能处理的请求数量,默认 100,高并发场景建议调高。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#keep-alive-requests
keep-alive-requests: "10000"
# nginx 与 upstream 保持长连接的最大空闲连接数 (不是最大连接数),默认 320,在高并发下场景下调大,避免频繁建联导致 TIME_WAIT 飙升。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#upstream-keepalive-connections
upstream-keepalive-connections: "1000"
# 每个 worker 进程可以打开的最大连接数,默认 16384。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#max-worker-connections
max-worker-connections: "65536"
k8s中,什么情况下驱逐会导致服务不可用?
- 服务存在单点故障,所有副本都在同一个节点,驱逐该节点时,就可能造成服务不可用。
- 服务没有单点故障,但刚好这个服务涉及的 Pod 全部都部署在这一批被驱逐的节点上,所以这个服务的所有 Pod 同时被删,也会造成服务不可用。
- 服务没有单点故障,也没有全部部署到这一批被驱逐的节点上,但驱逐时造成这个服务的一部分 Pod 被删,短时间内服务的处理能力下降导致服务过载,部分请求无法处理,也就降低了服务可用性。
针对第一点,我们可以使用反亲和性来避免单点故障。
针对第二和第三点,我们可以通过配置 PDB (PodDisruptionBudget) 来避免所有副本同时被删除,驱逐时 K8S 会 “观察” nginx 的当前可用与期望的副本数,根据定义的 PDB 来控制 Pod 删除速率,达到阀值时会等待 Pod 在其它节点上启动并就绪后再继续删除,以避免同时删除太多的 Pod 导致服务不可用或可用性降低,下面给出两个示例。
示例一 (保证驱逐时 nginx 至少有 90% 的副本可用):
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
示例二 (保证驱逐时 zookeeper 最多有一个副本不可用,相当于逐个删除并等待在其它节点完成重建):
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: zookeeper
k8s 节点升级注意事项
- 在滚动升级的时候,涉及到网络组件,dns组件,istio组件驱逐的时候,会有一段时间访问不可用。
- 没有配置反亲和性的deployment,在配置中断预算后,会导致驱逐失败,从而卡住升级流程。在没有配置中断预算后,会导致服务在一定时间内全部不可用。
- 在没有充足的资源预留,会导致升级节点的pod处于pending状态。
解决办法
- 资源预留充足,保障能接收驱逐节点的pod资源,提前 pull 驱逐节点的镜像资源,减少启动时间。
