- 环境信息
- 版本信息
- 网络信息
- 初始化所有节点
- 免密登录其他节点
- 预下载配置文件
- 部署服务
- 建立集群CA和证书
- 部署Kubernetes Masters
- 部署Kubernetes Nodes
- Kubernetes Core Addons 部署
- Kubernetes 集群网络
- 部署Kubernetes Extra Addons组件
- 配置 etcd 定时备份
- 测试集群
- 重置集群
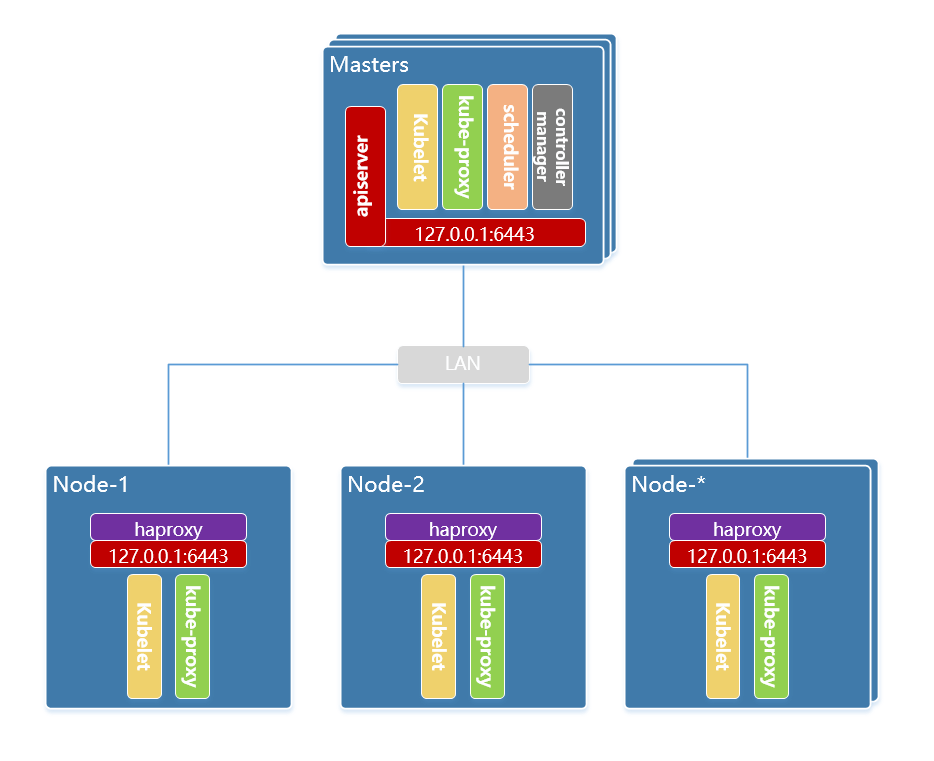
本次使用全手工的方式在 debian 10 系统上以 二进制包 形式部署 kubernetes 的 ha集群,ha 方式选择 node 节点代理 apiserver 的方式。
环境信息
| System OS | IP Address | Docker | Kernel | Hostname | Cpu | Memory | Role |
|---|---|---|---|---|---|---|---|
| Debian 10.9 | 192.168.77.140 | 20.10.5 | 4.19.0-16-amd64 | k8s–master-node1 | 2C | 4G | master |
| Debian 10.9 | 192.168.77.141 | 20.10.5 | 4.19.0-16-amd64 | k8s-master-node2 | 2C | 4G | master |
| Debian 10.9 | 192.168.77.142 | 20.10.5 | 4.19.0-16-amd64 | k8s-master-node3 | 2C | 4G | master |
| Debian 10.9 | 192.168.77.143 | 20.10.5 | 4.19.0-16-amd64 | k8s-worker-node1 | 2C | 4G | worker |
| Debian 10.9 | 192.168.77.144 | 20.10.5 | 4.19.0-16-amd64 | k8s-worker-node2 | 2C | 4G | worker |
| Debian 10.9 | 192.168.77.144 | 20.10.5 | 4.19.0-16-amd64 | k8s-worker-node3 | 2C | 4G | worker |
版本信息
Kubernetes: v1.20.5
etcd: v3.4.15
Docker CE: 20.10.5
Flannel :v0.13.0
网络信息
- Cluster IP CIDR:
10.244.0.0/16 - Service Cluster IP CIDR:
10.96.0.0/12 - Service DNS IP:
10.96.0.10 - DNS DN:
cluster.local - Kubernetes API:
127.0.0.1:6443
初始化所有节点
在集群所有节点上执行下面的操作 注意:以下操作有些存在过度优化,请根据自身情况择选。
APT调整
镜像源调整
mv /etc/apt/sources.list{,.bak}
cat > /etc/apt/sources.list <<EOF
deb http://mirrors.aliyun.com/debian/ buster main contrib non-free
deb-src http://mirrors.aliyun.com/debian/ buster main contrib non-free
deb http://mirrors.aliyun.com/debian/ buster-updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian/ buster-updates main contrib non-free
deb http://mirrors.aliyun.com/debian-security/ buster/updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian-security/ buster/updates main contrib non-free
EOF
apt-get update
取消安装服务自启动
echo -e '#!/bin/sh\nexit 101' | install -m 755 /dev/stdin /usr/sbin/policy-rc.d
取消自动更新包
systemctl mask apt-daily.service apt-daily-upgrade.service
systemctl stop apt-daily.timer apt-daily-upgrade.timer
systemctl disable apt-daily.timer apt-daily-upgrade.timer
systemctl kill --kill-who=all apt-daily.service
cat > /etc/apt/apt.conf.d/10cloudinit-disable << __EOF
APT::Periodic::Enable "0";
// undo what's in 20auto-upgrade
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
__EOF
关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
关闭selinux
setenforce 0
sed -i "s#=enforcing#=disabled#g" /etc/selinux/config
关闭swap
swapoff -a && sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
limit 限制
[ ! -f /etc/security/limits.conf_bak ] && cp /etc/security/limits.conf{,_bak}
cat << EOF >> /etc/security/limits.conf
root soft nofile 655360
root hard nofile 655360
root soft nproc 655360
root hard nproc 655360
root soft core unlimited
root hard core unlimited
* soft nofile 655360
* hard nofile 655360
* soft nproc 655360
* hard nproc 655360
* soft core unlimited
* hard core unlimited
EOF
[ ! -f /etc/systemd/system.conf_bak ] && cp /etc/systemd/system.conf.conf{,_bak}
cat << EOF >> /etc/systemd/system.conf
DefaultLimitCORE=infinity
DefaultLimitNOFILE=655360
DefaultLimitNPROC=655360
EOF
系统参数
cat << EOF > /etc/sysctl.d/99-kube.conf
# https://www.kernel.org/doc/Documentation/sysctl/
#############################################################################################
# 调整虚拟内存
#############################################################################################
# Default: 30
# 0 - 任何情况下都不使用swap。
# 1 - 除非内存不足(OOM),否则不使用swap。
vm.swappiness = 0
# 内存分配策略
#0 - 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
#1 - 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
#2 - 表示内核允许分配超过所有物理内存和交换空间总和的内存
vm.overcommit_memory=1
# OOM时处理
# 1关闭,等于0时,表示当内存耗尽时,内核会触发OOM killer杀掉最耗内存的进程。
vm.panic_on_oom=0
# vm.dirty_background_ratio 用于调整内核如何处理必须刷新到磁盘的脏页。
# Default value is 10.
# 该值是系统内存总量的百分比,在许多情况下将此值设置为5是合适的。
# 此设置不应设置为零。
vm.dirty_background_ratio = 5
# 内核强制同步操作将其刷新到磁盘之前允许的脏页总数
# 也可以通过更改 vm.dirty_ratio 的值(将其增加到默认值30以上(也占系统内存的百分比))来增加
# 推荐 vm.dirty_ratio 的值在60到80之间。
vm.dirty_ratio = 60
# vm.max_map_count 计算当前的内存映射文件数。
# mmap 限制(vm.max_map_count)的最小值是打开文件的ulimit数量(cat /proc/sys/fs/file-max)。
# 每128KB系统内存 map_count应该大约为1。 因此,在32GB系统上,max_map_count为262144。
# Default: 65530
vm.max_map_count = 2097152
#############################################################################################
# 调整文件
#############################################################################################
fs.may_detach_mounts = 1
# 增加文件句柄和inode缓存的大小,并限制核心转储。
fs.file-max = 2097152
fs.nr_open = 2097152
fs.suid_dumpable = 0
# 文件监控
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=524288
fs.inotify.max_queued_events=16384
#############################################################################################
# 调整网络设置
#############################################################################################
