- 环境信息
- 网络信息
- 初始化所有节点
- 免密登录其他节点
- 预下载镜像
- 预下载配置文件
- 部署服务
- 建立集群CA和证书
- 部署Kubernetes Masters
- 部署Kubernetes Nodes
- Kubernetes Core Addons 部署
- Kubernetes 集群网络
- 部署Kubernetes Extra Addons组件
- 测试高可用
本次使用全手工的方式以二进制形式部署kubernetes的ha集群,ha方式选择node节点代理apiserver的方式。
如果不想手动,或者想学习自动化部署的,可以看看Ansible 应用 之 【使用ansible来做kubernetes 1.14.3集群高可用的一键部署 】 文章。
hyperkube是Kubernetes服务器组件的一体化二进制文件。
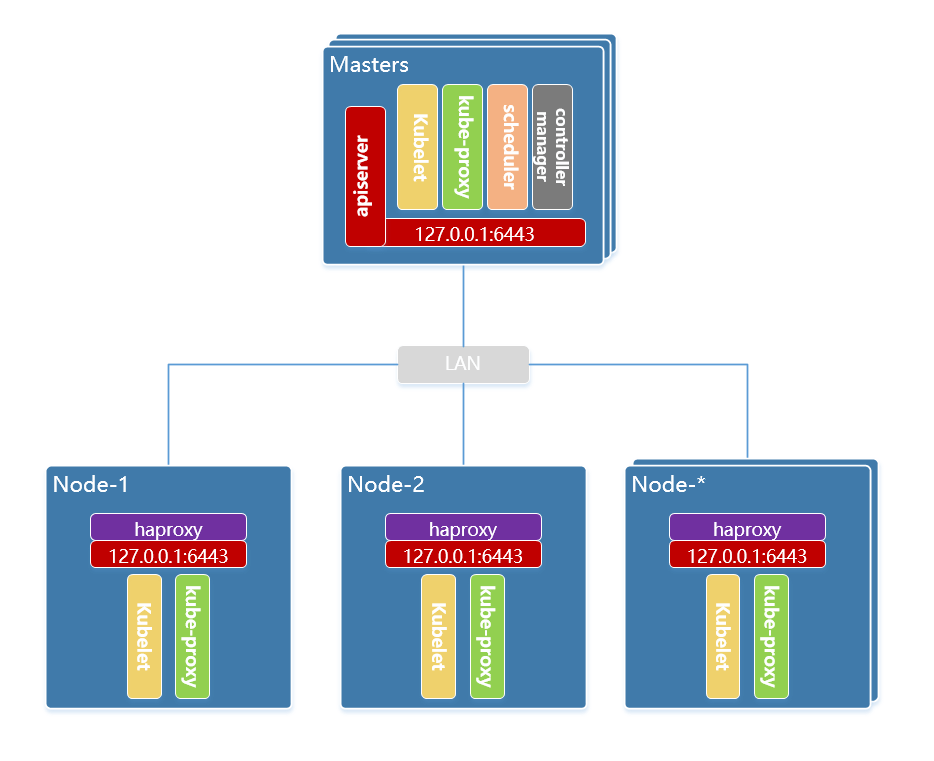
环境信息
| System OS | IP Address | Docker | Kernel | Hostname | Cpu | Memory | Application |
|---|---|---|---|---|---|---|---|
| CentOS 7.4.1708 | 192.168.77.130 | 18.09.6 | 5.1.11-1.el7 | k8s-m1 | 2C | 4G | k8s-master、etcd |
| CentOS 7.4.1708 | 192.168.77.131 | 18.09.6 | 5.1.11-1.el7 | k8s-m2 | 2C | 4G | k8s-master、etcd |
| CentOS 7.4.1708 | 192.168.77.132 | 18.09.6 | 5.1.11-1.el7 | k8s-m3 | 2C | 4G | k8s-master、etcd |
| CentOS 7.4.1708 | 192.168.77.133 | 18.09.6 | 5.1.11-1.el7 | k8s-n1 | 2C | 4G | k8s-node |
| CentOS 7.4.1708 | 192.168.77.134 | 18.09.6 | 5.1.11-1.el7 | k8s-n2 | 2C | 4G | k8s-node |
网络信息
- Cluster IP CIDR:
10.244.0.0/16 - Service Cluster IP CIDR:
10.96.0.0/12 - Service DNS IP:
10.96.0.10 - DNS DN:
cluster.local - INGRESS IP:
192.168.77.140 - External DNS IP:
192.168.77.141
初始化所有节点
YUM源调整
sed -e 's!^#baseurl=!baseurl=!g' \
-e 's!^mirrorlist=!#mirrorlist=!g' \
-e 's!mirror.centos.org!mirrors.ustc.edu.cn!g' \
-i /etc/yum.repos.d/CentOS-Base.repo
yum install -y epel-release
sed -e 's!^mirrorlist=!#mirrorlist=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!^metalink!#metalink!g' \
-e 's!//download\.fedoraproject\.org/pub!//mirrors.ustc.edu.cn!g' \
-e 's!http://mirrors\.ustc!https://mirrors.ustc!g' \
-i /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel-testing.repo
关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
关掉网络服务
systemctl stop NetworkManager && systemctl disable NetworkManager
关闭selinux
setenforce 0
sed -i "s#=enforcing#=disabled#g" /etc/selinux/config
关闭swap
swapoff -a && sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
同步时间
yum install -y ntpdate ntp
ntpdate 0.cn.pool.ntp.org
hwclock --systohc
cat << EOF >> /etc/ntp.conf
driftfile /var/lib/ntp/drift
server 0.cn.pool.ntp.org
server 1.cn.pool.ntp.org
server 2.cn.pool.ntp.org
server 3.cn.pool.ntp.org
EOF
systemctl enable --now ntpd
ntpq -p
系统参数调整
cat <<EOF > /etc/sysctl.d/k8s.conf
# https://github.com/moby/moby/issues/31208
# ipvsadm -l --timout
# 修复ipvs模式下长连接timeout问题 小于900即可
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
# 要求iptables不对bridge的数据进行处理
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
net.netfilter.nf_conntrack_max = 2310720
fs.inotify.max_user_watches=89100
fs.may_detach_mounts = 1
fs.file-max = 52706963
fs.nr_open = 52706963
vm.swappiness = 0
vm.overcommit_memory=1
vm.panic_on_oom=0
EOF
sysctl --system
如果遇到
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
是因为没有加载ipv6模块,可以使用 modprobe br_netfilter
设置节点主机名解析
cat << EOF >> /etc/hosts
192.168.77.130 k8s-m1
192.168.77.131 k8s-m2
192.168.77.132 k8s-m3
192.168.77.133 k8s-n1
192.168.77.134 k8s-n2
EOF
启用ipvs
yum install ipvsadm ipset sysstat conntrack libseccomp -y
开机自启动加载ipvs内核
:> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
systemctl enable --now systemd-modules-load.service
安装docker-ce
curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo
sed -i 's#download.docker.com#mirrors.ustc.edu.cn/docker-ce#g' /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce bash-completion
cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/
mkdir /etc/docker
cat >> /etc/docker/daemon.json <<EOF
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"live-restore": true,
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn/"
]
}
EOF
systemctl enable --now docker
可以用官网提供的docker环境检查脚本来检查系统内核和模块是否适合运行docker
curl https://raw.githubusercontent.com/docker/docker/master/contrib/check-config.sh > check-config.sh
bash ./check-config.sh
升级内核
可选, Centos 7 符合docker要求的最低内核版本
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available --showduplicates | grep -Po '^kernel-ml.x86_64\s+\K\S+(?=.el7)'
yum --disablerepo="*" --enablerepo=elrepo-kernel install -y kernel-ml{,-devel}
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
grubby --default-kernel
grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
免密登录其他节点
在ks8-m1操作
yum install sshpass -y
ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa
for NODE in k8s-m1 k8s-m2 k8s-m3 k8s-n1 k8s-n2; do
echo "--- $NODE ---"
sshpass -p 123456 ssh-copy-id -o "StrictHostKeyChecking no" -i /root/.ssh/id_rsa.pub ${NODE}
ssh ${NODE} "hostnamectl set-hostname ${NODE}"
done
其中
123456是服务器的密码
预下载镜像
实验环境,或者生产环境在网络的问题下,不能顺畅的安装集群,特此准备了此次实验所需要的所有镜像文件和二进制文件。
文件下载链接:https://pan.baidu.com/s/1eBPPI6kDxvbynH43--ly5g
提取码:y39z
在k8s-m1节点上执行
yum -y install p7zip
7za x v1.14.3.7z -r -o/opt/
find /opt/v1.14.3/images/all/ -type f -name '*.tgz' -exec sh -c 'docker load < {}' \;
find /opt/v1.14.3/images/master/ -type f -name '*.tgz' -exec sh -c 'docker load < {}' \;
for NODE in k8s-m2 k8s-m3 k8s-n1 k8s-n2; do
echo "--- $NODE ---"
scp /opt/v1.14.3/images/all/* ${NODE}:/opt/images
done
for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
scp /opt/v1.14.3/images/master/* ${NODE}:/opt/images
done
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
scp /opt/v1.14.3/images/node/* ${NODE}:/opt/images
done
for NODE in k8s-m2 k8s-m3 k8s-n1 k8s-n2; do
echo "--- $NODE ---"
ssh ${NODE} "find /opt/images/ -type f -name '*.tgz' -exec sh -c 'docker load < {}' \;"
done
预下载配置文件
通过git,下载本次使用的配置文件
在k8s-m1上执行
yum -y install git
git clone https://github.com/lework/kubernetes-manual.git /opt/kubernetes-manual
部署服务
部署etcd
分发etcd二进制文件
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
scp /opt/v1.14.3/bin/etcd* ${NODE}:/usr/local/bin/
done
原文件: https://github.com/etcd-io/etcd/releases/download/v3.3.13/etcd-v3.3.13-linux-amd64.tar.gz
部署kubernetes组件
本次使用的是
all in one的hyperkube二进制文件,也可以使用各个组件的二进制文件。
分发二进制文件
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
scp /opt/v1.14.3/bin/hyperkube ${NODE}:/usr/local/bin/hyperkube
ssh ${NODE} "useradd kube -s /sbin/nologin; \
(cd /usr/local/bin/;hyperkube --make-symlinks)"
done
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
scp /opt/v1.14.3/bin/hyperkube ${NODE}:/usr/local/bin/hyperkube