- 设置关键组件的反亲和性,避免多个pod处于一个节点上。
- 设置关键组件的中断预算,避免服务完全不可用。
- 关键组件手动调度,避免使用驱逐命令统一驱逐。
- dns解析失败,可使用nodelocaldns组件在节点上缓存和代理解析,避免dns pod更换ip时,客户端解析出现异常。
Kafka丢消息的处理
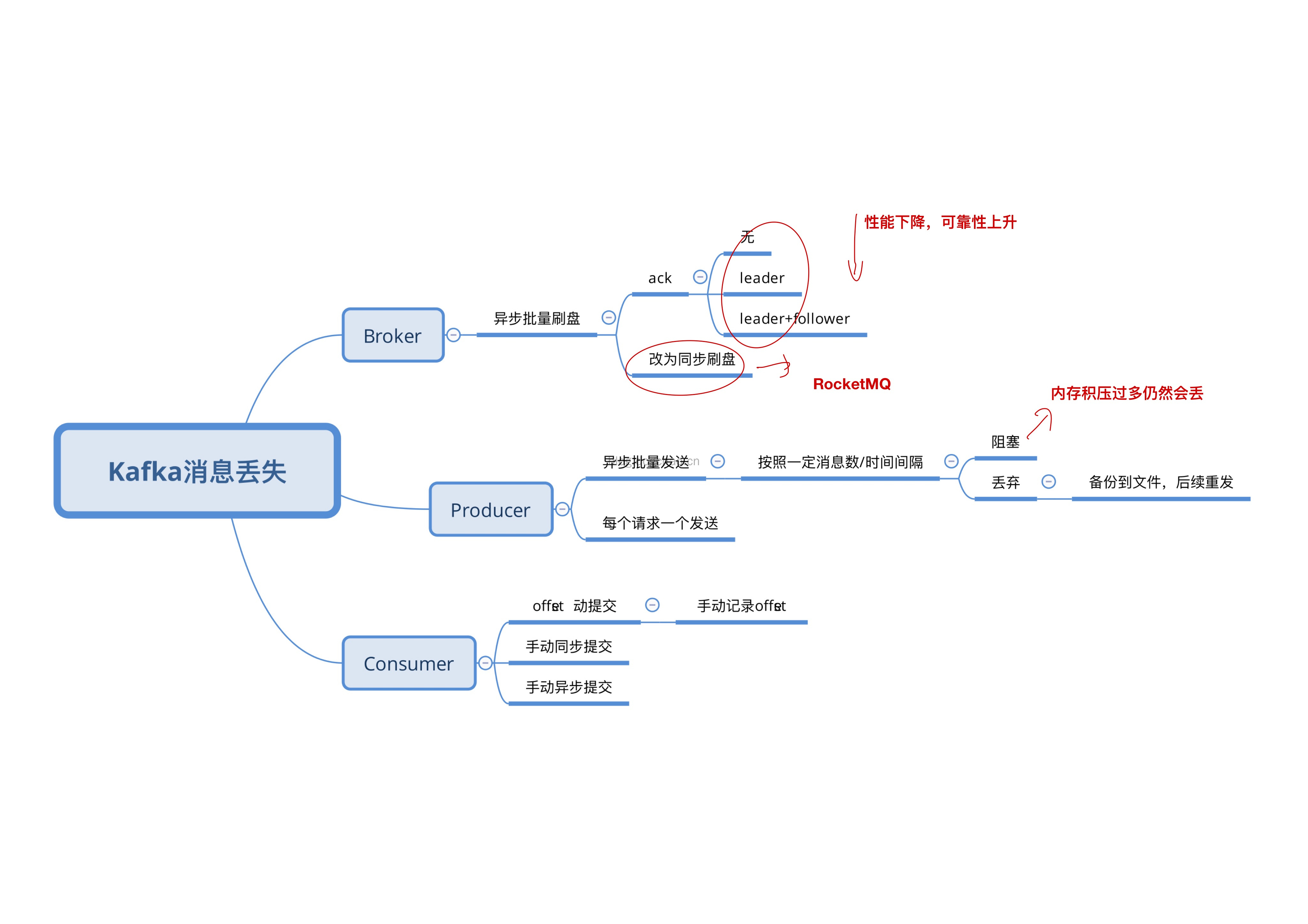
https://blog.dogchao.cn/?p=305
2021-02-01~07
创建一个istio管理的服务
-
通过注入方式创建deployment
cat app.deployment.yaml | istioctl kube-inject -f - | kubectl apply -f - -
创建服务的Service
kubectl apply -f app.service.yaml -
创建网关
kubectl apply -f app.gateway.yaml -
创建istio默认路由
kubectl apply -f app.VirtualService.yaml -
创建客户端负载策略
kubectl apply -f app.DestinationRule.yaml -
查看资源是否创建完成
kubectl get svc,po,vs,dr -
测试应用,对服务发送请求。
curl http://$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')/app/
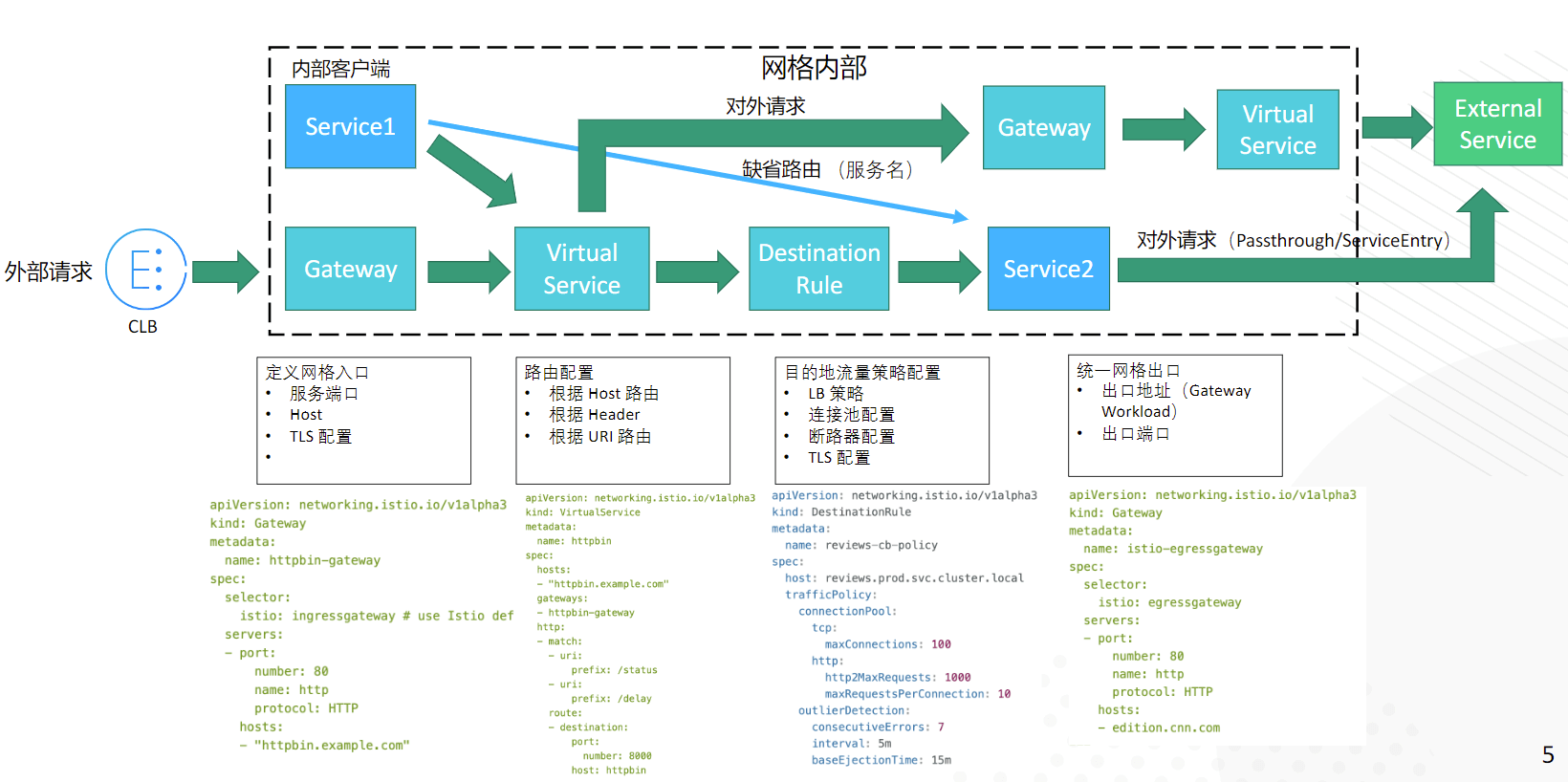
istio注入
sidecar 的注入过程都需要遵循如下步骤:
- Kubernetes 需要了解待注入的 sidecar 所连接的 Istio 集群及其配置;
- Kubernetes 需要了解待注入的 sidecar 容器本身的配置,如镜像地址、启动参数等;
- Kubernetes 根据 sidecar 注入模板和以上配置填充 sidecar 的配置参数,将以上配置注入到应用容器的一侧;
手动注入 sidecar。
i istioctl kube-inject -f ${YAML_FILE} | kuebectl apply -f -
###
流量镜像
复制的流量有些不同点
- host属性值的不同,而区别就是多了一个
“-shadow”的后缀 - x-forwarded-for 多了gateway的ip地址
注入延迟
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- fault:
delay:
percent: 100
fixedDelay: 2s
route:
- destination:
host: ratings
subset: v1
请求延迟
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v2
timeout: 0.5s
重试
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin-retries