# 为每个套接字的发送和接收缓冲区分配的默认内存量。
net.core.wmem_default = 25165824
net.core.rmem_default = 25165824
# 为每个套接字的发送和接收缓冲区分配的最大内存量。
net.core.wmem_max = 25165824
net.core.rmem_max = 25165824
# 除了套接字设置外,发送和接收缓冲区的大小
# 必须使用net.ipv4.tcp_wmem和net.ipv4.tcp_rmem参数分别设置TCP套接字。
# 使用三个以空格分隔的整数设置这些整数,分别指定最小,默认和最大大小。
# 最大大小不能大于使用net.core.wmem_max和net.core.rmem_max为所有套接字指定的值。
# 合理的设置是最小4KiB,默认64KiB和最大2MiB缓冲区。
net.ipv4.tcp_wmem = 20480 12582912 25165824
net.ipv4.tcp_rmem = 20480 12582912 25165824
# 增加最大可分配的总缓冲区空间
# 以页为单位(4096字节)进行度量
net.ipv4.tcp_mem = 65536 25165824 262144
net.ipv4.udp_mem = 65536 25165824 262144
# 为每个套接字的发送和接收缓冲区分配的最小内存量。
net.ipv4.udp_wmem_min = 16384
net.ipv4.udp_rmem_min = 16384
# 启用TCP窗口缩放,客户端可以更有效地传输数据,并允许在代理方缓冲该数据。
net.ipv4.tcp_window_scaling = 1
# 提高同时接受连接数。
net.ipv4.tcp_max_syn_backlog = 10240
# 将net.core.netdev_max_backlog的值增加到大于默认值1000
# 可以帮助突发网络流量,特别是在使用数千兆位网络连接速度时,
# 通过允许更多的数据包排队等待内核处理它们。
net.core.netdev_max_backlog = 65536
# 增加选项内存缓冲区的最大数量
net.core.optmem_max = 25165824
# 被动TCP连接的SYNACK次数。
net.ipv4.tcp_synack_retries = 2
# 允许的本地端口范围。
net.ipv4.ip_local_port_range = 2048 65535
# 防止TCP时间等待
# Default: net.ipv4.tcp_rfc1337 = 0
net.ipv4.tcp_rfc1337 = 1
# 减少tcp_fin_timeout连接的时间默认值
net.ipv4.tcp_fin_timeout = 15
# 积压套接字的最大数量。
# Default is 128.
net.core.somaxconn = 32768
# 打开syncookies以进行SYN洪水攻击保护。
net.ipv4.tcp_syncookies = 1
# 避免Smurf攻击
# 发送伪装的ICMP数据包,目的地址设为某个网络的广播地址,源地址设为要攻击的目的主机,
# 使所有收到此ICMP数据包的主机都将对目的主机发出一个回应,使被攻击主机在某一段时间内收到成千上万的数据包
net.ipv4.icmp_echo_ignore_broadcasts = 1
# 为icmp错误消息打开保护
net.ipv4.icmp_ignore_bogus_error_responses = 1
# 启用自动缩放窗口。
# 如果延迟证明合理,这将允许TCP缓冲区超过其通常的最大值64K。
net.ipv4.tcp_window_scaling = 1
# 打开并记录欺骗,源路由和重定向数据包
net.ipv4.conf.all.log_martians = 1
net.ipv4.conf.default.log_martians = 1
# 告诉内核有多少个未附加的TCP套接字维护用户文件句柄。 万一超过这个数字,
# 孤立的连接会立即重置,并显示警告。
# Default: net.ipv4.tcp_max_orphans = 65536
net.ipv4.tcp_max_orphans = 65536
# 不要在关闭连接时缓存指标
net.ipv4.tcp_no_metrics_save = 1
# 启用RFC1323中定义的时间戳记:
# Default: net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_timestamps = 1
# 启用选择确认。
# Default: net.ipv4.tcp_sack = 1
net.ipv4.tcp_sack = 1
# 增加 tcp-time-wait 存储桶池大小,以防止简单的DOS攻击。
# net.ipv4.tcp_tw_recycle 已从Linux 4.12中删除。请改用net.ipv4.tcp_tw_reuse。
net.ipv4.tcp_max_tw_buckets = 14400
net.ipv4.tcp_tw_reuse = 1
# accept_source_route 选项使网络接口接受设置了严格源路由(SSR)或松散源路由(LSR)选项的数据包。
# 以下设置将丢弃设置了SSR或LSR选项的数据包。
net.ipv4.conf.all.accept_source_route = 0
net.ipv4.conf.default.accept_source_route = 0
# 打开反向路径过滤
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
# 禁用ICMP重定向接受
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.all.secure_redirects = 0
net.ipv4.conf.default.secure_redirects = 0
# 禁止发送所有IPv4 ICMP重定向数据包。
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.default.send_redirects = 0
# 开启IP转发.
net.ipv4.ip_forward = 1
# 禁止IPv6
net.ipv6.conf.lo.disable_ipv6=1
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
# 要求iptables不对bridge的数据进行处理
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
# arp缓存
# 存在于 ARP 高速缓存中的最少层数,如果少于这个数,垃圾收集器将不会运行。缺省值是 128
net.ipv4.neigh.default.gc_thresh1=2048
# 保存在 ARP 高速缓存中的最多的记录软限制。垃圾收集器在开始收集前,允许记录数超过这个数字 5 秒。缺省值是 512
net.ipv4.neigh.default.gc_thresh2=4096
# 保存在 ARP 高速缓存中的最多记录的硬限制,一旦高速缓存中的数目高于此,垃圾收集器将马上运行。缺省值是 1024
net.ipv4.neigh.default.gc_thresh3=8192
# 持久连接
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
# conntrack表
net.nf_conntrack_max=1048576
net.netfilter.nf_conntrack_max=1048576
net.netfilter.nf_conntrack_buckets=262144
net.netfilter.nf_conntrack_tcp_timeout_fin_wait=30
net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
net.netfilter.nf_conntrack_tcp_timeout_close_wait=15
net.netfilter.nf_conntrack_tcp_timeout_established=300
#############################################################################################
# 调整内核参数
#############################################################################################
# 地址空间布局随机化(ASLR)是一种用于操作系统的内存保护过程,可防止缓冲区溢出攻击。
# 这有助于确保与系统上正在运行的进程相关联的内存地址不可预测,
# 因此,与这些流程相关的缺陷或漏洞将更加难以利用。
# Accepted values: 0 = 关闭, 1 = 保守随机化, 2 = 完全随机化
kernel.randomize_va_space = 2
# 调高 PID 数量
kernel.pid_max = 65536
kernel.threads-max=30938
# coredump
kernel.core_pattern=core
# 决定了检测到soft lockup时是否自动panic,缺省值是0
kernel.softlockup_all_cpu_backtrace=1
kernel.softlockup_panic=1
EOF
sysctl --system
history 数据格式和 ps1
cat << EOF >> /etc/bash.bashrc
# history actions record,include action time, user, login ip
HISTFILESIZE=5000
HISTSIZE=5000
USER_IP=\$(who -u am i 2>/dev/null | awk '{print \$NF}' | sed -e 's/[()]//g')
if [ -z \$USER_IP ]
then
USER_IP=\$(hostname -i)
fi
HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S \$USER_IP:\$(whoami) "
export HISTFILESIZE HISTSIZE HISTTIMEFORMAT
# PS1
PS1='\[\033[0m\]\[\033[1;36m\][\u\[\033[0m\]@\[\033[1;32m\]\h\[\033[0m\] \[\033[1;31m\]\w\[\033[0m\]\[\033[1;36m\]]\[\033[33;1m\]\\$ \[\033[0m\]'
EOF
journal 日志
mkdir -p /var/log/journal /etc/systemd/journald.conf.d
cat << EOF > /etc/systemd/journald.conf.d/99-prophet.conf
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 3 周
MaxRetentionSec=3week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
ssh登录信息
cat << EOF > /etc/profile.d/zz-ssh-login-info.sh
#!/bin/sh
#
# @Time : 2020-02-04
# @Author : lework
# @Desc : ssh login banner
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
shopt -q login_shell && : || return 0
echo -e "\033[0;32m
██╗ ██╗ █████╗ ███████╗
██║ ██╔╝██╔══██╗██╔════╝
█████╔╝ ╚█████╔╝███████╗
██╔═██╗ ██╔══██╗╚════██║
██║ ██╗╚█████╔╝███████║
╚═╝ ╚═╝ ╚════╝ ╚══════ by lework\033[0m"
# os
upSeconds="\$(cut -d. -f1 /proc/uptime)"
secs=\$((\${upSeconds}%60))
mins=\$((\${upSeconds}/60%60))
hours=\$((\${upSeconds}/3600%24))
days=\$((\${upSeconds}/86400))
UPTIME_INFO=\$(printf "%d days, %02dh %02dm %02ds" "\$days" "\$hours" "\$mins" "\$secs")
if [ -f /etc/redhat-release ] ; then
PRETTY_NAME=\$(< /etc/redhat-release)
elif [ -f /etc/debian_version ]; then
DIST_VER=\$(</etc/debian_version)
PRETTY_NAME="\$(grep PRETTY_NAME /etc/os-release | sed -e 's/PRETTY_NAME=//g' -e 's/"//g') (\$DIST_VER)"
else
PRETTY_NAME=\$(cat /etc/*-release | grep "PRETTY_NAME" | sed -e 's/PRETTY_NAME=//g' -e 's/"//g')
fi
if [[ -d "/system/app/" && -d "/system/priv-app" ]]; then
model="\$(getprop ro.product.brand) \$(getprop ro.product.model)"
elif [[ -f /sys/devices/virtual/dmi/id/product_name ||
-f /sys/devices/virtual/dmi/id/product_version ]]; then
model="\$(< /sys/devices/virtual/dmi/id/product_name)"
model+=" \$(< /sys/devices/virtual/dmi/id/product_version)"
elif [[ -f /sys/firmware/devicetree/base/model ]]; then
model="\$(< /sys/firmware/devicetree/base/model)"
elif [[ -f /tmp/sysinfo/model ]]; then
model="\$(< /tmp/sysinfo/model)"
fi
MODEL_INFO=\${model}
KERNEL=\$(uname -srmo)
USER_NUM=\$(who -u | wc -l)
RUNNING=\$(ps ax | wc -l | tr -d " ")
# disk
totaldisk=\$(df -h -x devtmpfs -x tmpfs -x debugfs -x aufs -x overlay --total 2>/dev/null | tail -1)
disktotal=\$(awk '{print \$2}' <<< "\${totaldisk}")
diskused=\$(awk '{print \$3}' <<< "\${totaldisk}")
diskusedper=\$(awk '{print \$5}' <<< "\${totaldisk}")
DISK_INFO="\033[0;33m\${diskused}\033[0m of \033[1;34m\${disktotal}\033[0m disk space used (\033[0;33m\${diskusedper}\033[0m)"