ssh ${NODE} "useradd kube -s /sbin/nologin; \
ln -s /usr/local/bin/hyperkube /usr/local/bin/kubelet; \
ln -s /usr/local/bin/hyperkube /usr/local/bin/kube-proxy;"
done
使用hyperkube –make-symlinks可以在当前目录创建所有组件的软链接文件
原文件: https://storage.googleapis.com/kubernetes-release/release/v1.14.3/bin/linux/amd64/hyperkube
部署haproxy
本文使用haproxy代理apiserver
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
ssh ${NODE} "yum -y install haproxy"
done
部署CFSSL工具
在k8s-m1上安裝CFSSL工具,用来建立CA证书,并生成tls认证
mv /opt/v1.14.3/bin/cfs* /usr/local/bin/
原文件: https://pkg.cfssl.org/R1.2/cfssl_linux-amd64, https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
建立集群CA和证书
| Default CN | Description |
|---|---|
| kubernetes-ca | Kubernetes general CA |
| etcd-ca | For all etcd-related functions |
| kubernetes-front-proxy-ca | For the front-end proxy |
在
k8s-m1节点上操作
创建Etcd所需的证书
创建ca配置
mkdir -p /etc/etcd/ssl && cd /etc/etcd/ssl
echo '{"signing":{"default":{"expiry":"87600h"},"profiles":{"kubernetes":{"usages":["signing","key encipherment","server auth","client auth"],"expiry":"87600h"}}}}' > ca-config.json
生成etcd的ca证书
echo '{"CN":"etcd","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"etcd","OU":"Etcd Security"}]}' > etcd-ca-csr.json
cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare etcd-ca
生成etcd的凭证
echo '{"CN":"etcd","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"etcd","OU":"Etcd Security"}]}' > etcd-csr.json
cfssl gencert \
-ca=etcd-ca.pem \
-ca-key=etcd-ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,192.168.77.130,192.168.77.131,192.168.77.132,*.etcd.local \
-profile=kubernetes \
etcd-csr.json | cfssljson -bare etcd
-hostname需修改成所有masters节点的ip地址, 建议在生产环境在证书内预留几个IP.*.etcd.local是预留的名称,后续加入节点时可以使用。 证书默认期限为87600h(10年),有需要加强安全性的可以适当减小。
将etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem文件拷贝到其它master节点上
for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /etc/etcd/ssl"
for FILE in etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem; do
scp /etc/etcd/ssl/${FILE} ${NODE}:/etc/etcd/ssl/${FILE}
done
done
创建Kubernetes组件的证书
建立ca
mkdir -p /etc/kubernetes/pki && cd /etc/kubernetes/pki
echo '{"signing":{"default":{"expiry":"87600h"},"profiles":{"kubernetes":{"usages":["signing","key encipherment","server auth","client auth"],"expiry":"87600h"}}}}' > ca-config.json
echo '{"CN":"kubernetes","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"Kubernetes","OU":"Kubernetes System"}]}' > ca-csr.json
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
证书默认期限为87600h(10年),有需要加强安全性的可以适当减小。
建立API Server Certificate
此凭证将被用于 API Server 与 Kubelet Client 通信使用
echo '{"CN":"kube-apiserver","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"Kubernetes","OU":"Kubernetes System"}]}' > apiserver-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,10.96.0.1,192.168.77.130,192.168.77.131,192.168.77.132,localhost,*.master.kubernetes.node,kubernetes,kubernetes.default,kubernetes.default.svc,kubernetes.default.svc.cluster,kubernetes.default.svc.cluster.local \
-profile=kubernetes \
apiserver-csr.json | cfssljson -bare apiserver
这边
-hostname的10.96.0.1是kubernetes的Cluster IP,其他是master节点的ip地址。
