eBPF 是怎么工作的?
eBPF 程序以内核事件触发的方式运行,并且其运行过程包括编译、加载、验证和内核态执行等。为了保护内核的安全和稳定,如果编译后 BPF 字节码中包含了不安全的操作,验证阶段会直接拒绝 BPF 程序的执行。
通常我们借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字
节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行。
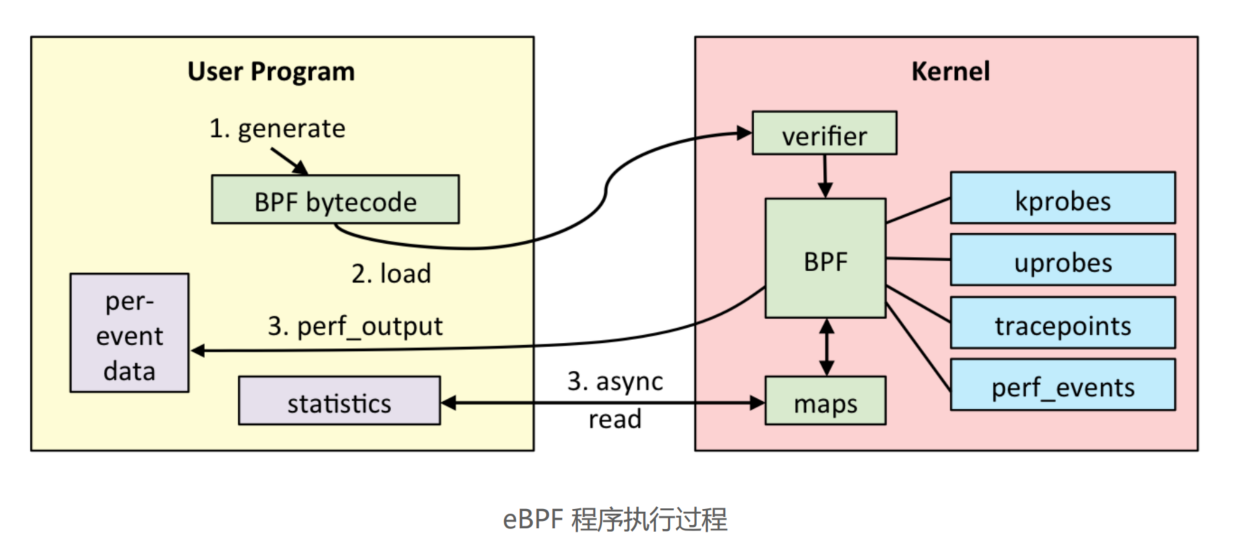
一个完整的 eBPF 程序通常包含用户态和内核态两部分。其中,用户态负责 eBPF 程序的加载、事件绑定以及 eBPF 程序运行结果的汇总输出;内核态运行在 eBPF 虚拟机中,负责定制和控制系统的运行状态。
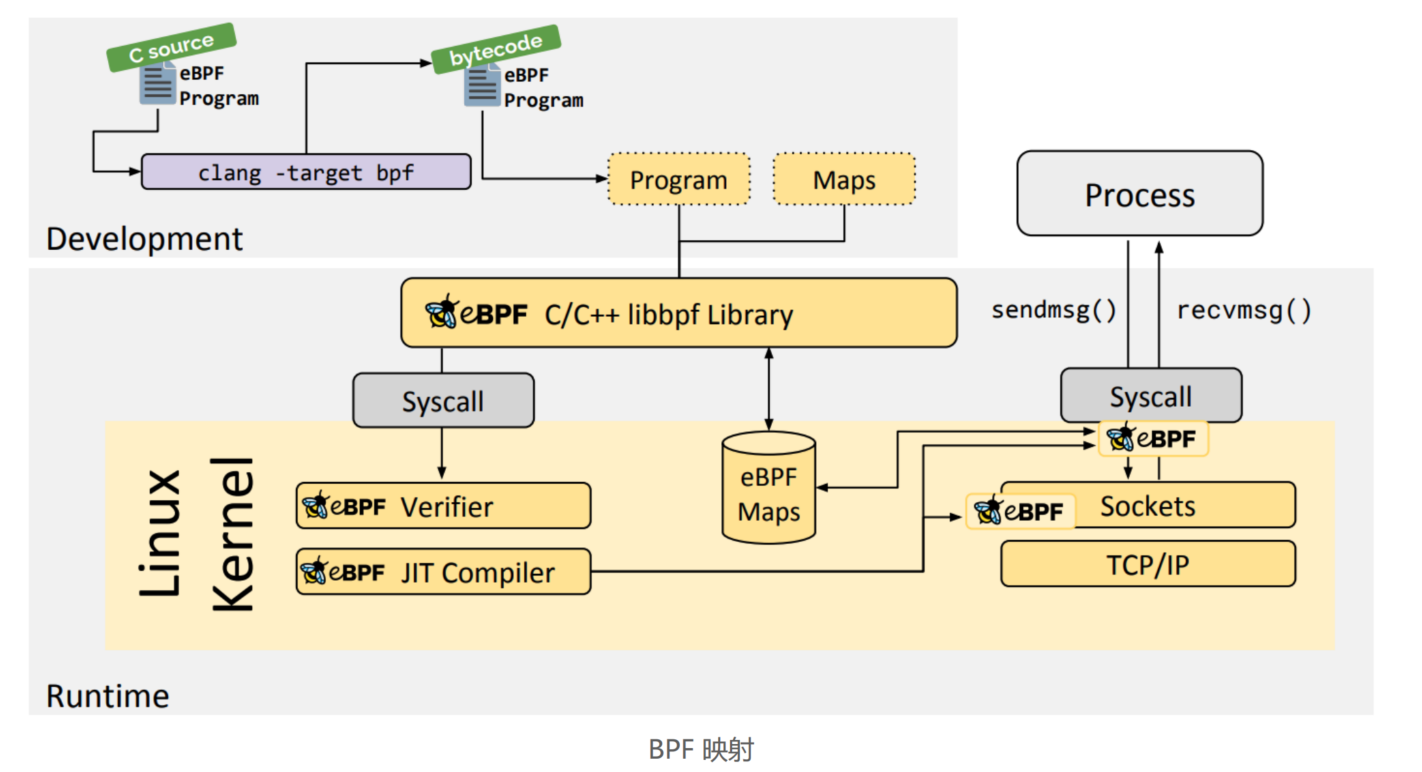
- 第一步,使用 C 语言开发一个 eBPF 程序;
- 第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 第三步,通过 bpf 系统调用,把 BPF 字节码提交给内核;
- 第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
- 第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
eBPF 限制
- eBPF 程序必须被验证器校验通过后才能执行,且不能包含无法到达的指令;
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数;
- eBPF 程序栈空间最多只有 512 字节,想要更大的存储,就必须要借助映射存储;
- 在内核 5.2 之前,eBPF 字节码最多只支持 4096 条指令,而 5.2 内核把这个限制提高到了 100 万条;
- 由于内核的快速变化,在不同版本内核中运行时,需要访问内核数据结构的 eBPF 程序很可能需要调整源码,并重新编译。
eBPF 程序
开发环境
# ubuntu
sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)
# redhat
sudo yum install libbpf-devel make clang llvm elfutils-libelf-devel bpftool bcc-tools bcc-devel
hello,world
# hello.c
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World!");
return 0;
}
# hello.py
#!/usr/bin/env python3
# 1) import bcc library
from bcc import BPF
# 2) load BPF program
b = BPF(src_file="hello.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4) read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