# cpu
cpu=\$(awk -F':' '/^model name/ {print \$2}' /proc/cpuinfo | uniq | sed -e 's/^[ \t]*//')
cpun=\$(grep -c '^processor' /proc/cpuinfo)
cpuc=\$(grep '^cpu cores' /proc/cpuinfo | tail -1 | awk '{print \$4}')
cpup=\$(grep '^physical id' /proc/cpuinfo | wc -l)
CPU_INFO="\${cpu} \${cpup}P \${cpuc}C \${cpun}L"
# get the load averages
read one five fifteen rest < /proc/loadavg
LOADAVG_INFO="\033[0;33m\${one}\033[0m / \${five} / \${fifteen} with \033[1;34m\$(( cpun*cpuc ))\033[0m core(s) at \033[1;34m\$(grep '^cpu MHz' /proc/cpuinfo | tail -1 | awk '{print \$4}')\033 MHz"
# mem
MEM_INFO="\$(cat /proc/meminfo | awk '/MemTotal:/{total=\$2/1024/1024;next} /MemAvailable:/{use=total-\$2/1024/1024; printf("\033[0;33m%.2fGiB\033[0m of \033[1;34m%.2fGiB\033[0m RAM used (\033[0;33m%.2f%%\033[0m)",use,total,(use/total)*100);}')"
# network
# extranet_ip=" and \$(curl -s ip.cip.cc)"
IP_INFO="\$(ip a | grep glo | awk '{print \$2}' | head -1 | cut -f1 -d/)\${extranet_ip:-}"
# Container info
CONTAINER_INFO="\$(sudo /usr/bin/crictl ps -a -o yaml 2> /dev/null | awk '/^ state: /{gsub("CONTAINER_", "", \$NF) ++S[\$NF]}END{for(m in S) printf "%s%s:%s ",substr(m,1,1),tolower(substr(m,2)),S[m]}')Images:\$(sudo /usr/bin/crictl images -q 2> /dev/null | wc -l)"
# info
echo -e "
Information as of: \033[1;34m\$(date +"%Y-%m-%d %T")\033[0m
\033[0;1;31mProduct\033[0m............: \${MODEL_INFO}
\033[0;1;31mOS\033[0m.................: \${PRETTY_NAME}
\033[0;1;31mKernel\033[0m.............: \${KERNEL}
\033[0;1;31mCPU\033[0m................: \${CPU_INFO}
\033[0;1;31mHostname\033[0m...........: \033[1;34m\$(hostname)\033[0m
\033[0;1;31mIP Addresses\033[0m.......: \033[1;34m\${IP_INFO}\033[0m
\033[0;1;31mUptime\033[0m.............: \033[0;33m\${UPTIME_INFO}\033[0m
\033[0;1;31mMemory\033[0m.............: \${MEM_INFO}
\033[0;1;31mLoad Averages\033[0m......: \${LOADAVG_INFO}
\033[0;1;31mDisk Usage\033[0m.........: \${DISK_INFO}
\033[0;1;31mUsers online\033[0m.......: \033[1;34m\${USER_NUM}\033[0m
\033[0;1;31mRunning Processes\033[0m..: \033[1;34m\${RUNNING}\033[0m
\033[0;1;31mContainer Info\033[0m.....: \${CONTAINER_INFO}
"
EOF
chmod +x /etc/profile.d/zz-ssh-login-info.sh
echo 'ALL ALL=NOPASSWD: /usr/bin/crictl info' > /etc/sudoers.d/crictl
时间同步
ntpd --help >/dev/null 2>1 && apt-get remove -y ntp
apt-get install -y chrony
[ ! -f /etc/chrony.conf_bak ] && cp /etc/chrony.conf{,_bak} #备份默认配置
cat << EOF > /etc/chrony.conf
server ntp.aliyun.com iburst
server cn.ntp.org.cn iburst
server ntp.shu.edu.cn iburst
server 0.cn.pool.ntp.org iburst
server 1.cn.pool.ntp.org iburst
server 2.cn.pool.ntp.org iburst
server 3.cn.pool.ntp.org iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
logdir /var/log/chrony
EOF
timedatectl set-timezone Asia/Shanghai
chronyd -q -t 1 'server cn.pool.ntp.org iburst maxsamples 1'
systemctl enable chronyd
systemctl start chronyd
chronyc sources -v
chronyc sourcestats
启用ipvs
apt-get install -y ipvsadm ipset sysstat conntrack libseccomp2
开机自启动加载ipvs内核
:> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
# systemctl enable --now systemd-modules-load.service
ipvsadm --clear
系统审计
apt-get install -y auditd audispd-plugins
cat << EOF > /etc/audit/rules.d/audit.rules
# Remove any existing rules
-D
# Buffer Size
-b 8192
# Failure Mode
-f 1
# Ignore errors
-i
# docker
-w /usr/bin/dockerd -k docker
-w /var/lib/docker -k docker
-w /etc/docker -k docker
-w /usr/lib/systemd/system/docker.service -k docker
-w /etc/systemd/system/docker.service -k docker
-w /usr/lib/systemd/system/docker.socket -k docker
-w /etc/default/docker -k docker
-w /etc/sysconfig/docker -k docker
-w /etc/docker/daemon.json -k docker
# containerd
-w /usr/bin/containerd -k containerd
-w /var/lib/containerd -k containerd
-w /usr/lib/systemd/system/containerd.service -k containerd
-w /etc/containerd/config.toml -k containerd
# runc
-w /usr/bin/runc -k runc
# kube
-w /usr/bin/kubeadm -k kubeadm
-w /usr/bin/kubelet -k kubelet
-w /usr/bin/kubectl -k kubectl
-w /var/lib/kubelet -k kubelet
-w /etc/kubernetes -k kubernetes
EOF
chmod 600 /etc/audit/rules.d/audit.rules
sed -i 's#max_log_file =.*#max_log_file = 80#g' /etc/audit/auditd.conf
systemctl stop auditd && systemctl start auditd
systemctl enable auditd
dns 选项
grep single-request-reopen /etc/resolv.conf || sed -i '1ioptions timeout:2 attempts:3 rotate single-request-reopen' /etc/resolv.conf
升级内核
注意:这里是可选项。
debian 10 默认关闭了 cgroup hugetlb 。可以通过更新内核开启。
root@debian:~# cat /etc/debian_version
10.9
root@debian:~# uname -r
4.19.0-16-amd64
root@debian:~# grep HUGETLB /boot/config-$(uname -r)
# CONFIG_CGROUP_HUGETLB is not set
CONFIG_ARCH_WANT_GENERAL_HUGETLB=y
CONFIG_HUGETLBFS=y
CONFIG_HUGETLB_PAGE=y
更新内核
# 添加 backports 源
$ sudo echo "deb http://mirrors.aliyun.com/debian buster-backports main" > /etc/apt/sources.list.d/backports.list
# 更新来源
$ sudo apt update
# 安装 Linux 内核映像
$ sudo apt -t buster-backports install linux-image-amd64
# 安装 Linux 内核标头(可选)
$ sudo apt -t buster-backports install linux-headers-amd64
重启之后,再次查看 cgroup hugetlb
root@debian:~# cat /etc/debian_version
10.9
root@debian:~# uname -r
5.10.0-0.bpo.4-amd64
root@debian:~# grep HUGETLB /boot/config-$(uname -r)
CONFIG_CGROUP_HUGETLB=y
CONFIG_ARCH_WANT_GENERAL_HUGETLB=y
CONFIG_HUGETLBFS=y
CONFIG_HUGETLB_PAGE=y
安装 docker-ce
apt-get install -y apt-transport-https ca-certificates curl gnupg2 lsb-release bash-completion
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/debian/gpg | sudo apt-key add -
echo "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/debian $(lsb_release -cs) stable" > /etc/apt/sources.list.d/docker-ce.list
sudo apt-get update
apt-get install -y docker-ce docker-ce-cli containerd.io
apt-mark hold docker-ce docker-ce-cli containerd.io
cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/
mkdir /etc/docker
cat >> /etc/docker/daemon.json <<EOF
{
"data-root": "/var/lib/docker",
"log-driver": "json-file",
"log-opts": {
"max-size": "200m",
"max-file": "5"
},
"default-ulimits": {
"nofile": {
"Name": "nofile",
"Hard": 655360,
"Soft": 655360
},
"nproc": {
"Name": "nproc",
"Hard": 655360,
"Soft": 655360
}
},
"live-restore": true,
"oom-score-adjust": -1000,
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"storage-driver": "overlay2",
"storage-opts": ["overlay2.override_kernel_check=true"],
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://yssx4sxy.mirror.aliyuncs.com/"
]
}
EOF
systemctl enable --now docker
sed -i 's|#oom_score = 0|oom_score = -999|' /etc/containerd/config.toml
systemctl enable --now containerd
主机名配置
hostnamectl set-hostname k8s-master-node1
根据每个节点名称进行设置
节点主机名解析
cat << EOF >> /etc/hosts
192.168.77.140 k8s-master-node1
192.168.77.141 k8s-master-node2
192.168.77.142 k8s-master-node3
192.168.77.143 k8s-worker-node1
192.168.77.144 k8s-worker-node2
192.168.77.145 k8s-worker-node3
EOF
免密登录其他节点
我们需要大量的对节点进行操作,这里通过免密,对集群节点批量处理,进而减少安装时间。
在 k8s-master-node1 操作
使用 root 用户操作
su - root
设置下节点变量
export MASTER_NODES="k8s-master-node1 k8s-master-node2 k8s-master-node3"
export WORKER_NODES="k8s-worker-node1 k8s-worker-node2 k8s-worker-node3"
export ALL_NODES="${MASTER_NODES} ${WORKER_NODES}"
这里为了简单,开启了root远程登录,等集群建立完成后,在进行关闭。
apt-get install -y sshpass
for NODE in ${ALL_NODES}; do
echo "--- $NODE ---"
