事故出现时候的处理流程及文档记录。
事故处理流程
基本原则: 在故障处理过程中采取的所有手段和行动,一切以恢复业务为最高优先级。
流程机制
- 故障发现后,On-Call 的 SRE 或 运维,故障指挥官 有权召集相应的业务开发或其它必要资源,快速组织 事故处理小组。
- 如果问题和恢复过程非常明确,故障指挥官 仍然是 SRE 或 运维,就不做转移,由他来指挥每个人要做的具体事情,以优先恢复业务优先。
- 如果问题疑难,影响范围很大,这时 SRE 可以要求更高级别的主管介入,比如 SRE 主管或总监等,一般的原则是谁的业务受影响最大,谁来牵头组织。这时 SRE 要将 故障指挥官 的职责转移给更高级别的主管,如果是全站范围的影响,必要时技术 VP 或 CTO 也可以承担 故障指挥官 职责,或者授权给某位总监承担。
- 问题解决后,需要进行功能验证。
详细流程图
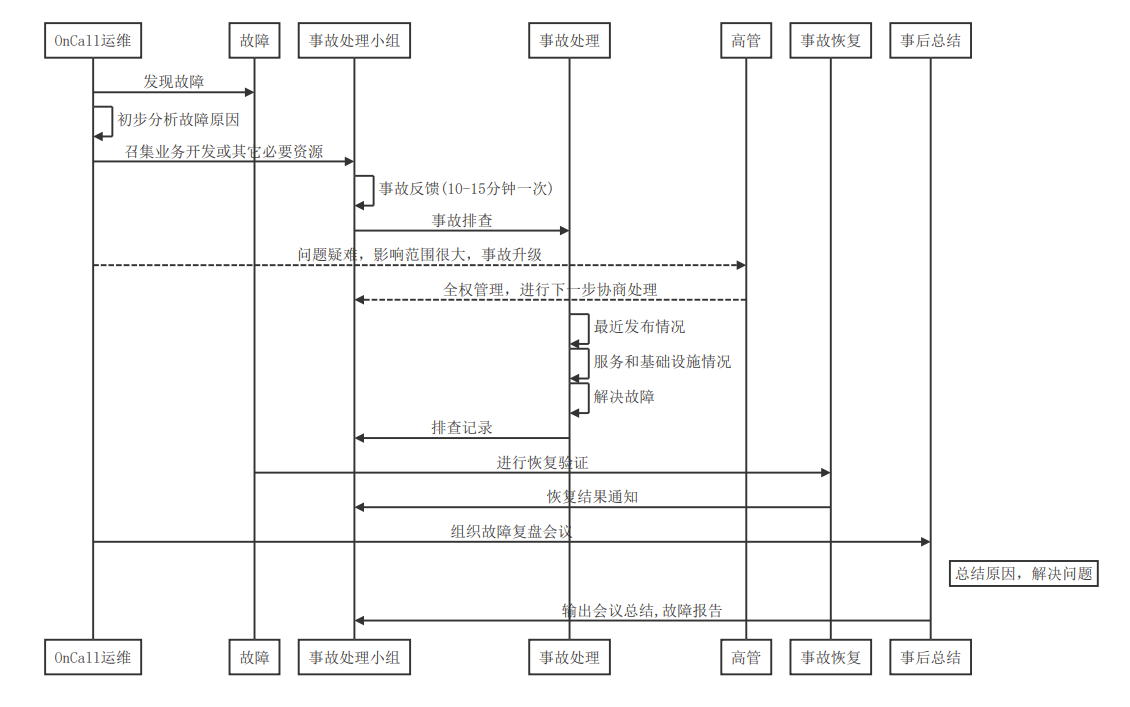
```sequence
OnCall运维->故障:发现故障
OnCall运维->OnCall运维: 初步分析故障原因
OnCall运维->事故处理小组: 召集业务开发或其它必要资源
事故处理小组->事故处理小组: 事故反馈(10-15分钟一次)
事故处理小组->事故处理: 事故排查
OnCall运维-->高管: 问题疑难,影响范围很大,事故升级
高管-->事故处理小组: 全权管理,进行下一步协商处理
事故处理->事故处理: 最近发布情况
事故处理->事故处理: 服务和基础设施情况
事故处理->事故处理: 解决故障
事故处理->事故处理小组: 排查记录
故障->事故恢复: 进行恢复验证
事故恢复->事故处理小组: 恢复结果通知
OnCall运维->事后总结: 组织故障复盘会议
Note right of 事后总结: 总结原因,解决问题
事后总结->事故处理小组: 输出会议总结,故障报告
```
事故业务现象
由谁在什么时间点报什么问题,尽量详细,比如设备id,用户id等
事故发生频率
偶发 or 必现
事故复现方法
方便大家复现。
事故时间流记录
以事件时间流的方式记录出现事故前,事故中的操作记录
注:时间能精确就精确
记录人: (由指定人记录)
| 时间 | 事件 | 操作人 | 备注 |
|---|---|---|---|
| 2021/09/28 12:20:20 | 将LB带宽从10Mb到20Mb | ||
事故处理小组
由事故响应者组织一个事故小组群。方便沟通。
建立专门的应急群,将这些事故产品的关键角色纳入其中,当有故障发生时会第一时间在群通报。
事故反馈
一般要求以团队为单位,每隔 10~15 分钟做一次反馈,反馈当前处理进展以及下一步Action,如果中途有需要马上执行什么操作,也要事先通报,并且要求通报的内容包括对业务和系统的影响是什么,最后由 故障指挥官 决策后再执行,避免忙中出错。没有进展也是进展,也要及时反馈。
事故排查
最近发布信息
可以包括最后一次发布的系统的commitId,时间,人员等。
测试反馈
测试人员对本次故障处理的反馈。方便开发人员查问题。
| 时间 | 测试用例 | 结果 | 记录人 | 备注 |