spec:
hosts:
- httpbin
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 1s
retryOn: 5xx
如果服务在 1 秒内没有返回正确的返回值,就进行重试,重试的条件为返回码为
5xx,重试 3 次
熔断
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
当并发的连接和请求数超过 1 个,熔断功能将会生效。
故障注入
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings-route
spec:
hosts:
- ratings.prod.svc.cluster.local
http:
- route:
- destination:
host: ratings.prod.svc.cluster.local
subset: v1
fault:
abort:
percentage:
value: 0.1
httpStatus: 400
对
v1版本的ratings.prod.svc.cluster.local服务访问的时候进行故障注入,0.1表示有千分之一的请求被注入故障,400表示故障为该请求的 HTTP 响应码为400
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews-route
spec:
hosts:
- reviews.prod.svc.cluster.local
http:
- match:
- sourceLabels:
env: prod
route:
- destination:
host: reviews.prod.svc.cluster.local
subset: v1
fault:
delay:
percentage:
value: 0.1
fixedDelay: 5s
对
v1版本的reviews.prod.svc.cluster.local服务访问的时候进行延时故障注入,0.1表示有千分之一的请求被注入故障,5s表示reviews.prod.svc.cluster.local延时5s返回
istio api 接口
http://istiod:15000/listeners 监控地址
http://istiod:15000/config_dump 获取配置
# 诊断网格配置
istioctl analyze
istioctl analyze -k --all-namespaces
istioctl analyze -k --all-namespaces --suppress "IST0102=Namespace frod"
# 检查网格中所有配置同步状态
istioctl ps
# 检查 Envoy 和 istiod 间的配置差异
istioctl ps reviews-v3-5f7b9f4f77-ttmhv.default
# 查看指定 pod 的网格配置详情
istioctl pc cluster reviews-v3-5f7b9f4f77-ttmhv.default