kubernetes.default为Kubernets DN。
*.master.kubernetes.node是预留的解析名称,可以在本地绑定主机名称进行访问api。
Front Proxy Certificate
此凭证将被用于Authenticating Proxy的功能上,而该功能主要是提供API Aggregation的认证。首先通过以下命令创建CA:
echo '{"CN":"kubernetes","key":{"algo":"rsa","size":2048}}' > front-proxy-ca-csr.json
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare front-proxy-ca
echo '{"CN":"front-proxy-client","key":{"algo":"rsa","size":2048}}' > front-proxy-client-csr.json
cfssl gencert \
-ca=front-proxy-ca.pem \
-ca-key=front-proxy-ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
front-proxy-client-csr.json | cfssljson -bare front-proxy-client
提示hosts的warning信息忽略即可
Controller Manager Certificate
凭证会建立system:kube-controller-manager的使用者(凭证CN),并被绑定在RBAC Cluster Role中的system:kube-controller-manager来让Controller Manager组件能够存取需要的API object。
echo '{"CN":"system:kube-controller-manager","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"syroller-manager","OU":"Kubernetes System"}]}' > manager-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
manager-csr.json | cfssljson -bare controller-manager
Scheduler Certificate
凭证会建立system:kube-scheduler的使用者(凭证CN),并被绑定在 RBAC Cluster Role 中的system:kube-scheduler来让 Scheduler 元件能够存取需要的 API object。
echo '{"CN":"system:kube-scheduler","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"system:kube-scheduler","OU":"Kubernetes System"}]}' > scheduler-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
scheduler-csr.json | cfssljson -bare scheduler
Admin Certificate
Admin被用来绑定RBAC Cluster Role中cluster-admin,当想要操作所有Kubernetes集群功能时,就必须利用这边产生的kubeconfig档案。通过以下命令创建Kubernetes Admin凭证:
echo '{"CN":"admin","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"system:masters","OU":"Kubernetes System"}]}' > admin-csr.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare admin
Master Kubelet Certificate
这边使用Node authorizer来让节点的kubelet能够存取如services、endpoints等API,而使用Node authorizer需定义system:nodes群组(凭证的Organization),并且包含system:node:
的使用者名称(凭证的Common Name)。
echo '{"CN":"system:node:$NODE","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","L":"Shanghai","ST":"Shanghai","O":"system:nodes","OU":"Kubernetes System"}]}' > kubelet-csr.json
# 生成各节点的证书
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
cp kubelet-csr.json kubelet-$NODE-csr.json;
sed -i "s/\$NODE/$NODE/g" kubelet-$NODE-csr.json;
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=$NODE \
-profile=kubernetes \
kubelet-$NODE-csr.json | cfssljson -bare kubelet-$NODE
done
完成后复制kubelet凭证到其它节点
for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /etc/kubernetes/pki"
for FILE in kubelet-$NODE-key.pem kubelet-$NODE.pem ca.pem; do
scp /etc/kubernetes/pki/${FILE} ${NODE}:/etc/kubernetes/pki/${FILE}
done
done
生成kubernetes组件的凭证
KUBE_APISERVER="https://127.0.0.1:6443" # 修改kubernetes的server地址
本次使用的ha方式是node节点的本地代理,所以ip是
127.0.0.1地址
生成admin.conf的kubeconfig
# admin set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../admin.kubeconfig
# admin set credentials
kubectl config set-credentials kubernetes-admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem \
--embed-certs=true \
--kubeconfig=../admin.kubeconfig
