Welcome to Lework's Blog!
这里记录着我的运维学习之路-
学习周报「2025」04月
以每周一个节点,记录知识点。
2025-04-28~30
K8S 中的 NodePort 服务在 NAT 环境下的访问问题
在 Kubernetes 集群中使用 NodePort 类型的服务时,可能会遇到这样的情况:同一时间,部分客户端可以正常访问服务,而另一部分客户端却无法访问。特别是当客户端位于 NAT 网络环境中时,这个问题更为明显。
问题原因:
这个问题主要与 Linux 内核的两个参数设置有关:
net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_timestamps = 1当这两个参数同时被启用时,会对 NAT 网络环境产生不良影响。
技术原理:
在 K8S 工作节点上,可以通过 sysctl 命令查看这两个参数的设置:
$ sysctl net.ipv4.tcp_tw_recycle net.ipv4.tcp_tw_recycle = 1 $ sysctl net.ipv4.tcp_timestamps net.ipv4.tcp_timestamps = 1当这两个参数都启用时会发生什么:
tcp_timestamps参数启用后,TCP 连接会记录数据包的时间戳信息tcp_tw_recycle参数启用后,服务器会使用时间戳机制来快速回收处于 TIME_WAIT 状态的连接- 在 NAT 环境中,多个客户端会共享同一个外部 IP 地址
- 服务器会按照每个源 IP 地址(Per-Host)记录并更新最近接收到的时间戳
- 由于 NAT 后面的不同客户端系统启动时间不同,它们的时间戳也会不同
- 服务器会将时间戳记录更新为最大值,导致时间戳较小的客户端发送的数据包被视为”过期重复数据”而被丢弃
解决方法:
最简单的解决方法是在 Kubernetes 工作节点上禁用
tcp_tw_recycle参数:sysctl -w net.ipv4.tcp_tw_recycle=0并将此设置永久保存到
/etc/sysctl.conf文件中:net.ipv4.tcp_tw_recycle = 0注意事项:
在现代 Linux 内核中(特别是 4.12 版本之后),
tcp_tw_recycle参数已被移除,因为它会导致此类 NAT 环境下的连接问题。如果您正在使用较新的内核版本,可能不会遇到此问题。参考:
- https://www.sdnlab.com/17530.html
-
新手指南:如何优化 AI 提示词,让大模型更懂你的心
一、提示词(Prompt)的魔力
在人工智能时代,提示词就像是打开 AI 宝库的钥匙。无论你使用 ChatGPT、Claude 还是其他大语言模型,一个精心设计的提示词能让你得到质量更高、更符合期望的回答。正如搜索结果中提到的:”你得到的输出,往往取决于你输入的 Prompt。”
提示词不仅仅是技巧,它是一种艺术,是AI时代的沟通桥梁。好的提示词能显著提高问题解答的质量与效率,而这种技能适用于所有大模型产品。
-