|---|---|---|---|---|
| 9/28 11点左右 | 在APP上登录 | 成功 | 张三 | |
| 9/28 11点左右 | 在设备上登录 | 失败 | 李四 | |
服务情况
在团队每个服务都应该有相应的owner。在出现线上故障,每个owner负责检查自己负责的服务的情况。检查过程的证件必须保留证据。
| 时间 | 服务名 | 检查内容及结果 | 目前状态 | 检查人 | 备注 |
|---|---|---|---|---|---|
| 9/28 10:30 | echo | values配置正确应用的版本:v2.1cpu,内存 同比环比正常 应用配置正确 ERROR级别从9/28 7点突增。 | 张三 | ||
基础设施情况
基础设施的排查由基础设施团队负责。
| 时间 | 组件 | 检查内容 | 目前状态 | 检查人 | 备注 |
|---|---|---|---|---|---|
| 9/28 10:00 | LB | 带宽包流速 | |||
| 9/28 10:00 | NAT | ||||
| 9/28 10:00 | Redis | ||||
| 9/28 10:00 | PostgreSQL | ||||
| 9/28 11:00 | 域名解析 |
事故排查记录
“假设”指的是排查人员对于故障原因的假设。
此表的作用是避免不同的人重复排查同一个假设。同时,也方便其他人验证。
| 时间 | 假设 | 排查方法 | 结果 | 排查人 | 备注 |
|---|---|---|---|---|---|
| 9/28 10:00 | 登录环节出现业务逻辑错误 | ||||
事故恢复
事故修复后的验证流程
恢复验证
由测试和产品一起验证业务功能是否正常。
| 时间 | 测试用例 | 结果 | 记录人 | 备注 |
|---|---|---|---|---|
| 9/28 11点左右 | 在APP上登录 | 成功 | 张三 | |
| 9/28 11点左右 | 在设备上登录 | 成功 | 李四 | |
事后总结
复盘会议
那必须开个会,聊聊天。
黄金三问:
- 第一问:故障原因有哪些?
- 第二问:我们做什么,怎么做才能确保下次不会再出现类似故障?
- 第三问:当时如果我们做了什么,可以用更短的时间恢复业务?
预防处理
既然开会,那必须要有预防方案了。
事后Action
事后action可以和看板系统结合,方便跟踪。action必须是可执行的,准确的
| Action | 执行人 | 验证人 | 计划完成时间 | 完成时间 |
|---|---|---|---|---|
文档可以在Github中下载: https://github.com/lework/lework.github.io/tree/master/_posts/2021/2021-10-15-incident_handling.md
参考
- https://mp.weixin.qq.com/s/Dh8R6gFLgwz0qQCItBjr1g
- https://lework.github.io/2020/08/16/sre/
- https://lework.github.io/2021/03/10/fr/