istioctl pc cluster reviews-v3-5f7b9f4f77-ttmhv.default --port 9080 --direction inbound -o json
# 验证网格配置
istioctl experimental describe pod details-v1-79c697d759-vlsds.default
istioctl x describe pod details-v1-79c697d759-vlsds.default
xDS API:
| 服务简写 | 全称 | 描述 |
|---|---|---|
| LDS | Listener Discovery Service | 监听器发现服务 |
| RDS | Route Discovery Service | 路由发现服务 |
| CDS | Cluster Discovery Service | 集群发现服务 |
| EDS | Endpoint Discovery Service | 集群成员发现服务 |
| SDS | Service Discovery Service | v1 时的集群成员发现服务,后改名为 EDS |
| ADS | Aggregated Discovery Service | 聚合发现服务 |
| HDS | Health Discovery Service | 健康度发现服务 |
| SDS | Secret Discovery Service | 密钥发现服务 |
| MS | Metric Service | 指标发现服务 |
| RLS | Rate Limit Service | 限流发现服务 |
| xDS | 以上各种 API 的统称 |
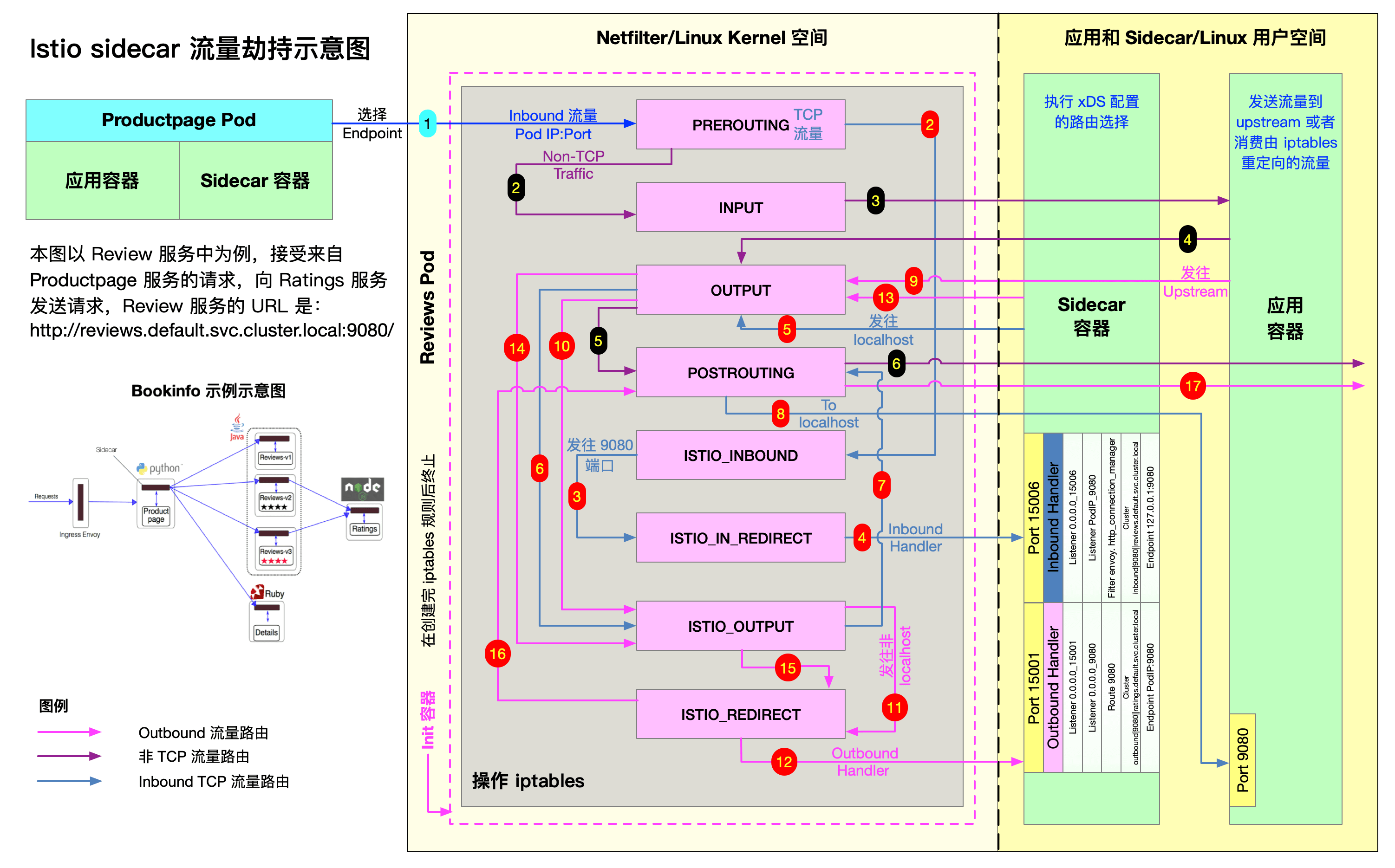
istio sidecar流量劫持
Gateway 是用于控制南北流量的网关,将 VirtualService 绑定到 Gateway 上,可以控制进入的 HTTP/TCP 流量。通过使用 ServiceEntry,可以使网格内部的服务正常发现和路由到外部服务,并在此基础上,结合 VirtualService 实现请求超时、故障注入等功能。
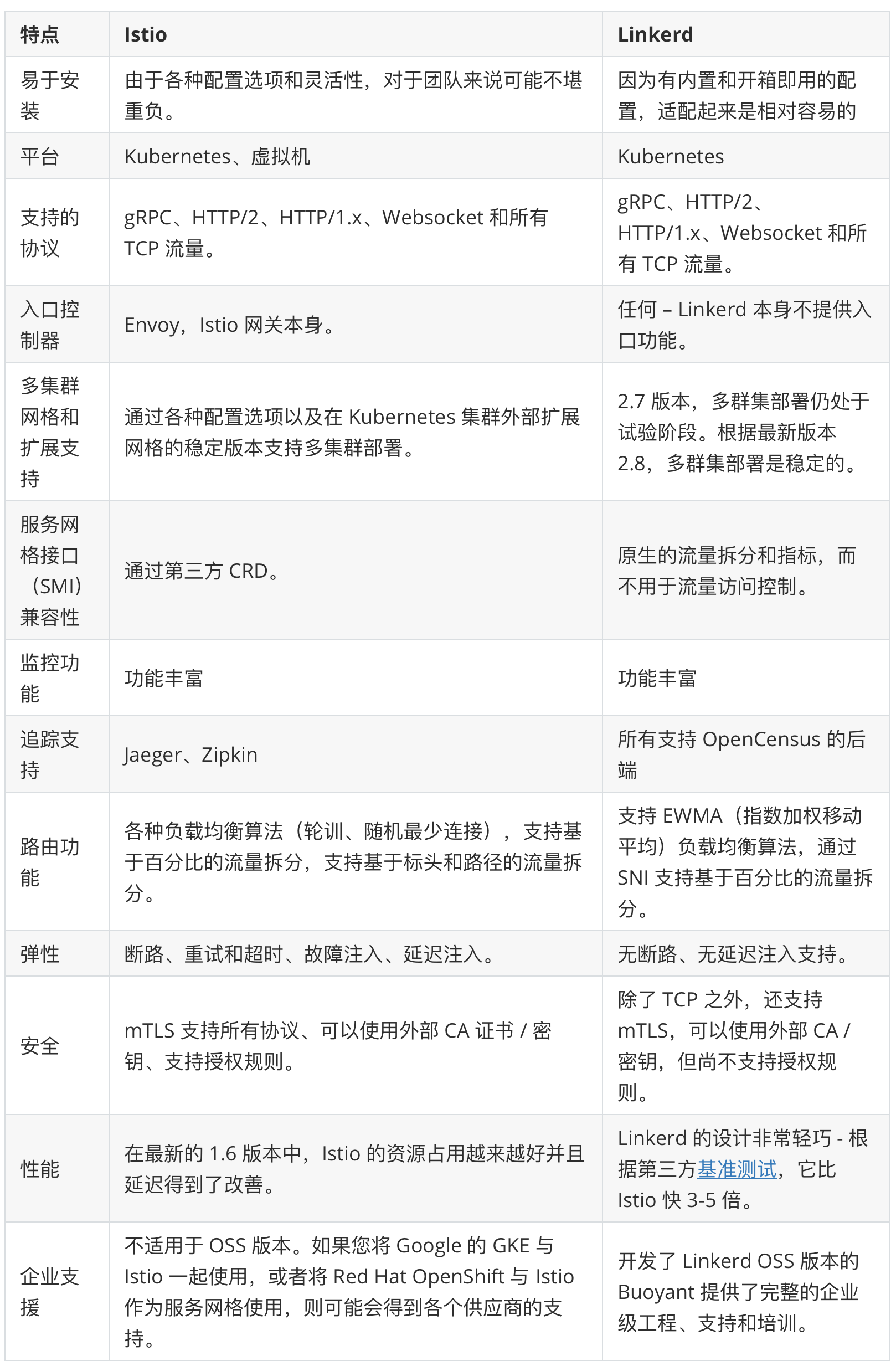
istio 和 linkerd 对比
2021-01-25~31
curl 输出连接时间
curl -L --output /dev/null --silent --show-error \
--write-out 'time_namelookup: %{time_namelookup}\ntime_connect: %{time_connect}\ntime_appconnect: %{time_appconnect}\ntime_pretransfer: %{time_pretransfer}\ntime_redirect: %{time_redirect}\ntime_starttransfer: %{time_starttransfer}\n----------\ntime_total: %{time_total}\n' \