# 输出
b' cat-10656 [006] d... 2348.114455: bpf_trace_printk: Hello, World!'
# trace-open.c
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射
BPF_PERF_OUTPUT(events);
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how)
{
struct data_t data = { };
// 获取PID和时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
# trace-open.py
from bcc import BPF
# 1) load BPF program
b = BPF(src_file="trace-open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 2) print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# 3) define the callback for perf event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 4) loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
# 输出
TIME(s) COMM PID FILE
2.384485400 b'irqbalance' 991 b'/proc/interrupts'
2.384750400 b'irqbalance' 991 b'/proc/stat'
2.384838400 b'irqbalance' 991 b'/proc/irq/0/smp_affinity'
do_sys_openat2() 是系统调用 opennat() 在内核的实现
输出的格式选项 /sys/kernel/debug/tracing/trace_options
标准输出 /sys/kernel/debug/tracing/trace_pipe
bpf_get_current_pid_tgid 用于获取进程的 TGID 和 PID。因为这儿定义的 data.pid 数据类型为 u32,所以高 32 位舍弃掉后就是进程的 PID;
bpf_ktime_get_ns 用于获取系统自启动以来的时间,单位是纳秒;
bpf_get_current_comm 用于获取进程名,并把进程名复制到预定义的缓冲区中;
bpf_probe_read 用于从指定指针处读取固定大小的数据,这里则用于读取进程打开的文件名。
在 BCC 中,与 eBPF 程序中 BPF_PERF_OUTPUT 相对应的用户态辅助函数是 open_perf_buffer() 。
eBPF虚拟机是如何工作的?