sshpass -p 123456 ssh test@${NODE} " sudo runuser -s /bin/bash root -c \"echo 'PermitRootLogin yes' >> /etc/ssh/sshd_config\"; sudo systemctl restart sshd"
done
其中
123456是服务器的密码,test是服务器的连接用户,且test用户拥有sudo特权。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
for NODE in ${ALL_NODES}; do
echo "--- $NODE ---"
sshpass -p 123456 ssh-copy-id -o "StrictHostKeyChecking no" -i ~/.ssh/id_rsa.pub ${NODE}
done
其中
123456是服务器root用户 的密码。
预下载配置文件
通过git,下载本次使用的配置文件
在k8s-m1上执行
git clone https://github.com/lework/kubernetes-manual.git /opt/kubernetes-manual
部署服务
部署 etcd
下载二进制文件
mkdir -p /opt/v1.20.5/bin/
wget https://github.com/etcd-io/etcd/releases/download/v3.4.15/etcd-v3.4.15-linux-amd64.tar.gz
tar zxfv etcd-v3.4.15-linux-amd64.tar.gz --wildcards etcd-v3.4.15-linux-amd64/etc*
mv etcd-v3.4.15-linux-amd64/etcd* /opt/v1.20.5/bin/
分发etcd二进制文件, etcd 集群部署在 master 节点上。
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
scp /opt/v1.20.5/bin/etcd* ${NODE}:/usr/local/sbin/
ssh ${NODE} "useradd etcd -s /sbin/nologin; chmod +x /usr/local/sbin/etcd*"
done
部署 kubernetes 组件
下载二进制文件
for item in kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet kubectl
do
wget https://storage.googleapis.com/kubernetes-release/release/v1.20.5/bin/linux/amd64/${item} -O /opt/v1.20.5/bin/${item}
done
分发二进制文件
# Master 节点
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
scp /opt/v1.20.5/bin/kube* ${NODE}:/usr/local/sbin/
ssh ${NODE} "useradd kube -s /sbin/nologin; chmod +x /usr/local/sbin/kube*"
done
# Worker 节点
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
scp /opt/v1.20.5/bin/{kubelet,kube-proxy} ${NODE}/usr/local/sbin
ssh ${NODE} "sudo useradd kube -s /sbin/nologin; sudo chmod +x /usr/local/sbin/kube*"
done
部署 haproxy
haproxy 没有版本要求,仅使用haproxy代理apiserver的访问,直接安装即可。
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} "apt-get -y install haproxy"
done
部署 crictl
crictl 是 CRI 兼容的容器运行时命令行接口。 你可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序。 crictl 和它的源代码在 cri-tools 代码库。
下载二进制文件
wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.21.0/crictl-v1.21.0-linux-amd64.tar.gz
tar zxvf crictl-v1.21.0-linux-amd64.tar.gz -C /opt/v1.20.5/bin/
分发二进制文件
for NODE in ${ALL_NODES}; do
echo "--- $NODE ---"
scp /opt/v1.20.5/bin/crictl ${NODE}:/usr/local/sbin/crictl
ssh ${NODE} "
cat << EOF > /etc/crictl.yaml
runtime-endpoint: unix:///var/run/dockershim.sock
image-endpoint: unix:///var/run/dockershim.sock
timeout: 2
debug: false
pull-image-on-create: true
disable-pull-on-run: false
EOF
chmod +x /usr/local/sbin/crictl
"
done
部署 cfssl 工具
在 k8s-master-node1上安裝 cfssl 工具 ,用来建立 CA 证书,并生成 tls 认证
下载二进制文件
wget https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -O /opt/v1.20.5/bin/cfssljson
wget https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -O /opt/v1.20.5/bin/cfssl
拷贝二进制文件到可执行目录中。
cp /opt/v1.20.5/bin/cfs* /usr/local/sbin/
chmod +x /usr/local/sbin/cfs*
建立集群CA和证书
本次所需要创建的 CA
| Default CN | Description |
|---|---|
| kubernetes-ca | Kubernetes general CA |
| etcd-ca | For all etcd-related functions |
| kubernetes-front-proxy-ca | For the front-end proxy |
在
k8s-master-node1操作
创建 etcd 所需的证书
创建ca配置
mkdir -p /etc/etcd/ssl && cd /etc/etcd/ssl
echo '{"signing":{"default":{"expiry":"87600h"},"profiles":{"kubernetes":{"usages":["signing","key encipherment","server auth","client auth"],"expiry":"87600h"}}}}' > ca-config.json
生成etcd的ca证书
echo '{"CN":"etcd","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"etcd","OU":"Etcd Security"}]}' > etcd-ca-csr.json
cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare etcd-ca
生成etcd的凭证
echo '{"CN":"etcd","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"etcd","OU":"Etcd Security"}]}' > etcd-csr.json
cfssl gencert \
-ca=etcd-ca.pem \
-ca-key=etcd-ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,192.168.77.140,192.168.77.141,192.168.77.142,*.etcd.local \
-profile=kubernetes \
etcd-csr.json | cfssljson -bare etcd
-hostname需修改成所有masters节点的ip地址, 建议在生产环境在证书内预留几个IP.*.etcd.local是预留的名称,后续加入节点时可以使用。 证书默认期限为87600h(10年),有需要加强安全性的可以适当减小。
将etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem文件拷贝到其它master节点上
for NODE in k8s-master-node2 k8s-master-node3; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /etc/etcd/ssl"
scp /etc/etcd/ssl/{etcd-ca-key.pem,etcd-ca.pem,etcd-key.pem,etcd.pem} ${NODE}:/etc/etcd/ssl
done
创建Kubernetes组件的证书
建立ca
cd /etc/kubernetes/pki
echo '{"signing":{"default":{"expiry":"87600h"},"profiles":{"kubernetes":{"usages":["signing","key encipherment","server auth","client auth"],"expiry":"87600h"}}}}' > ca-config.json
echo '{"CN":"kubernetes","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"Kubernetes","OU":"Kubernetes System"}]}' > ca-csr.json
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
证书默认期限为87600h(10年),有需要加强安全性的可以适当减小。
建立API Server Certificate
此凭证将被用于 API Server 与 Kubelet Client 通信使用
echo '{"CN":"kube-apiserver","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"Kubernetes","OU":"Kubernetes System"}]}' > apiserver-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,10.96.0.1,192.168.77.140,192.168.77.141,192.168.77.142,localhost,*.master.kubernetes.node,kubernetes,kubernetes.default,kubernetes.default.svc,kubernetes.default.svc.cluster,kubernetes.default.svc.cluster.local \
-profile=kubernetes \
apiserver-csr.json | cfssljson -bare apiserver
这边
-hostname的10.96.0.1是kubernetes的Cluster IP,其他是master节点的ip地址。
kubernetes.default为Kubernets DN。
*.master.kubernetes.node是预留的解析名称,可以在本地绑定主机名称进行访问api。
Front Proxy Certificate
此凭证将被用于Authenticating Proxy的功能上,而该功能主要是提供API Aggregation的认证。首先通过以下命令创建CA:
echo '{"CN":"kubernetes","key":{"algo":"rsa","size":2048}}' > front-proxy-ca-csr.json
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare front-proxy-ca
echo '{"CN":"front-proxy-client","key":{"algo":"rsa","size":2048}}' > front-proxy-client-csr.json
cfssl gencert \
-ca=front-proxy-ca.pem \
-ca-key=front-proxy-ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
front-proxy-client-csr.json | cfssljson -bare front-proxy-client
提示 hosts 的 warning 信息忽略即可
Controller Manager Certificate
凭证会建立system:kube-controller-manager的使用者(凭证CN),并被绑定在RBAC Cluster Role中的system:kube-controller-manager来让Controller Manager组件能够存取需要的API object。
echo '{"CN":"system:kube-controller-manager","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"syroller-manager","OU":"Kubernetes System"}]}' > manager-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
manager-csr.json | cfssljson -bare controller-manager
Scheduler Certificate
凭证会建立system:kube-scheduler的使用者(凭证CN),并被绑定在 RBAC Cluster Role 中的system:kube-scheduler来让 Scheduler 元件能够存取需要的 API object。
echo '{"CN":"system:kube-scheduler","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"system:kube-scheduler","OU":"Kubernetes System"}]}' > scheduler-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
scheduler-csr.json | cfssljson -bare scheduler
Admin Certificate
Admin被用来绑定RBAC Cluster Role中cluster-admin,当想要操作所有Kubernetes集群功能时,就必须利用这边产生的kubeconfig档案。通过以下命令创建Kubernetes Admin凭证:
echo '{"CN":"admin","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"system:masters","OU":"Kubernetes System"}]}' > admin-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare admin