# admin set context
kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=../admin.kubeconfig
# admin set default context
kubectl config use-context kubernetes-admin@kubernetes \
--kubeconfig=../admin.kubeconfig
生成controller-manager.conf的 kubeconfig
# controller-manager set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set credentials
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=controller-manager.pem \
--client-key=controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set context
kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=../controller-manager.kubeconfig
# controller-manager set default context
kubectl config use-context system:kube-controller-manager@kubernetes \
--kubeconfig=../controller-manager.kubeconfig
生成scheduler.conf的kubeconfig
# scheduler set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../scheduler.kubeconfig
# scheduler set credentials
kubectl config set-credentials system:kube-scheduler \
--client-certificate=scheduler.pem \
--client-key=scheduler-key.pem \
--embed-certs=true \
--kubeconfig=../scheduler.kubeconfig
# scheduler set context
kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=../scheduler.kubeconfig
# scheduler use default context
kubectl config use-context system:kube-scheduler@kubernetes \
--kubeconfig=../scheduler.kubeconfig
在各节点上生成kubelet的kubeconfig
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "source /etc/profile; cd /etc/kubernetes/pki && \
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config set-credentials system:node:${NODE} \
--client-certificate=kubelet-${NODE}.pem \
--client-key=kubelet-${NODE}-key.pem \
--embed-certs=true \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config set-context system:node:${NODE}@kubernetes \
--cluster=kubernetes \
--user=system:node:${NODE} \
--kubeconfig=../kubelet.kubeconfig && \
kubectl config use-context system:node:${NODE}@kubernetes \
--kubeconfig=../kubelet.kubeconfig "
done
Service Account Key
Kubernetes Controller Manager利用Key pair来产生与签署Service Account的 tokens,而这边不通过CA做认证,而是建立一组公私钥来让API Server与Controller Manager 使用:
openssl genrsa -out sa.key 2048
openssl rsa -in sa.key -pubout -out sa.pub
生成用于加密静态Secret数据的配置文件encryption.yaml
cat <<EOF> /etc/kubernetes/encryption.yaml
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: $(head -c 32 /dev/urandom | base64)
- identity: {}
EOF
生成apiserver RBAC审计配置文件audit-policy.yaml
cat <<EOF> /etc/kubernetes/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
EOF
分发凭证至其他master节点
cd /etc/kubernetes/pki/
for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
for FILE in $(ls ca*.pem sa.* apiserver*.pem front*.pem scheduler*.pem); do
scp /etc/kubernetes/pki/${FILE} ${NODE}:/etc/kubernetes/pki/${FILE}
done
for FILE in /etc/kubernetes/encryption.yaml /etc/kubernetes/audit-policy.yaml; do
scp ${FILE} ${NODE}:${FILE}
done
done
分发Kubernetes config到其它master节点
for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
for FILE in admin.kubeconfig controller-manager.kubeconfig scheduler.kubeconfig; do
scp /etc/kubernetes/${FILE} ${NODE}:/etc/kubernetes/${FILE}
done
done
部署Kubernetes Masters