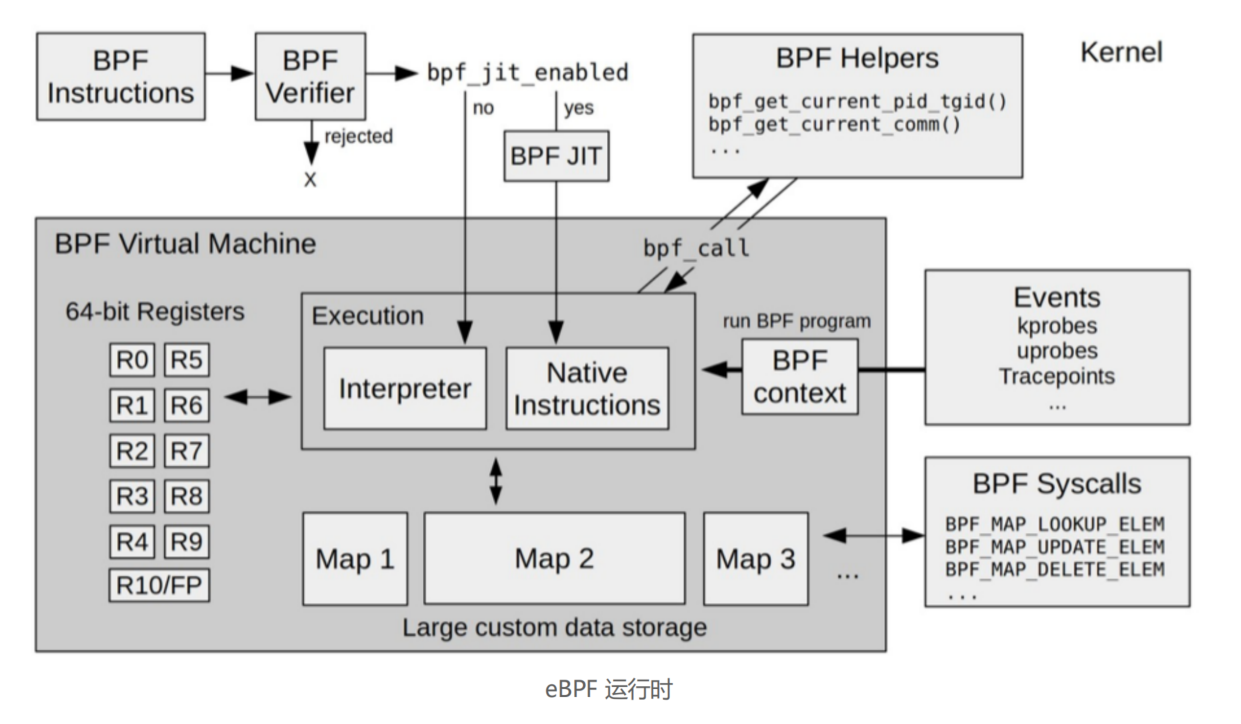
第一个模块是 eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。
第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
第五个模块是 BPF 映射(map),它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
导出 eBPF 程序的指令 bpftool prog dump xlated id 89
导出 eBPF 程序的机器指令bpftool prog dump jited id 89
跟踪bpf系统调用 strace -v -f -ebpf ./hello.py
BPF 与性能事件的绑定过程分为以下几步:
- 首先,借助 bpf 系统调用,加载 BPF 程序,并记住返回的文件描述符;
- 然后,查询 kprobe 类型的事件编号。BCC 实际上是通过 /sys/bus/event_source/devices/kprobe/type 来查询的;
- 接着,调用 perf_event_open 创建性能监控事件。比如,事件类型(type 是上一步查询到的 6)、事件的参数( config1 包含了内核函数 do_sys_openat2 )等;
- 最后,再通过 ioctl 的 PERF_EVENT_IOC_SET_BPF 命令,将 BPF 程序绑定到性能监控事件。、
eBPF 程序跟内核交互的基本方法
一个完整的 eBPF 程序通常包含用户态和内核态两部分:用户态程序通过 BPF 系统调用,完成 eBPF 程序的加载、事件挂载以及映射创建和更新,而内核态中的 eBPF 程序则需要通过 BPF 辅助函数完成所需的任务。
bpf 系统调用
BPF 系统调用的调用格式
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
第一个,cmd ,代表操作命令,比如上一讲中我们看到的 BPF_PROG_LOAD 就是加载eBPF 程序;
第二个,attr,代表 bpf_attr 类型的 eBPF 属性指针,不同类型的操作命令需要传入不同的属性参数;
第三个,size ,代表属性的大小。
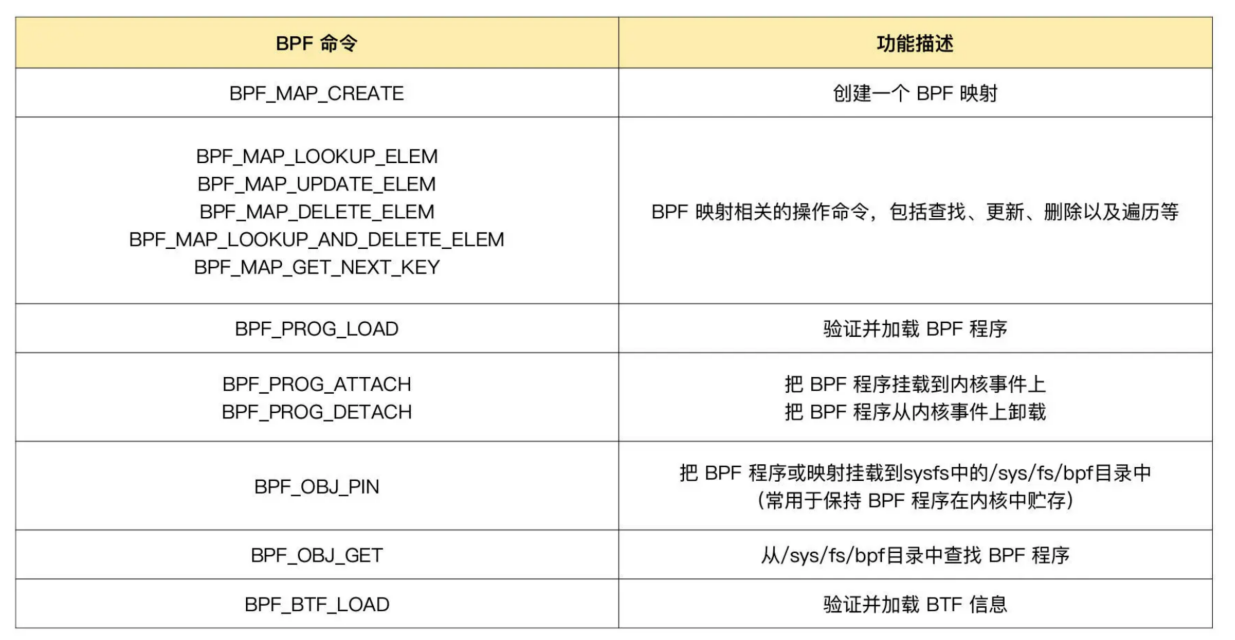