Master Kubelet Certificate
这边使用Node authorizer来让节点的kubelet能够存取如services、endpoints等API,而使用Node authorizer需定义system:nodes群组(凭证的Organization),并且包含system:node:的使用者名称(凭证的Common Name)。
echo '{"CN":"system:node:$NODE","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","L":"Shanghai","ST":"Shanghai","O":"system:nodes","OU":"Kubernetes System"}]}' > kubelet-csr.json
# 生成各节点的证书
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
cp kubelet-csr.json kubelet-$NODE-csr.json;
sed -i "s/\$NODE/$NODE/g" kubelet-$NODE-csr.json;
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=$NODE \
-profile=kubernetes \
kubelet-$NODE-csr.json | cfssljson -bare kubelet-$NODE
done
完成后复制 kubelet 凭证到其它节点
for NODE in k8s-master-node2 k8s-master-node3; do
echo "--- $NODE ---"
scp /etc/kubernetes/pki/{kubelet-$NODE-key.pem,kubelet-$NODE.pem,ca.pem} ${NODE}:/etc/kubernetes/pki/${FILE}
done
生成kubernetes组件的凭证
export KUBE_APISERVER="https://127.0.0.1:6443" # 修改kubernetes的server地址
本次使用的ha方式是node节点的本地代理,所以 ip 是
127.0.0.1地址
生成admin.conf的kubeconfig
# admin set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../admin.kubeconfig
# admin set credentials
kubectl config set-credentials kubernetes-admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem \
--embed-certs=true \
--kubeconfig=../admin.kubeconfig
# admin set context
kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=../admin.kubeconfig
# admin set default context
kubectl config use-context kubernetes-admin@kubernetes \
--kubeconfig=../admin.kubeconfig
生成controller-manager.conf的 kubeconfig
# controller-manager set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set credentials
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=controller-manager.pem \
--client-key=controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set context
kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set default context
kubectl config use-context system:kube-controller-manager@kubernetes \
--kubeconfig=../controller-manager.kubeconfig
生成scheduler.conf的kubeconfig
# scheduler set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../scheduler.kubeconfig
# scheduler set credentials
kubectl config set-credentials system:kube-scheduler \
--client-certificate=scheduler.pem \
--client-key=scheduler-key.pem \
--embed-certs=true \
--kubeconfig=../scheduler.kubeconfig
# scheduler set context
kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=../scheduler.kubeconfig
# scheduler use default context
kubectl config use-context system:kube-scheduler@kubernetes \
--kubeconfig=../scheduler.kubeconfig
在各节点上生成 kubelet 的kubeconfig
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} "source /etc/profile; cd /etc/kubernetes/pki && \
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config set-credentials system:node:${NODE} \
--client-certificate=kubelet-${NODE}.pem \
--client-key=kubelet-${NODE}-key.pem \
--embed-certs=true \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config set-context system:node:${NODE}@kubernetes \
--cluster=kubernetes \
--user=system:node:${NODE} \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config use-context system:node:${NODE}@kubernetes \
--kubeconfig=../kubelet.kubeconfig "
done
Service Account Key
Kubernetes Controller Manager利用Key pair来产生与签署Service Account的 tokens,而这边不通过CA做认证,而是建立一组公私钥来让API Server与Controller Manager 使用:
openssl genrsa -out sa.key 2048
openssl rsa -in sa.key -pubout -out sa.pub
生成用于加密静态Secret数据的配置文件encryption.yaml
cat <<EOF> /etc/kubernetes/encryption.yaml
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: $(head -c 32 /dev/urandom | base64)
- identity: {}
EOF
生成apiserver RBAC审计配置文件audit-policy.yaml
cat <<EOF> /etc/kubernetes/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
EOF
分发凭证至其他master节点
cd /etc/kubernetes/pki/
for NODE in k8s-master-node2 k8s-master-node3; do
echo "--- $NODE ---"
for FILE in $(ls ca*.pem sa.* apiserver*.pem front*.pem scheduler*.pem); do
scp /etc/kubernetes/pki/${FILE} ${NODE}:/etc/kubernetes/pki/${FILE}
done
for FILE in /etc/kubernetes/encryption.yaml /etc/kubernetes/audit-policy.yaml; do
scp ${FILE} ${NODE}:${FILE}
done
done
分发Kubernetes config到其它master节点
for NODE in k8s-master-node2 k8s-master-node3; do
echo "--- $NODE ---"
for FILE in admin.kubeconfig controller-manager.kubeconfig scheduler.kubeconfig; do
scp /etc/kubernetes/${FILE} ${NODE}:/etc/kubernetes/${FILE}
done
done
部署Kubernetes Masters
- kubelet:负责管理容器的生命周期,定期从 API Server 取得节点上的预期状态(如网路、储存等等配置)资源,并呼叫对应的容器介面(CRI、CNI 等)来达成这个状态。任何 Kubernetes 节点都会拥有该元件。
- kube-apiserver:以 REST APIs 提供 Kubernetes 资源的 CRUD,如授权、认证、存取控制与 API 注册等机制。
- kube-controller-manager:通过核心控制循环(Core Control Loop)监听 Kubernetes API 的资源来维护集群的状态,这些资源会被不同的控制器所管理,如 Replication Controller、Namespace Controller 等等。而这些控制器会处理着自动扩展、滚动更新等等功能。
- kube-scheduler:负责将一个(或多个)容器依据排程策略分配到对应节点上让容器引擎(如 Docker)执行。
- etcd:用来保存丛集所有状态的 Key/Value 储存系统,所有 Kubernetes 组件会通过 API Server 来跟 etcd 进行沟通来保存或取得资源状态。
配置etcd
分发etcd配置
#指定etcd集群地址
ETCD_INITIAL_CLUSTER="k8s-master-node1=https://192.168.77.140:2380,k8s-master-node2=https://192.168.77.141:2380,k8s-master-node3=https://192.168.77.142:2380"
cd /opt/kubernetes-manual/v1.20.5/
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /var/lib/etcd"
scp master/etc/etcd/etcd.config.yaml ${NODE}:/etc/etcd/etcd.config.yaml
scp master/systemd/etcd.service ${NODE}:/usr/lib/systemd/system/etcd.service
ssh ${NODE} sed -i 's#{{HOSTNAME}}#${HOSTNAME}#g' /etc/etcd/etcd.config.yaml
ssh ${NODE} sed -i "s#{{ETCD_INITIAL_CLUSTER}}#${ETCD_INITIAL_CLUSTER}#g" /etc/etcd/etcd.config.yaml
ssh ${NODE} sed -i 's#{{PUBLIC_IP}}#$(hostname -i)#g' /etc/etcd/etcd.config.yaml
ssh ${NODE} chown etcd.etcd -R /etc/etcd /var/lib/etcd
done
这里如果ip改变,需要更改
ETCD_INITIAL_CLUSTER地址。
启动ETCD服务
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} "systemctl daemon-reload && systemctl enable --now etcd"
done
查看etcd服务状态
export PKI="/etc/etcd/ssl/"
ETCDCTL_API=3 etcdctl \
--cacert=${PKI}/etcd-ca.pem \
--cert=${PKI}/etcd.pem \
--key=${PKI}/etcd-key.pem \
--endpoints="https://127.0.0.1:2379" \
member list
bd11c35d070fb6c, started, k8s-master-node2, https://192.168.77.141:2380, https://192.168.77.141:2379, false
a0d88aaf5cf2f74f, started, k8s-master-node1, https://192.168.77.140:2380, https://192.168.77.140:2379, false
e8ea766b9665c6d8, started, k8s-master-node3, https://192.168.77.142:2380, https://192.168.77.142:2379, false
配置kubernetes组件
分发kubernetes组件配置文件
ETCD_SERVERS='https://192.168.77.140:2379,https://192.168.77.141:2379,https://192.168.77.142:2379'
APISERVER_COUNT=3
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} 'mkdir -p /etc/kubernetes/manifests /var/lib/kubelet /var/log/kubernetes/{apiserver,scheduler,controller-manager,proxy,kubelet}'
scp master/systemd/kube*.service ${NODE}:/usr/lib/systemd/system/
scp master/etc/kubernetes/kubelet-conf.yaml $NODE:/etc/kubernetes/kubelet-conf.yaml
ssh ${NODE} sed -i 's#{{NODE_IP}}#$(hostname -i)#g' /usr/lib/systemd/system/kube-apiserver.service
ssh ${NODE} sed -i "s#{{APISERVER_COUNT}}#${APISERVER_COUNT}#g" /usr/lib/systemd/system/kube-apiserver.service
ssh ${NODE} sed -i "s#{{ETCD_SERVERS}}#${ETCD_SERVERS}#g" /usr/lib/systemd/system/kube-apiserver.service
done