使用 Cursor 快速开发 Dify 插件:Kafka 消息发送工具
前言
在这篇教程中,我将带领大家使用 Cursor IDE 快速开发一个 Dify 插件,实现向 Kafka topic 发送消息的功能。Cursor 内置的 AI 辅助功能能够显著提升开发效率,特别适合插件快速开发场景。无论你是否有 Python 开发经验,只要按照步骤操作,都能轻松完成。
如果你没有 Cursor,也可以使用 Copilot, Trae Cline 等可以使用 Claude-3.7-sonnet AI 模型的工具。
-
通过 Dify 来分析 Kubernetes Pod 资源指标
效果展示
先看效果:
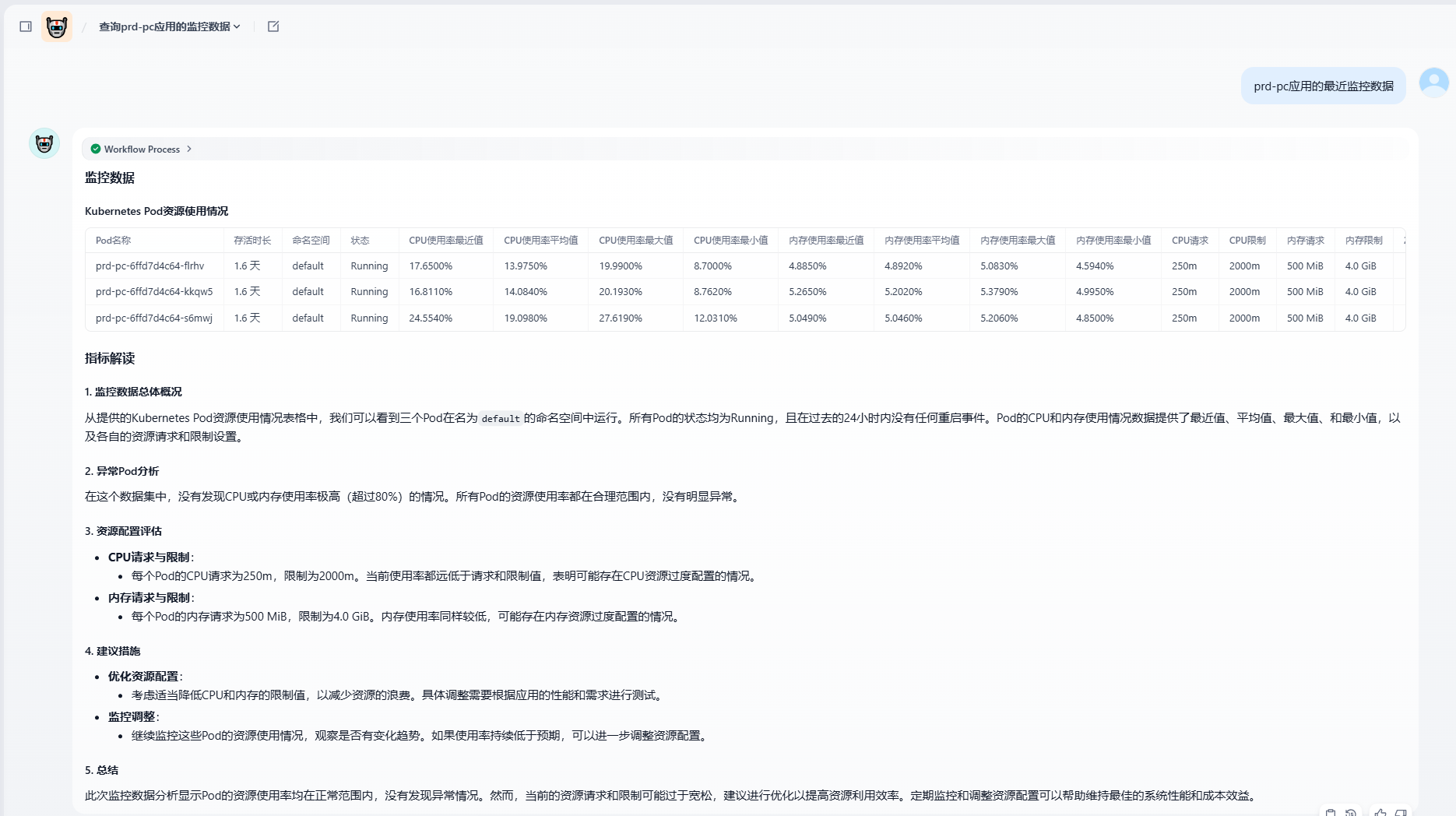
是不是很神奇?通过简单的对话就能获取 Kubernetes 集群中 Pod 的资源使用情况并进行智能分析。这篇文章将详细介绍如何利用 Dify 平台结合 Prometheus 监控系统,实现对 Kubernetes 资源的智能分析和管理。
-
AI 流程平台对比——Dify、FastGPT、RAGFlow、MaxKB
TLDR
-
如果您需要一个简单、固定的需求,随便选用一个适合的编程语言调用 LLM API 即可
-
如果您是正在学习 AI 的开发人员,能自己实现就自己实现,框架会变,底层原理不变
-
注重流程与扩展选 Dify
-
注重知识库选 RAGFlow
-
注重易用性和企业级部署选 MaxKB
-
-
Cursor 提示词技巧:让 AI 助手更高效地完成编码任务
引言
你是否曾经在使用 Cursor 这类 AI 编码助手时遇到过困境?AI 似乎无法完全理解你的需求,或者生成的代码存在各种问题?今天我要分享一个实用的提示词(Prompt)技巧,它能帮助 Cursor 更加独立地完成完整功能开发,特别适合编程新手使用。
背景
在我最近的一次开发中,我没有让 Cursor 去调试已有代码,而是直接让它开发全新功能。在这个过程中,Cursor 多次遇到了困难,无法顺利完成任务。我发现了一个有效的解决方案,现在分享给大家。
-
使用 Cursor 创建 MCP Server:新手友好指南
前言
欢迎来到这篇 Cursor IDE 使用指南!无论你是编程新手还是有经验的开发者,本教程都将帮助你了解如何利用 Cursor IDE 的强大 AI 功能来创建一个 MCP Server。
在开始之前,让我们先了解一些基本概念:
- Cursor IDE:一款集成了 AI 功能的代码编辑器,能够帮助你更高效地编写代码
- Cursor 规则:可以控制 AI 模型行为的指令集,类似于系统提示词
- MCP (Model Context Protocol):一种让 AI 模型与外部服务交互的协议
- LangGPT:一个面向大语言模型的自然语言编程框架,帮助我们更好地构建提示词
本教程将通过三个简单步骤,带你实现一个返回 IP 地址归属地的 MCP Server:
- 创建一个 LangGPT 风格的提示词生成助手
- 利用这个助手生成一个 MCP 专家