用户程序中常用的命令
文件 include/uapi/linux/bpf.h 中 bpf_cmd 的定义。
bpf辅助函数
eBPF 程序并不能随意调用内核函数,因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互。
bpftool feature probe ,来查询当前系统支持的辅助函数列表
常用的辅助函数
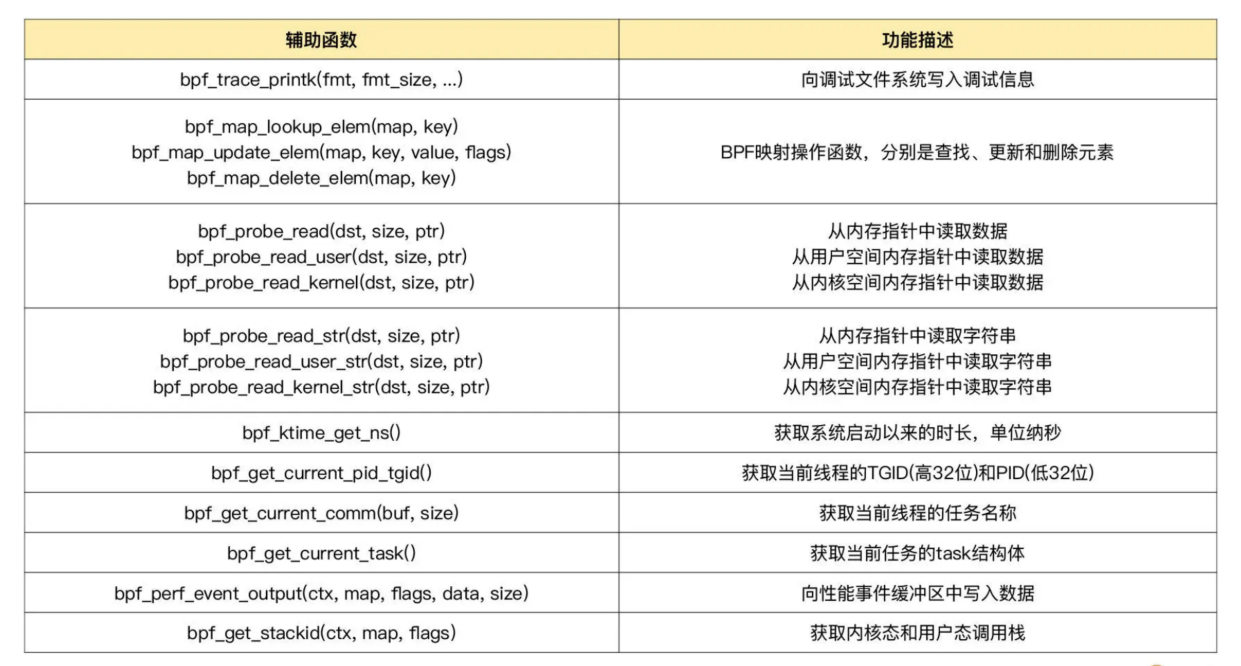
bpf 映射
BPF 映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态。eBPF 程序最多可以访问 64 个不同的 BPF 映射,并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态。
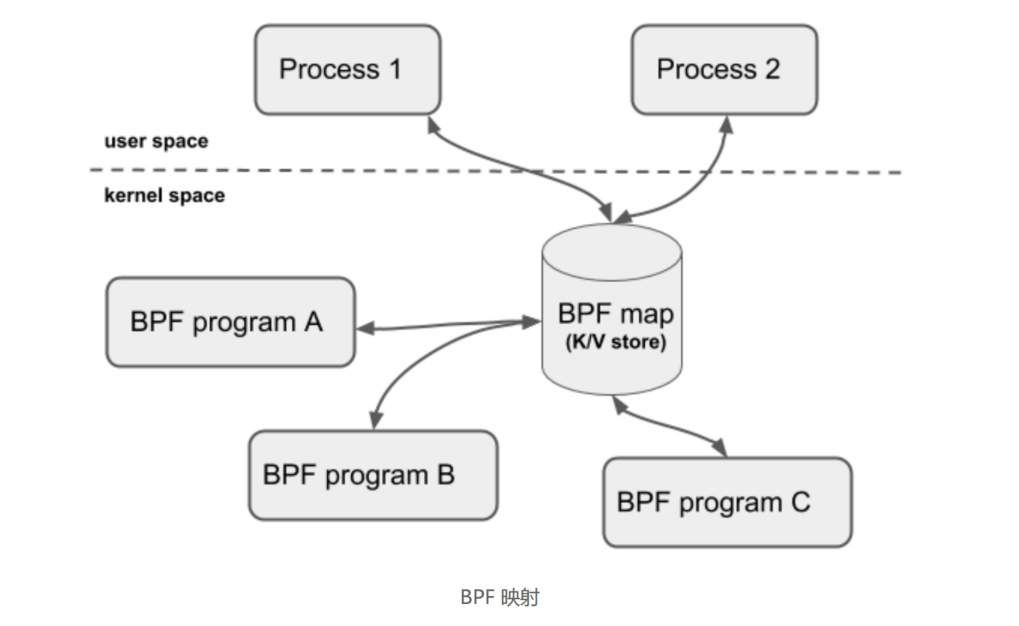
BPF 辅助函数中并没有 BPF 映射的创建函数,BPF 映射只能通过用户态程序的系统调用来创建。
内核头文件 include/uapi/linux/bpf.h 中的 bpf_map_type 定义了所有支持的映射类型
| bpftool feature probe | grep map_type 查询系统支持那些映射 |
常见的映射
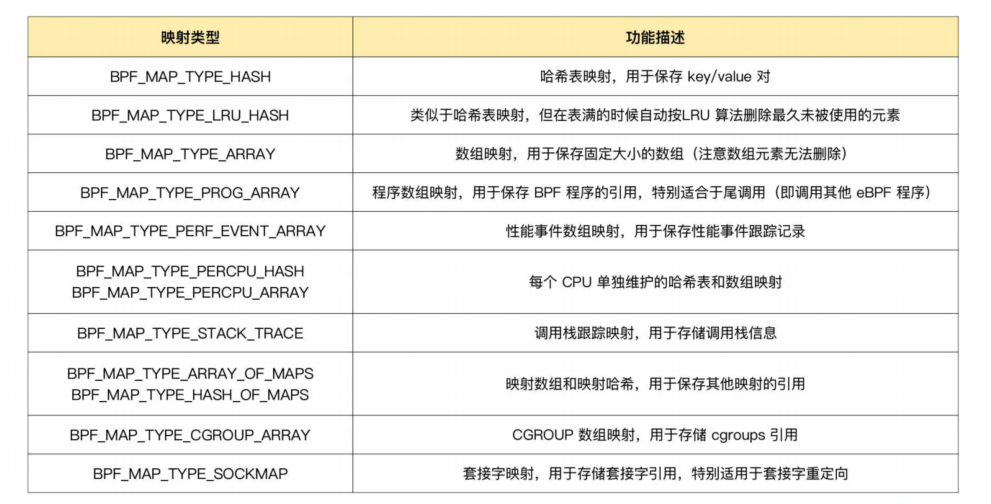
BPF 映射会在用户态程序关闭文件描述符的时候自动删除(即close(fd) )。如果你想在程序退出后还保留映射,就需要调用 BPF_OBJ_PIN 命令,将映射挂载到/sys/fs/bpf 中。
调试bpf映射代码
//创建一个哈希表映射,并挂载到/sys/fs/bpf/stats_map(Key和Value的大小都是2字节)
bpftool map create /sys/fs/bpf/stats_map type hash key 2 value 2 entries 8 name stats_map
//查询系统中的所有映射
bpftool map
//示例输出
//340: hash name stats_map flags 0x0
// key 2B value 2B max_entries 8 memlock 4096B
//向哈希表映射中插入数据