'https://www.baidu.com'
监控指标的制定
在制定监控指标时可以参考以下内容作为指导:
Google SRE 黄金指标(面向用户系统中最重要的衡量因素)
- 延迟(Latency): 延迟是发送请求和接收响应所需的时间。
- 通讯量(Utilization): 监控当前系统的流量,用户衡量服务的容量需求。
- 饱和度(Saturation):衡量当前服务的饱和度。
- 错误(Errors):监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
Weave Cloud RED方法(微服务架构应用的监控和度量)
- (请求)速率(Rate):服务每秒接收的请求数。
- (请求)错误(Errors ):每秒失败的请求数。
- (请求)耗时(Duration):每个请求的耗时。
USE方法(系统性能)
- 使用率(Utilization):关注系统资源的使用情况。 这里的资源主要包括但不限于:CPU,内存,网络,磁盘等等。100%的使用率通常是系统性能瓶颈的标志。
- 饱和度(Saturation):例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于4大黄金信号)。任何资源在某种程度上的饱和都可能导致系统性能的下降。
- 错误(Errors):错误计数。
2021-01-18~24
错误重试
重试:即从新尝试,以观察结果是否符合预期。
常见的重试策略:
-
固定循环次数方式
指定一个错误重试次数,当遇到错误时,不停的重试,直到次数用尽。
这种方式的问题在于:不带backoff 的重试,对于下游来说会在失败发生时进一步遇到更多的请求压力,继而进一步恶化。
-
带固定delay 的方式
在失败之后,进行固定间隔的delay, delay 的方式按照是方法本身是异步还是同步的,可以通过定时器或则简单的Thread.sleep 实现。
这种方式的问题在于:虽然这次带了固定间隔的backoff,但是每次重试的间隔固定,此时对于下游资源的冲击将会变成间歇性的脉冲;特别是当集群都遇到类似的问题时,步调一致的脉冲,将会最终对资源造成很大的冲击,并陷入失败的循环中。
-
带随机delay 的方式
和2 中固定间隔的delay 不一样,现在采用随机backoff 的方式,即具体的delay 时间,在一个最小值和最大值之间浮动。
这种方式的问题在于:虽然现在解决了backoff 的时间集中的问题,对时间进行了随机打散,但是依然存在下面的问题:
- 如果依赖的底层服务持续地失败,改方法依然会进行固定次数的尝试,并不能起到很好的保护作用。
- 对结果是否符合预期,是否需要进行重试依赖于异常。
- 无法针对异常进行精细化的控制,如只针部分异常进行重试
-
可进行细粒度控制的重试
一般这个时候,代码已经相对来说比较复杂了,个人推荐使用resilience4j-retr y 或则spring-retry 等库来进行组合,减少自己编写时维护成本,比如以resilience4j-retry 为例,其可以使用配置代码对重试策略进行细粒度的控制