- kubelet:负责管理容器的生命周期,定期从 API Server 取得节点上的预期状态(如网路、储存等等配置)资源,并呼叫对应的容器介面(CRI、CNI 等)来达成这个状态。任何 Kubernetes 节点都会拥有该元件。
- kube-apiserver:以 REST APIs 提供 Kubernetes 资源的 CRUD,如授权、认证、存取控制与 API 注册等机制。
- kube-controller-manager:透过核心控制循环(Core Control Loop)监听 Kubernetes API 的资源来维护丛集的状态,这些资源会被不同的控制器所管理,如 Replication Controller、Namespace Controller 等等。而这些控制器会处理着自动扩展、滚动更新等等功能。
- kube-scheduler:负责将一个(或多个)容器依据排程策略分配到对应节点上让容器引擎(如 Docker)执行。而排程受到 QoS 要求、软硬体约束、亲和性(Affinity)等等规范影响。
- Etcd:用来保存丛集所有状态的 Key/Value 储存系统,所有 Kubernetes 元件会透过 API Server 来跟 Etcd 进行沟通来保存或取得资源状态。
本次使用的是
all in one的hyperkube二进制文件部署k8s组件,也可以使用各个组件的二进制文件。
配置etcd
分发etcd配置
#指定etcd集群地址
ETCD_INITIAL_CLUSTER="k8s-m1=https://192.168.77.130:2380,k8s-m2=https://192.168.77.131:2380,k8s-m3=https://192.168.77.132:2380"
cd /opt/kubernetes-manual/v1.14.3/
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "useradd etcd -s /sbin/nologin; \
mkdir -p /etc/etcd /var/lib/etcd"
scp master/etc/etcd/etcd.config.yaml ${NODE}:/etc/etcd/etcd.config.yaml
scp master/systemd/etcd.service ${NODE}:/usr/lib/systemd/system/etcd.service
ssh ${NODE} sed -i 's#{{HOSTNAME}}#${HOSTNAME}#g' /etc/etcd/etcd.config.yaml
ssh ${NODE} sed -i "s#{{ETCD_INITIAL_CLUSTER}}#${ETCD_INITIAL_CLUSTER}#g" /etc/etcd/etcd.config.yaml
ssh ${NODE} sed -i 's#{{PUBLIC_IP}}#$(hostname -i)#g' /etc/etcd/etcd.config.yaml
ssh ${NODE} chown etcd.etcd -R /etc/etcd /var/lib/etcd
done
这里如果ip改变,需要更改
ETCD_INITIAL_CLUSTER地址。
启动ETCD服务
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "systemctl enable --now etcd"
done
查看etcd服务状态
export PKI="/etc/etcd/ssl/"
ETCDCTL_API=3 etcdctl \
--cacert=${PKI}/etcd-ca.pem \
--cert=${PKI}/etcd.pem \
--key=${PKI}/etcd-key.pem \
--endpoints="https://127.0.0.1:2379" \
member list
373935bf9d3b17f2, started, k8s-m3, https://192.168.77.132:2380, https://192.168.77.132:2379
89d3f05970a12200, started, k8s-m1, https://192.168.77.130:2380, https://192.168.77.130:2379
f0fc135244de5511, started, k8s-m2, https://192.168.77.131:2380, https://192.168.77.131:2379
配置kubernetes组件
分发kubernetes组件配置文件
ETCD_SERVERS='https://192.168.77.130:2379,https://192.168.77.131:2379,https://192.168.77.132:2379'
APISERVER_COUNT=3
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} 'mkdir -p /etc/kubernetes/manifests /var/lib/kubelet /var/log/kubernetes/{apiserver,scheduler,controller-manager,proxy,kubelet}'
scp master/systemd/kube*.service ${NODE}:/usr/lib/systemd/system/
scp master/etc/kubernetes/kubelet-conf.yaml $NODE:/etc/kubernetes/kubelet-conf.yaml
ssh ${NODE} sed -i 's#{{NODE_IP}}#$(hostname -i)#g' /usr/lib/systemd/system/kube-apiserver.service
ssh ${NODE} sed -i "s#{{APISERVER_COUNT}}#${APISERVER_COUNT}#g" /usr/lib/systemd/system/kube-apiserver.service
ssh ${NODE} sed -i "s#{{ETCD_SERVERS}}#${ETCD_SERVERS}#g" /usr/lib/systemd/system/kube-apiserver.service
done
这里如果ip改变,需要更改
ETCD_SERVERS地址。APISERVER_COUNT是运行的apiserver节点数
启动服务
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh $NODE 'systemctl enable --now kube-apiserver kube-controller-manager kube-scheduler kubelet;
mkdir -p ~/.kube/
cp /etc/kubernetes/admin.kubeconfig ~/.kube/config;
kubectl completion bash > /etc/bash_completion.d/kubectl'