bpftool map update name stats_map key 0xc1 0xc2 value 0xa1 0xa2
//查询哈希表映射中的所有数据
bpftool map dump name stats_map
//示例输出
//key: c1 c2 value: a1 a2
//Found 1 element
BPF 类型格式 (BTF)
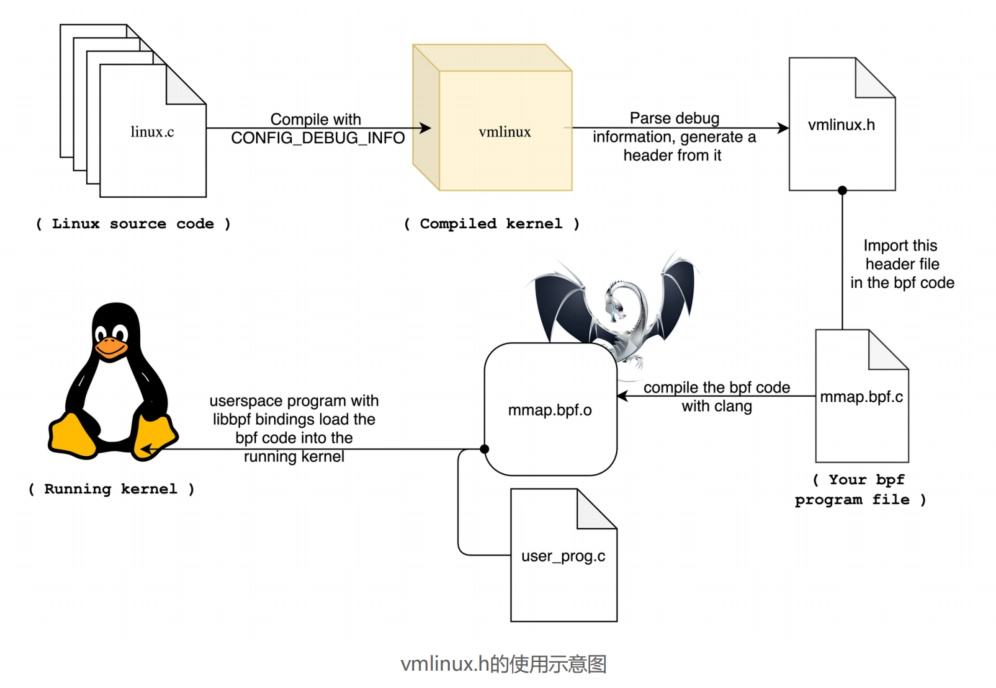
导出数据结构定义 bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
bpf 程序
查询当前系统支持的程序类型 bpftool feature probe | grep program_type
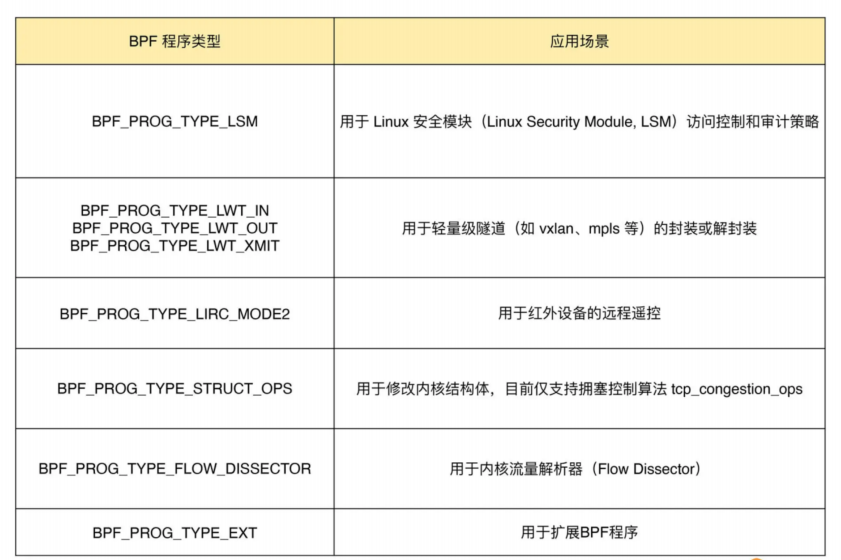
程序类型大致可以划分为三类:
- 第一类是跟踪,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么。
- 第二类是网络,即对网络数据包进行过滤和处理,以便了解和控制网络数据包的收发过程。
- 第三类是除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等。
跟踪类 eBPF 程序主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。
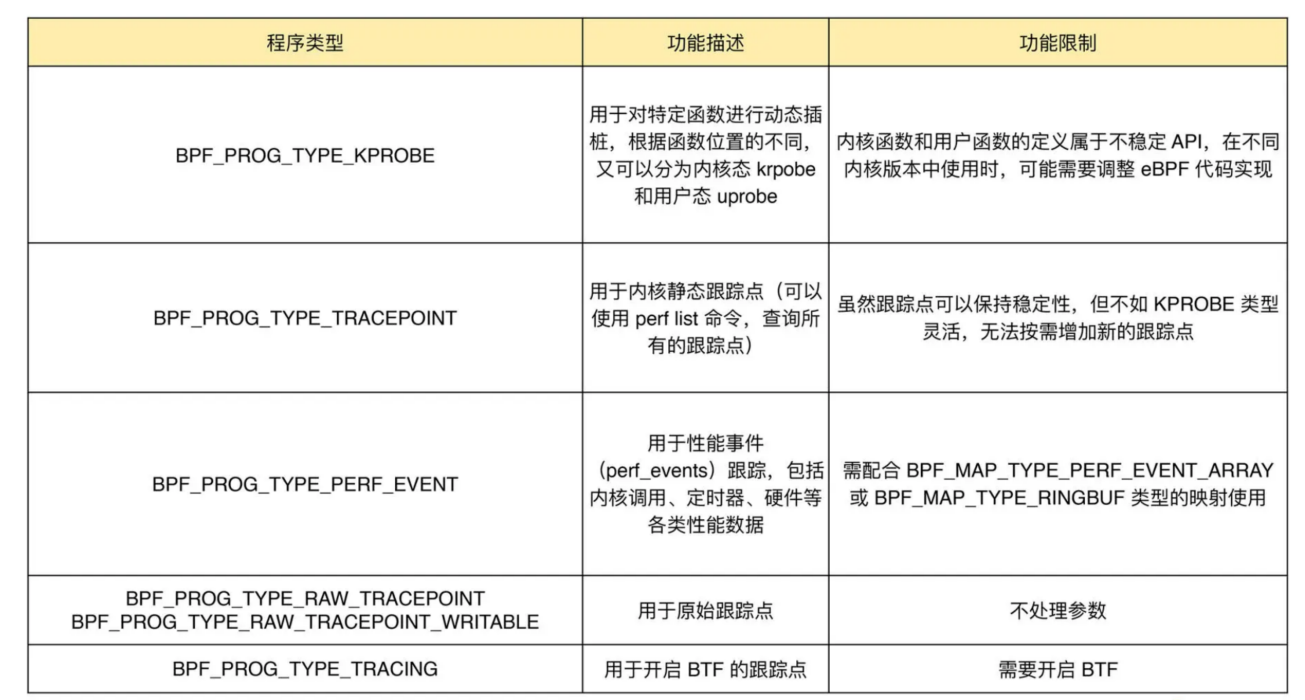
网络类 eBPF 程序主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。
根据事件触发位置的不同,网络类 eBPF 程序又可以分为 XDP(eXpress Data Path,高速数据路径)程序、TC(Traffic Control,流量控制)程序、套接字程序以及 cgroup 程序
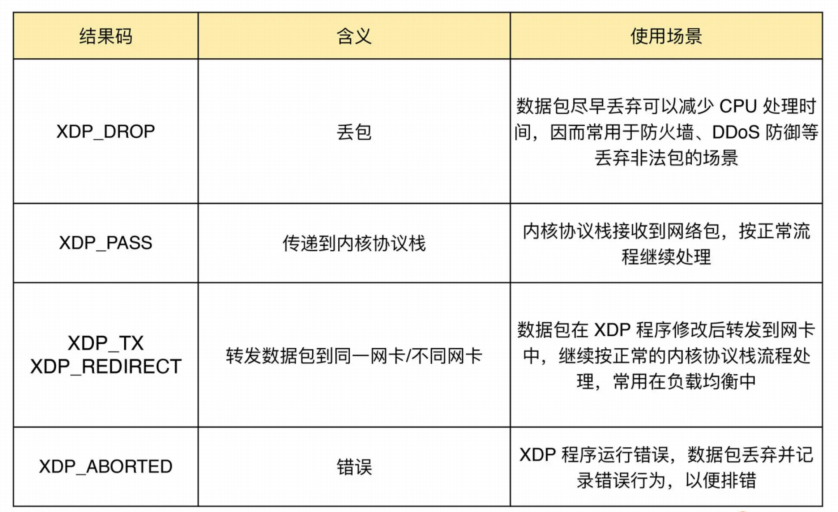
XDP 程序的类型定义为 BPF_PROG_TYPE_XDP,它在网络驱动程序刚刚收到数据包时触发执行。由于无需通过繁杂的内核网络协议栈,XDP 程序可用来实现高性能的网络处理方案,常用于 DDoS 防御、防火墙、4 层负载均衡等场景。
XDP 运行模式可以分为下面这三种:
通用模式。它不需要网卡和网卡驱动的支持,XDP 程序像常规的网络协议栈一样运行在内核中,性能相对较差,一般用于测试;