这种方式的问题在于:虽然可以比较好的控制重试策略,但是对于下游资源持续性的失败,依然没有很好的解决。当持续的失败时,对下游也会造成持续性的压力。一般这种问题的解法,我们日常工作中都是通过一个开关来进行人工断路,另一个比较好的解法是和断路器结合。
-
和断路器结合
在应用断路器时,需要对下游资源的每次调用都通过断路器,对代码具备一定的结构侵入性。 常见的有Hystrix 或resilience4j
当断路器处于开断状态时,所有的请求都会直接失败,不再会对下游资源造成冲击,并能够在一段时间后,进行探索式的尝试,如果没有达到条件,可以自动地恢复到之前的闭合状态。
重试的一些其他实现
对失败做出反应
在反应式宣言中,也有提到,对对失败做出反应,系统在遇到失败时,可以恢复,并隔离失败的组件,而不是不受控的失败。系统是否具备回弹性,对于线上正常安全生产有很大的影响。正确地实现“重试”,只是整个大图中非常小的一环,实际生产中还需要从架构、生产流程、编码细节处理,监控报警等多种手段入手。
失败(和“错误”相对照)
失败是一种服务内部的意外事件, 会阻止服务继续正常地运行。失败通常会阻止对于当前的、并可能所有接下来的客户端请求的响应。和错误相对照, 错误是意料之中的,并且针各种情况进行了处理( 例如, 在输入验证的过程中所发现的错误), 将会作为该消息的正常处理过程的一部分返回给客户端。而失败是意料之外的, 并且在系统能够恢复至(和之前)相同的服务水平之前,需要进行干预。这并不意味着失败总是致命的(fatal), 虽然在失败发生之后, 系统的某些服务能力可能会被降低。错误是正常操作流程预期的一部分, 在错误发生之后, 系统将会立即地对其进行处理, 并将继续以相同的服务能力继续运行。失败的例子有:硬件故障、由于致命的资源耗尽而引起的进程意外终止,以及导致系统内部状态损坏的程序缺陷。
回弹性
回弹性是通过复制、遏制、隔离以及委托来实现的。失败的扩散被遏制在了每个组件内部, 与其他组件相互隔离,从而确保系统某部分的失败不会危及整个系统,并能独立恢复。每个组件的恢复都被委托给了另一个(外部的)组件, 此外,在必要时可以通过复制来保证高可用性。(因此)组件的客户端不再承担组件失败的处理。
CDN 工作原理
内容分发网络(Content Delivery Network,简称CDN)是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。
CDN 应用广泛,支持多种行业、多种场景内容加速,例如:图片小文件、大文件下载、视音频点播、直播流媒体、全站加速、安全加速。
简单介绍CDN 的工作原理:
- 当终端用户(北京)向www.a.com 下的指定资源发起请求时,首先向LDNS(本地D NS)发起域名解析请求。
- LDNS 检查缓存中是否有www.a.com 的IP 地址记录。如果有,则直接返回给终端用户; 如果没有,则向授权DNS 查询。
- 当授权DNS 解析www.a.com 时,返回域名CNAME www.a.tbcdn.com 对应IP 地址。
- 域名解析请求发送至阿里云DNS 调度系统,并为请求分配最佳节点IP 地址。