这里如果ip改变,需要更改
ETCD_SERVERS地址。APISERVER_COUNT是运行的apiserver节点数
启动服务
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh $NODE 'systemctl enable --now kube-apiserver kube-controller-manager kube-scheduler kubelet;
mkdir -p ~/.kube/
cp /etc/kubernetes/admin.kubeconfig ~/.kube/config;
kubectl completion bash > /etc/bash_completion.d/kubectl'
done
接下来将建立TLS Bootstrapping来让Node签证并授权注册到集群。
建立TLS Bootstrapping RBAC
由于本实验采用TLS认证来确保Kubernetes集群的安全性,因此每个节点的kubelet都需要透过API Server的CA进行身份验证后,才能与API Server进行沟通,而这过程过去都是采用手动方式针对每台节点(master与node)单独签署凭证,再设定给kubelet使用,然而这种方式是一件繁琐的事情,因为当节点扩展到一定程度时,将会非常费时,甚至延伸初管理不易问题。
而由于上述问题,Kubernetes实现了TLSBootstrapping来解决此问题,这种做法是先让kubelet以一个低权限使用者(一个能存取CSR API的Token)存取API Server,接着对API Server提出申请凭证签署请求,并在受理后由API Server动态签署kubelet凭证提供给对应的node节点使用。具体作法请参考TLS Bootstrapping与Authenticating with Bootstrap Tokens。
在k8s-m1上创建bootstrap使用者的kubeconfig
cd /etc/kubernetes/pki
export TOKEN_ID=$(openssl rand -hex 3)
export TOKEN_SECRET=$(openssl rand -hex 8)
export BOOTSTRAP_TOKEN=${TOKEN_ID}.${TOKEN_SECRET}
export KUBE_APISERVER="https://127.0.0.1:6443" # apiserver 的vip地址
# bootstrap set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap set credentials
kubectl config set-credentials tls-bootstrap-token-user \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap set context
kubectl config set-context tls-bootstrap-token-user@kubernetes \
--cluster=kubernetes \
--user=tls-bootstrap-token-user \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap use default context
kubectl config use-context tls-bootstrap-token-user@kubernetes \
--kubeconfig=../bootstrap-kubelet.kubeconfig
KUBE_APISERVER这边设定为VIP地址。若想要用手动签署凭证来进行授权的话,可以参考 Certificate。
接着在k8s-m1建立 TLS Bootstrap Secret来提供自动签证使用:
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-${TOKEN_ID}
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
token-id: ${TOKEN_ID}
token-secret: ${TOKEN_SECRET}
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token
EOF
然后建立TLS Bootstrap Autoapprove RBAC来提供自动受理CSR:
cat <<EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:node-bootstrapper
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:nodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-certificate-rotation
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:nodes
EOF
验证集群
[root@k8s-master-node1 /etc/kubernetes/pki]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
controller-manager Healthy ok
[root@k8s-master-node1 /etc/kubernetes/pki]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10m
# 证书
[root@k8s-master-node1 /etc/kubernetes/pki]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-6mxt6 7m8s kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node1 Approved,Issued
csr-pr6wt 6m56s kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node3 Approved,Issued
csr-vxpl8 7m5s kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node2 Approved,Issued
# 节点
[root@k8s-master-node1 /etc/kubernetes/pki]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master-node1 NotReady <none> 6m43s v1.20.5
k8s-master-node2 NotReady <none> 6m41s v1.20.5
k8s-master-node3 NotReady <none> 6m35s v1.20.5
这里的节点状态
NotReady是正常的,因为我们集群网络还没建立。
给 master 节点设置 role
kubectl get node | grep '<none>' | awk '{print "kubectl label node " $1 " node-role.kubernetes.io/master= --overwrite" }' | bash
给master节点设置Taints and Tolerations ,阻止pod调度到master节点
kubectl taint nodes node-role.kubernetes.io/master="":NoSchedule --all
创建kube-apiserver user对nodes的资源存取权限
cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kube-apiserver
EOF
部署Kubernetes Nodes
配置haproxy
配置代理apiserver服务
cd /opt/kubernetes-manual/v1.20.5/
cat <<EOF>> node/etc/haproxy/haproxy.cfg
server k8s-master-node1 192.168.77.140:6443 check
server k8s-master-node2 192.168.77.141:6443 check
server k8s-master-node3 192.168.77.142:6443 check
EOF
分发配置并启动haproxy
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
scp node/etc/haproxy/haproxy.cfg $NODE:/etc/haproxy/haproxy.cfg
ssh $NODE systemctl enable --now haproxy.service
done
验证haproxy代理
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
ssh ${NODE} curl -k -s https://127.0.0.1:6443
done
配置kubelet
分发配置并启动kubelet
cd /opt/kubernetes-manual/v1.20.5/
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
ssh $NODE "mkdir -p /etc/kubernetes/pki /etc/kubernetes/manifests /var/lib/kubelet /var/log/kubernetes/kubelet"
scp /etc/kubernetes/pki/ca.pem $NODE:/etc/kubernetes/pki/ca.pem
scp /etc/kubernetes/bootstrap-kubelet.kubeconfig $NODE:/etc/kubernetes/bootstrap-kubelet.kubeconfig
scp node/systemd/kubelet.service $NODE:/lib/systemd/system/kubelet.service
scp node/etc/kubernetes/kubelet-conf.yaml $NODE:/etc/kubernetes/kubelet-conf.yaml
ssh $NODE 'systemctl enable --now kubelet.service'
done
验证node
[root@k8s-master-node1 /opt/kubernetes-manual/v1.20.5]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-6mxt6 18m kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node1 Approved,Issued
csr-dmpkt 42s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:0cf9be Approved,Issued
csr-l94lc 40s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:0cf9be Approved,Issued
csr-pr6wt 18m kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node3 Approved,Issued
csr-s4mb4 53s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:0cf9be Approved,Issued
csr-vxpl8 18m kubernetes.io/kube-apiserver-client-kubelet system:node:k8s-master-node2 Approved,Issued
[root@k8s-master-node1 /opt/kubernetes-manual/v1.20.5]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master-node1 NotReady master 18m v1.20.5
k8s-master-node2 NotReady master 18m v1.20.5
k8s-master-node3 NotReady master 18m v1.20.5
k8s-worker-node1 NotReady <none> 56s v1.20.5
k8s-worker-node2 NotReady <none> 45s v1.20.5
k8s-worker-node3 NotReady <none> 42s v1.20.5
kubectl get node --selector='!node-role.kubernetes.io/master' | grep '<none>' | awk '{print "kubectl label node " $1 " node-role.kubernetes.io/worker= --overwrite" }' | bash
Kubernetes Core Addons 部署
Kubernetes Proxy
kube-proxy是实现Kubernetes Service资源功能的关键组件,监听API Server的Service与Endpoint资源的事件,并依据资源预期状态透过iptables或ipvs来实现网路转发,而本次安装采用ipvs。
创建proxy的rabc
kubectl apply -f addons/kube-proxy/kube-proxy.rbac.yaml
创建kube-proxy的kubeconfig
CLUSTER_NAME="kubernetes"
KUBE_CONFIG="kube-proxy.kubeconfig"
SECRET=$(kubectl -n kube-system get sa/kube-proxy \
--output=jsonpath='{.secrets[0].name}')
JWT_TOKEN=$(kubectl -n kube-system get secret/$SECRET \
--output=jsonpath='{.data.token}' | base64 -d)
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-context ${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${CLUSTER_NAME} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-credentials ${CLUSTER_NAME} \
--token=${JWT_TOKEN} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config use-context ${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
分发配置并启动kube-proxy
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
scp /etc/kubernetes/kube-proxy.kubeconfig $NODE:/etc/kubernetes/kube-proxy.kubeconfig
scp master/etc/kubernetes/kube-proxy-conf.yaml $NODE:/etc/kubernetes/kube-proxy-conf.yaml
scp master/systemd/kube-proxy.service $NODE:/usr/lib/systemd/system/kube-proxy.service
ssh $NODE 'systemctl enable --now kube-proxy.service'