- 让 MCP 专家帮我们实现一个简单的 MCP 应用
准备好了吗?让我们开始吧!
-
如何使用 LLM-Benchmark 工具压测你的大语言模型性能
在当今 AI 快速发展的时代,大语言模型(LLM)已经成为许多企业和开发者的核心技术。然而,当我们部署自己的 LLM 服务时,如何评估其性能表现?特别是在高并发场景下,模型的 token 输出速率、响应时间等指标至关重要。今天,我将为大家介绍一款强大的开源工具——LLM-Benchmark,它能帮助你全面评估 LLM 模型的性能表现。
-
Dify 开源版增加工作空间
Dify是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
在安装开源版本 Dify 时,后台只有一个工作空间,且无法在后台创建新的工作空间。为了解决这个问题,我们可以手动创建工作空间。 本次使用的版本是
1.0.0。
-
部署 DeepSeek R1 671B 深度思考模型
本文介绍如何在天翼云 GPU 服务器上部署 DeepSeek R1 深度思考模型。
方案说明
目前部署模型的方式有很多种,比如 Docker、Kubernetes、Ollama、vLLM, SGLAng 等 。 本文主要介绍如何使用 Ollama, vLLM 和 SGLang 在单机上部署 DeepSeek R1 模型。
DeepSeek
DeepSeek 系列模型是由深度求索(DeepSeek)公司推出的大语言模型。
DeepSeek-R1 模型包含 671B 参数,激活 37B,在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力,尤其在数学、代码、自然语言推理等任务上。
DeepSeek-V3 为 MoE 模型,671B 参数,激活 37B,在 14.8T Token 上进行了预训练,在长文本、代码、数学、百科、中文能力上表现优秀。
DeepSeek-R1-Distill 系列模型是基于知识蒸馏技术,通过使用 DeepSeek-R1 生成的训练样本对 Qwen、Llama 等开源大模型进行微调训练后,所得到的增强型模型。
- git 8
- vpn 4
- python 9
- Nginx 2
- Ansible 132
- 初创型公司运维专题 10
- 杂项 2
- kubernetes 20
- jekyll 3
- Linux性能优化 7
- LDAP 7
- AD 1
- monitor 1
- drone 2
- aws 4
- supervisor 3
- docker 8
- 运维 8
- rabbitmq 6
- openssl 1
- openssh 1
- linux 5
- jenkins 1
- container 1
- harbor 1
- cncf 1
- 学习周报 13
- 运维小需求 6
- PostgreSQL 2
- GreenPlum 2
- 运维规范 1
- rancher 1
- prometheus 1
- bpf ebpf 1
- 大模型 2
- ai 14
- Dockerfile 1