- LDNS 获取DNS 返回的解析IP 地址。
- 用户获取解析IP 地址。
- 用户向获取的IP 地址发起对该资源的访问请求。
- 如果该IP 地址对应的节点已缓存该资源,则会将数据直接返回给用户
- 如果该IP 地址对应的节点未缓存该资源,则节点向源站发起对该资源的请求。获取资 源后,结合用户自定义配置的缓存策略,将资源缓存至节点,并返回给用户,请求结束。
淘宝图片空间和CDN 的架构
淘宝整个图片的访问链路有三级缓存(客户端本地、CDN L1、CDN L2),所有图片都持久化的存储到OSS 中。真正处理图片的是img-picasso 系统,它的功能比较复杂,包括从OSS 读取文件,对图片尺寸进行缩放,编解码,所以机器成本比较高。
CDN 的缓存分成2 级,合理的分配L1 和L2 的比例,一方面,可以通过一致性hash 的手段,在同等资源的情况下,缓存更多内容,提升整体缓存命中率;另一方面,可以平衡计算和O,IO,充分利用不同配置的机器的能力。
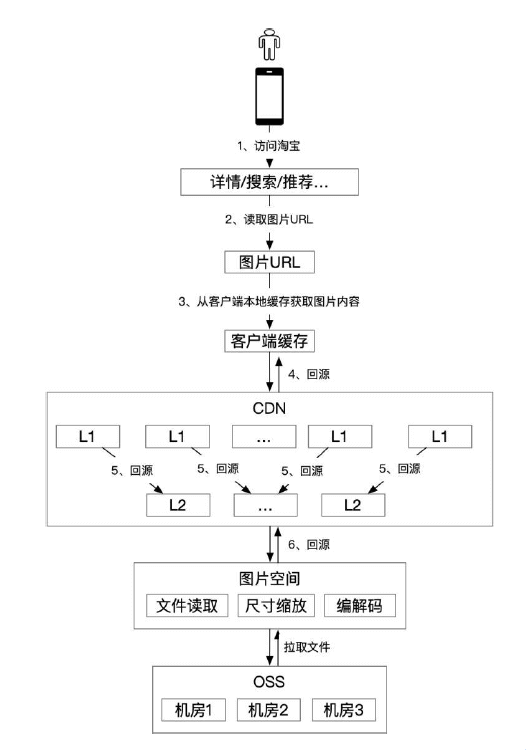
用户访问图片的过程如下:
- 用户通过手机淘宝来搜索商品或者查看宝贝详情。
- 详情/搜索/推荐通过调用商品中心返回商品的图片URL。
- 客户端本地如果有该图片的缓存,则直接渲染图片,否则执行下一步。
- 从CDN L1 回源图片,如果L1 有该图片的缓存,则客户端渲染图片,同时缓存到本地,如果L1 没有缓存,则执行下一步。
- 从CDN L2 回源图片,如果L2 有该图片的缓存,则客户端渲染图片,同时CDN L1 及客户端缓存图片内容,如果CDN L2 没有缓存该图片,则执行下一步。
- 从图片空间回源图片,图片空间会从OSS 拉取图片源文件,按要求进行尺寸缩放,然后执行编解码,返回客户端能够支持的图片内容,之后客户端就可以渲染图片,同时CDN 的L1、L2 以及客户端都会缓存图片内容。
客户端和服务器之间的流量被称为南北流量。简而言之,南北流量是·server《==》client流量。 不同服务器之间的流量与数据中心或不同数据中心之间的网络流被称为东西流量。简而言之,东西流量是server《==》server流量。
可观察性可以:
- 及时反馈异常或者风险使得开发人员可以及时关注、修复和解决问题(告警);
- 出现问题时,能够帮助快速定位问题根源并解决问题,以减少服务损失(减损);
- 收集并分析数据,以帮助开发人员不断调整和改善服务(持续优化)
可观察性的数据类型:
- 数据指标(Metrics)
- 应用日志(Access Logs)
- 分布式追踪(Distributed Traces)
2021-01-11~17
通过 doh 方式获取域名解析
get_ip_from_doh() {
local domain=${1:-www.baidu.com}
local dohs=(doh.defaultroutes.de dns.hostux.net uncensored.lux1.dns.nixnet.xyz dns.rubyfish.cn dns.alidns.com doh.centraleu.pi-dns.com doh.dns.sb doh-fi.blahdns.com fi.doh.dns.snopyta.org dns.flatuslifir.is doh.li dns.digitale-gesellschaft.ch)