done
for NODE in ${WORKER_NODES}; do
echo "--- $NODE ---"
scp /etc/kubernetes/kube-proxy.kubeconfig $NODE:/etc/kubernetes/kube-proxy.kubeconfig
scp node/etc/kubernetes/kube-proxy-conf.yaml $NODE:/etc/kubernetes/kube-proxy-conf.yaml
scp node/systemd/kube-proxy.service $NODE:/usr/lib/systemd/system/kube-proxy.service
ssh $NODE 'systemctl enable --now kube-proxy.service'
done
验证
# 检查ipvs规则
for NODE in ${ALL_NODES}; do
echo "--- $NODE ---"
ssh $NODE 'curl -s localhost:10249/proxyMode && echo && ipvsadm -Ln'
done
# kube_proxy 访问正常,和ipvs规则
ipvs
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 wrr
-> 192.168.77.140:6443 Masq 1 0 0
-> 192.168.77.141:6443 Masq 1 0 0
-> 192.168.77.142:6443 Masq 1 0 0
CoreDNS
1.11后CoreDNS已取代Kube DNS作为集群服务发现元件,由于Kubernetes需要让Pod与Pod之间能夠互相通信,然而要能够通信需要知道彼此的IP才行,而这种做法通常是通过Kubernetes API来获取,但是Pod IP会因为生命周期变化而改变,因此这种做法无法弹性使用,且还会增加API Server负担,基于此问题Kubernetes提供了DNS服务来作为查询,让Pod能够以Service名称作为域名来查询IP位址,因此使用者就再不需要关心实际Pod IP,而DNS也会根据Pod变化更新资源记录(Record resources)。
CoreDNS是由CNCF维护的开源DNS方案,该方案前身是SkyDNS,其采用了Caddy的一部分来开发伺服器框架,使其能够建立一套快速灵活的 DNS,而 CoreDNS 每个功能都可以被当作成一個插件的中介软体,如Log、Cache、Kubernetes 等功能,甚至能够将源记录存储在Redis、Etcd中。
部署CoreDNS
kubectl apply -f addons/coredns/
查看 CoreDNS 状态
# kubectl -n kube-system get po -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-689d7d9f49-mfr44 0/1 Pending 0 8s
coredns-689d7d9f49-rpwbr 0/1 Pending 0 8s
Pending的原因是因为节点状态为NotReady, 因为集群网络还没建立呢。
Kubernetes 集群网络
Kubernetes在默认情况下与Docker的网络有所不同。在Kubernetes中有四个问题是需要被解决的,分别为:
- 高耦合的容器到容器通信:通过Pods与Localhost的通信来解决。
- Pod 到 Pod 的通信:通过实现网络模型来解决。
- Pod 到 Service 的通信:由Service objects结合kube-proxy解决。
- 外部到 Service 的通信:一样由Service objects结合kube-proxy解决。
而 Kubernetes 对于任何网络的实现都需要满足以下基本要求(除非是有意调整的网络分段策略):
- 所有容器能够在没有 NAT 的情况下与其他容器通信。
- 所有节点能够在没有 NAT 情况下与所有容器通信(反之亦然)。
- 容器看到的IP与其他人看到的IP是一样的。
庆幸的是Kubernetes已经有非常多的网络模型以网络插件(Network Plugins)方式被实现,因此可以选用满足自己需求的网络功能来使用。另外 Kubernetes 中的网路插件有以下两种形式:
- CNI plugins:以 appc/CNI 标准规范所实现的网络,详细可以阅读CNI Specification。
- Kubenet plugin:使用 CNI plugins 的 bridge 与 host-local 来实现基本的 cbr0。这通常被用在公有云服务上的 Kubernetes 丛集网路。
如果想了解如何选择可以阅读 Chris Love 的Choosing a CNI Network Provider for Kubernetes文章。
部署 CNI plugins
下载二进制文件
wget https://github.com/containernetworking/plugins/releases/download/v0.9.1/cni-plugins-linux-amd64-v0.9.1.tgz
mkdir -p /opt/v1.20.5/bin/cni
tar zxvf cni-plugins-linux-amd64-v0.9.1.tgz -C /opt/v1.20.5/bin/cni
分发二进制文件
for NODE in ${ALL_NODES}; do
echo "--- $NODE ---"
ssh $NODE 'mkdir -p /opt/cni/bin'
scp /opt/v1.20.5/bin/cni/* ${NODE}:/opt/cni/bin/
ssh $NODE 'chmod +x /opt/cni/bin/*'
done
部署网络组件
本次选用 flanner 作为网络组件, 也可以选择 calico
Flannel 是一种简单易行的方式来配置为Kubernetes设计的第三层网络结构。
部署 flanner
wget https://cdn.jsdelivr.net/gh/coreos/flannel@v0.13.0/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
注意: 如果你修改了pod网络,kube-flannel.yml 文件中也要修改。
查看 flannel pods
# kubectl -n kube-system get pods -l app=flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-mh2bl 1/1 Running 0 3m14s
kube-flannel-ds-nfbbr 1/1 Running 0 3m14s
kube-flannel-ds-pgb49 1/1 Running 0 3m14s
kube-flannel-ds-pklzm 1/1 Running 0 3m14s
kube-flannel-ds-qgkck 1/1 Running 0 3m14s
kube-flannel-ds-w45b4 1/1 Running 0 3m14s
完成后,查看节点状态
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master-node1 Ready master 63m v1.20.5
k8s-master-node2 Ready master 63m v1.20.5
k8s-master-node3 Ready master 63m v1.20.5
k8s-worker-node1 Ready worker 45m v1.20.5
k8s-worker-node2 Ready worker 45m v1.20.5
k8s-worker-node3 Ready worker 45m v1.20.5
验证crondns的状态
# kubectl -n kube-system get po -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-fd549c475-9trvg 1/1 Running 0 26s
coredns-fd549c475-vg25v 1/1 Running 0 26s
# apt install -y dnsutils
# dig kubernetes.default.svc.cluster.local +noall +answer @10.96.0.10
; <<>> DiG 9.11.5-P4-5.1+deb10u3-Debian <<>> kubernetes.default.svc.cluster.local +noall +answer @10.96.0.10
;; global options: +cmd
kubernetes.default.svc.cluster.local. 5 IN A 10.96.0.1
部署Kubernetes Extra Addons组件
Dashboard
Metrics Server 是实现了Metrics API的元件,其目标是取代Heapster作为Pod与Node提供资源的Usage metrics,该组件会从每个Kubernetes节点上的Kubelet所公开的Summary API中收集Metrics。
在任意master节点上执行kubectl top命令
# kubectl top node
error: Metrics API not available
发现top指令无法取得Metrics,这表示Kubernetes 丛集没有安装Heapster或是Metrics Server 来提供Metrics API给top指令取得资源使用量。
部署metric-server组件
# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.4.2/components.yaml -O metrics-server.yaml
# sed -i -e 's#k8s.gcr.io/metrics-server#registry.cn-hangzhou.aliyuncs.com/kainstall#g' \
-e '/--kubelet-preferred-address-types=.*/d' \
-e 's/\(.*\)- --secure-port=4443/\1- --secure-port=4443\n\1- --kubelet-insecure-tls\n\1- --kubelet-preferred-address-types=InternalIP,InternalDNS,ExternalIP,ExternalDNS,Hostname/g' \
metrics-server.yaml
# kubectl apply -f metrics-server.yaml
查看聚合的api
# kubectl get apiservices.apiregistration.k8s.io | grep v1beta1.metrics.k8s.io
v1beta1.metrics.k8s.io kube-system/metrics-server True 2m1s
# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s-master-node1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master-node1","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:25Z","window":"30s","usage":{"cpu":"337160596n","memory":"1135592Ki"}},{"metadata":{"name":"k8s-master-node2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master-node2","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:21Z","window":"30s","usage":{"cpu":"1919231688n","memory":"1133944Ki"}},{"metadata":{"name":"k8s-master-node3","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master-node3","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:18Z","window":"30s","usage":{"cpu":"1886326931n","memory":"1115908Ki"}},{"metadata":{"name":"k8s-worker-node1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-worker-node1","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:21Z","window":"30s","usage":{"cpu":"79568534n","memory":"473944Ki"}},{"metadata":{"name":"k8s-worker-node2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-worker-node2","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:15Z","window":"30s","usage":{"cpu":"116956810n","memory":"462436Ki"}},{"metadata":{"name":"k8s-worker-node3","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-worker-node3","creationTimestamp":"2021-04-11T10:07:01Z"},"timestamp":"2021-04-11T10:06:23Z","window":"30s","usage":{"cpu":"66557450n","memory":"479516Ki"}}]}
完成后,等待一段时间收集Metrics,再次执行kubectl top
# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master-node1 338m 22% 1108Mi 59%
k8s-master-node2 1920m 128% 1107Mi 59%
k8s-master-node3 1887m 125% 1089Mi 58%
k8s-worker-node1 80m 5% 462Mi 24%
k8s-worker-node2 117m 7% 451Mi 24%
k8s-worker-node3 67m 4% 468Mi 25%
配置 Ingress Controller
Ingress 是 Kubernetes 中的一个抽象资源,其功能是透过 Web Server 的 Virtual Host 概念以域名(Domain Name)方式转发到内部 Service,这避免了使用 Service 中的 NodePort 与 LoadBalancer 类型所带来的限制(如 Port 数量上限),而实现 Ingress 功能则是透过 Ingress Controller来达成,它会负责监听 Kubernetes API中的 Ingress 与 Service 资源物件,并在发生资源变化时,依据资源预期的结果来设定 Web Server。另外Ingress Controller 有许多实现可以选择:
- Ingress NGINX: Kubernetes 官方维护的,也是本次安装使用的 Controller。
- F5 BIG-IP Controller: F5 所开发的 Controller,它能够让管理员透过 CLI 或 API 从 Kubernetes 与 OpenShift 管理 F5 BIG-IP 设备。