原生模式。它需要网卡驱动程序的支持,XDP 程序在网卡驱动程序的早期路径运行;
卸载模式。它需要网卡固件支持 XDP 卸载,XDP 程序直接运行在网卡上,而不再需要消耗主机的 CPU 资源,具有最好的性能。
XDP 程序结果码
除了上面的跟踪和网络 eBPF 程序之外,Linux 内核还支持很多其他的类型。这些类型的eBPF 程序虽然不太常用,但在需要的时候也可以帮你解决很多特定的问题。
调试bpf程序
查询 execve 系统调用的参数格式:
sudo mount -t debugfs debugfs /sys/kernel/debug
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/format
使用 bpftrace 调试
# Ubuntu 19.04
sudo apt-get install -y bpftrace
# RHEL8/CentOS8
sudo dnf install -y bpftrace
# 查询所有内核插桩和跟踪点
sudo bpftrace -l
# 使用通配符查询所有的系统调用跟踪点
sudo bpftrace -l 'tracepoint:syscalls:*'
# 使用通配符查询所有名字包含"execve"的跟踪点
sudo bpftrace -l '*execve*'
查询系统调用 execve 入口参数(对应系统调用sys_enter_execve)和返回值(对应系统调用sys_exit_execve)的示例:
# 查询execve入口参数格式
$ sudo bpftrace -lv tracepoint:syscalls:sys_enter_execve
tracepoint:syscalls:sys_enter_execve
int __syscall_nr
const char * filename
const char *const * argv
const char *const * envp
# 查询execve返回值格式
$ sudo bpftrace -lv tracepoint:syscalls:sys_exit_execve
tracepoint:syscalls:sys_exit_execve
int __syscall_nr
long ret
内核跟踪
bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序;
BCC 通常用在开发复杂的 eBPF 程序中,它内置的各种小工具也是目前应用最为广泛的eBPF 小程序;
libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,不再需要在每台机器上都安装 LLVM 和内核头文件。
排查应用程序
readelf 命令
# 查询符号表(RHEL8系统中请把动态库路径替换为/usr/lib64/libc.so.6)
readelf -Ws /usr/lib/x86_64-linux-gnu/libc.so.6
# 查询USDT信息(USDT信息位于ELF文件的notes段)
readelf -n /usr/lib/x86_64-linux-gnu/libc.so.6
bpftrace 工具
# 查询uprobe(RHEL8系统中请把动态库路径替换为/usr/lib64/libc.so.6)
bpftrace -l 'uprobe:/usr/lib/x86_64-linux-gnu/libc.so.6:*'
# 查询USDT
bpftrace -l 'usdt:/usr/lib/x86_64-linux-gnu/libc.so.6:*'
想要通过二进制文件查询符号表和参数定义,必须在编译的时候保留 DWARF 调试信息。
uprobe 是基于文件的。当文件中的某个函数被跟踪时,除非对进程 PID 进行了过滤,默认所有使用到这个文件的进程都会被插桩。
跟踪编译型语言应用程序
在跟踪函数参数和返回值时,你需要首先区分编程语言的调用规范,然后再去寄存器或堆栈中读取函数的参数和返回值。
来跟踪 Bash
# Ubuntu
sudo apt install bash-dbgsym
# RHEL
sudo debuginfo-install bash
查询符号表
# 第一步,查询 Build ID(用于关联调试信息)
readelf -n /usr/bin/bash | grep 'Build ID'
# 输出示例为:
# Build ID: 7b140b33fd79d0861f831bae38a0cdfdf639d8bc
# 第二步,找到调试信息对应的文件(调试信息位于目录/usr/lib/debug/.build-id中,上一步中得到
ls /usr/lib/debug/.build-id/7b/140b33fd79d0861f831bae38a0cdfdf639d8bc.debug