ip=$(curl -4fsSLkA- -m200 "https://${dohs[$((RANDOM%10))]}/dns-query?name=${domain}" | grep -oE "\b([0-9]{1,3}\.){3}[0-9]{1,3}\b" |tr ' ' '\n'|grep -Ev [.]0|sort -uR|head -1)
echo "${domain}: ${ip}"
}
[每日一问] k8s 集群什么条件下会产生endpoint 事件?
- 创建 service,endpoint control 就会创建相应的endpoint,service匹配endpoint中的信息。
kvm 镜像转 vmware esxi
-
将kvm下虚拟机关机;
-
将kvm下img文件格式的虚拟机转换成vmdk格式,命令如下:
# 该命令只转换为vmware workstation的兼容. qemu-img convert -f qcow2 centos-t1.img -O vmdk centos-t1_temp.vmdk -o compat6 -
将镜像文件传递到 esxi 中
-
转换esxi兼容的硬盘格式.
# 转换为esxi兼容. vmkfstools -i myImage.vmdk outputName.vmdk -d thin注意这样转换出来的是两个文件:一个outputName.vmdk 是元数据,一个outputName-flat.vmdk是硬盘数据,二者必须保持一致的命名,如果要移动必须一起移动。不要自己给硬盘文件取名的时候在后面加-flat,这会导致问题。
-
在 esxi 环境里创建一个虚拟机和kvm环境虚拟机配置相同,不用创建磁盘使用刚刚转换的vmdk文件,开启虚拟机即可.
如果找不到启动项,请修改启动引导固件(Bios,EFI)然后在试试
2021-01-4~10
Exchange PowerShell 脚本 定时任务设置
# 第一种
C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe -ExecutionPolicy RemoteSigned -noprofile -noninteractive -file "E:\scripts\ExchangeDailyCheckList.ps1"
# 第二种
C:\Windows\system32\WindowsPowerShell\v1.0\powershell.exe -NonInteractive -WindowStyle Hidden -command ". 'C:\Program Files\Microsoft\Exchange Server\V15\bin\RemoteExchange.ps1'; Connect-ExchangeServer -auto; . E:\scripts\ExchangeDailyCheckList.ps1"