- Ingress Kong: 著名的开源 API Gateway 专案所维护的 Kubernetes Ingress Controller。
- Træfik: 是一套开源的 HTTP 反向代理与负载平衡器。
- Voyager: 一套以 HAProxy 为底的 Ingress Controller。
部署 ingress-nginx
wget https://cdn.jsdelivr.net/gh/kubernetes/ingress-nginx@controller-v0.44.0/deploy/static/provider/baremetal/deploy.yaml -O ingress-nginx.yaml
sed -i -e 's#k8s.gcr.io/ingress-nginx#registry.cn-hangzhou.aliyuncs.com/kainstall#g' \
-e 's#@sha256:.*$##g' ingress-nginx.yaml
kubectl apply -f ingress-nginx.yaml
kubectl wait --namespace ingress-nginx --for=condition=ready pods --selector=app.kubernetes.io/component=controller --timeout=60s
pod/ingress-nginx-controller-67848f7b-2gxzb condition met
官方默认加上了 admission 功能,而我们的 apiserver 使用宿主机的dns,不是coredns,所以连接不上 ingress-nginx Controller 的 service 地址,这里我们把 admission 准入钩子去掉,使我们创建 ingress 资源时,不去验证Controller。
admission webhook 的作用我简单的总结下,当用户的请求到达 k8s apiserver 后,apiserver 根据
MutatingWebhookConfiguration和ValidatingWebhookConfiguration的配置,先调用MutatingWebhookConfiguration去修改用户请求的配置文件,最后会调用ValidatingWebhookConfiguration来验证这个修改后的配置文件是否合法。
kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
配置 Dashboard
Dashboard 是Kubernetes官方开发的基于Web的仪表板,目的是提升管理Kubernetes集群资源便利性,并以资源视觉化方式,来让人更直觉的看到整个集群资源状态。
部署 dashboard
wget https://cdn.jsdelivr.net/gh/kubernetes/dashboard@v2.2.0/aio/deploy/recommended.yaml -O dashboard.yaml
kubectl apply -f dashboard.yaml
部署 ingress
cat << EOF | kubectl apply -f -
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/secure-backends: 'true'
nginx.ingress.kubernetes.io/backend-protocol: 'HTTPS'
nginx.ingress.kubernetes.io/ssl-passthrough: 'true'
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
tls:
- hosts:
- kubernetes-dashboard.cluster.local
secretName: kubernetes-dashboard-certs
rules:
- host: kubernetes-dashboard.cluster.local
http:
paths:
- path: /
backend:
serviceName: kubernetes-dashboard
servicePort: 443
EOF
创建 sa,使用 sa 的 token 进行登录 dashboard
kubectl create serviceaccount kubernetes-dashboard-admin-sa -n kubernetes-dashboard
kubectl create clusterrolebinding kubernetes-dashboard-admin-sa --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard-admin-sa -n kubernetes-dashboard
kubectl describe secrets $(kubectl describe sa kubernetes-dashboard-admin-sa -n kubernetes-dashboard | awk '/Tokens/ {print $2}') -n kubernetes-dashboard | awk '/token:/{print $2}'
eyJhbGciOiJSUzI1NiIsImtpZCI6IkZqLVpEbzQxNzR3ZGJ5MUlpalE5V1pVM0phRVg0UlhCZ3pwdnY1Y0lEZGcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbi1zYS10b2tlbi1sOXhiaCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbi1zYSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImMxYWZiYmEyLTQyMzktNGM3Yy05NjBlLThiZTkwNDY0MzY5MCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbi1zYSJ9.fbZodynYBF8QQOvwj_lzU1wxKiD0HE1CWiyAvp79y9Uu2uQerRMPEuT6KFwFLZ9Pj3be_HTbrDN88im3s-Q2ARpolSACRexMM_nJ2u4pc3MXNEf6e7AJUHB4JnbTsIn5RCSwA8kjYFlWKxX8s1Q8pSKUy_21aMYxuBaqPhzQiuu9RmPBmHkNSYWVncgiPqZWaaadI_l53Jj0KjTMLahG7fqVt2ioTp1ZsIZNaQdNdh8Gzn-SuFCIrNN5oR3bdWNyxbv0OGxrKBHqlVs_8V46ygBc1lyGfpKcA59Wq8-FtIc3zzx531Ix6fDvouJuqHsMxu9VCOFG5mjyYzdsQgemIA
获取 dashboard 的 ingres 连接地址
echo https://$(kubectl get node -o jsonpath='{range .items[*]}{ .status.addresses[?(@.type=="InternalIP")].address} {.status.conditions[?(@.status == "True")].status}{"\n"}{end}' | awk '{if($2=="True")a=$1}END{print a}'):$(kubectl get svc --all-namespaces -o go-template="{{range .items}}{{if eq .metadata.name \"ingress-nginx-controller\" }}{{range.spec.ports}}{{if eq .port "443"}}{{.nodePort}}{{end}}{{end}}{{end}}{{end}}")
https://192.168.77.145:37454
将 host 绑定后,使用token 进行登录
192.168.77.145 kubernetes-dashboard.cluster.local
https://kubernetes-dashboard.cluster.local:37454
配置 etcd 定时备份
这里我们通过 CronJob 资源进行定时备份 etcd 数据到节点目录 /var/lib/etcd/backups 中, 保存最近 30 个备份。
for NODE in ${MASTER_NODES}; do
echo "--- $NODE ---"
ssh $NODE """
cat << EOF > /etc/etcd/etcd-snapshot.sh
export ETCDCTL_API=3
export ETCDCTL_CACERT=/etc/etcd/ssl/etcd-ca.pem
export ETCDCTL_CERT=/etc/etcd/ssl/etcd.pem
export ETCDCTL_KEY=/etc/etcd/ssl/etcd-key.pem
export ETCDCTL_ENDPOINTS=https://127.0.0.1:2379
backup_path="/var/lib/etcd/backup"
[ ! -d \\\${backup_path} ] && mkdir -p \\\${backup_path}
etcdctl snapshot save \\\${backup_path}/etcd-snapshot-\\\$(date +%Y-%m-%d_%H:%M:%S_%Z).db
echo delete old backups
find \\\${backup_path:-/tmp/123} -type f -mtime +30 -exec rm -fv {} \\\;
EOF
echo '*/5 * * * * root bash /etc/etcd/etcd-snapshot.sh' >> /etc/crontab
"""
done
测试集群
重启集群
- 将 集群节点 全部重启
- 获取节点信息
# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master-node1 Ready master 170m v1.20.5
k8s-master-node2 Ready master 170m v1.20.5
k8s-master-node3 Ready master 170m v1.20.5
k8s-worker-node1 Ready worker 152m v1.20.5
k8s-worker-node2 Ready worker 152m v1.20.5
k8s-worker-node3 Ready worker 152m v1.20.5
部署 whoami app
部署应用
cat <<EOF | kubectl apply -f -
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-demo-app
labels:
app: ingress-demo-app
spec:
replicas: 2
selector:
matchLabels:
app: ingress-demo-app
template:
metadata:
labels:
app: ingress-demo-app
spec:
containers:
- name: whoami
image: traefik/whoami:v1.6.1
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ingress-demo-app
spec:
type: ClusterIP
selector:
app: ingress-demo-app
ports:
- name: http
port: 80
targetPort: 80
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-demo-app
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: app.demo.com
http:
paths:
- path: /
backend:
serviceName: ingress-demo-app
servicePort: 80
EOF
获取应用的pods
# kubectl get pods -l app=ingress-demo-app
NAME READY STATUS RESTARTS AGE
ingress-demo-app-694bf5d965-69v42 1/1 Running 0 68s
ingress-demo-app-694bf5d965-7qt5p 1/1 Running 0 68s
通过 ingress 访问
echo http://$(kubectl get node -o jsonpath='{range .items[*]}{ .status.addresses[?(@.type=="InternalIP")].address} {.status.conditions[?(@.status == "True")].status}{"\n"}{end}' | awk '{if($2=="True")a=$1}END{print a}'):$(kubectl get svc --all-namespaces -o go-template="{{range .items}}{{if eq .metadata.name \"ingress-nginx-controller\" }}{{range.spec.ports}}{{if eq .port "80"}}{{.nodePort}}{{end}}{{end}}{{end}}{{end}}")
http://192.168.77.145:40361
kubectl get pods -n ingress-nginx -l app.kubernetes.io/component=controller -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx-controller-67848f7b-sx7mf 1/1 Running 0 97m 10.244.5.6 k8s-worker-node3 <none> <none>
# curl -H 'Host:app.demo.com' http://192.168.77.145:40361
Hostname: ingress-demo-app-694bf5d965-7qt5p
IP: 127.0.0.1
IP: 10.244.5.8
RemoteAddr: 10.244.5.6:38674
GET / HTTP/1.1
Host: app.demo.com
User-Agent: curl/7.64.0
Accept: */*
X-Forwarded-For: 10.244.5.1
X-Forwarded-Host: app.demo.com
X-Forwarded-Port: 80
X-Forwarded-Proto: http
X-Real-Ip: 10.244.5.1
X-Request-Id: 90f14481aacd9ab5a1ef20d6113ddbe0
X-Scheme: http
从 whoami 应用返回单额信息可以看到,我们通过 ingress 访问到了 whomai app。
重置集群
安装有问题的时候,可以使用下列命令重置集群
kubeadm reset -f
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
ipvsadm --clear
systemctl stop kubelet
docker rm -f -v $(docker ps -q)
find /var/lib/kubelet | xargs -n 1 findmnt -n -t tmpfs -o TARGET -T | uniq | xargs -r umount -v
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd ~/.kube/config