# 第三步,从调试信息中查询符号表
readelf -Ws /usr/lib/debug/.build-id/7b/140b33fd79d0861f831bae38a0cdfdf639d8bc
跟踪 readline
sudo bpftrace -e 'uretprobe:/usr/bin/bash:readline { printf("User %d executed \"%s\" command\n", uid, str(retval)); }'
跟踪解释型语言应用程序
sudo bpftrace -l '*:/usr/bin/python3:*'
sudo bpftrace -e 'usdt:/usr/bin/python3:function__entry { printf("%s:%d %s\n", str(arg0), arg2, str(arg1))}'
跟踪即时编译型语言应用程序
用户进程的跟踪,本质上是通过断点去执行 uprobe 处理程序。
排查网络问题
跟踪内核网络协议栈
跟踪调用栈,根据调用栈回溯路径,找出导致某个网络事件发生的整个流程,进而就可以再根据这些流程中的内核函数进一步跟踪。
跟踪 kfree_skb 的内核调用栈
sudo bpftrace -e 'kprobe:kfree_skb /comm=="curl"/ {printf("kstack: %s\n", kstack);}'
跟踪新创建的进程
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%-6d %-8s", pid, comm); join(args->argv);}'
# 查询容器进程在主机命名空间中的PID
PID=$(docker inspect -f '{{.State.Pid}}' bash)
# 查询uprobe
sudo bpftrace -l "uprobe:/proc/$PID/root/usr/bin/bash:*"
# 跟踪bash:readline的结果
sudo bpftrace -e "uretprobe:/proc/$PID/root/usr/bin/bash:readline { printf(\"User %d executed %s in container\n\", uid, str(retval)); }"