done
接下来将建立TLS Bootstrapping来让Node签证并授权注册到集群。
建立TLS Bootstrapping RBAC
由于本实验采用TLS认证来确保Kubernetes集群的安全性,因此每个节点的kubelet都需要透过API Server的CA进行身份验证后,才能与API Server进行沟通,而这过程过去都是采用手动方式针对每台节点(master与node)单独签署凭证,再设定给kubelet使用,然而这种方式是一件繁琐的事情,因为当节点扩展到一定程度时,将会非常费时,甚至延伸初管理不易问题。
而由于上述问题,Kubernetes实现了TLSBootstrapping来解决此问题,这种做法是先让kubelet以一个低权限使用者(一个能存取CSR API的Token)存取API Server,接着对API Server提出申请凭证签署请求,并在受理后由API Server动态签署kubelet凭证提供给对应的node节点使用。具体作法请参考TLS Bootstrapping与Authenticating with Bootstrap Tokens。
在k8s-m1上创建bootstrap使用者的kubeconfig
cd /etc/kubernetes/pki
export TOKEN_ID=$(openssl rand 3 -hex)
export TOKEN_SECRET=$(openssl rand 8 -hex)
export BOOTSTRAP_TOKEN=${TOKEN_ID}.${TOKEN_SECRET}
export KUBE_APISERVER="https://127.0.0.1:6443" # apiserver 的vip地址
# bootstrap set cluster
kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap set credentials
kubectl config set-credentials tls-bootstrap-token-user \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap set context
kubectl config set-context tls-bootstrap-token-user@kubernetes \
--cluster=kubernetes \
--user=tls-bootstrap-token-user \
--kubeconfig=../bootstrap-kubelet.kubeconfig
# bootstrap use default context
kubectl config use-context tls-bootstrap-token-user@kubernetes \
--kubeconfig=../bootstrap-kubelet.kubeconfig
KUBE_APISERVER这边设定为VIP地址。若想要用手动签署凭证来进行授权的话,可以参考 Certificate。
接着在k8s-m1建立 TLS Bootstrap Secret来提供自动签证使用:
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-${TOKEN_ID}
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
token-id: ${TOKEN_ID}
token-secret: ${TOKEN_SECRET}
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token
EOF
然后建立TLS Bootstrap Autoapprove RBAC来提供自动受理CSR:
cat <<EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:node-bootstrapper
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-bootstrap
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:nodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:bootstrappers:default-node-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-autoapprove-certificate-rotation
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:nodes
EOF
验证集群
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3m50s
# 证书
kubectl get csr
NAME AGE REQUESTOR CONDITION
csr-6drjk 26s system:node:k8s-m1 Approved,Issued
csr-bck44 44s system:node:k8s-m2 Approved,Issued
csr-rd94d 69s system:node:k8s-m3 Approved,Issued
# 节点
kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-m1 NotReady master 2m16s v1.14.3
k8s-m2 NotReady master 2m27s v1.14.3
k8s-m3 NotReady master 2m36s v1.14.3
这里的节点状态
NotReady是正常的,因为我们集群网络还没建立。
给master节点设置Taints and Tolerations ,阻止pod调度到master节点
kubectl taint nodes node-role.kubernetes.io/master="":NoSchedule --all
创建kube-apiserver user对nodes的资源存取权限
cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kube-apiserver
EOF
部署Kubernetes Nodes
配置haproxy
配置代理apiserver服务
cd /opt/kubernetes-manual/v1.14.3/
cat <<EOF>> node/etc/haproxy/haproxy.cfg
server k8s-m1 192.168.77.130:6443 check
server k8s-m2 192.168.77.131:6443 check
server k8s-m3 192.168.77.132:6443 check
EOF
分发配置并启动haproxy
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
scp node/etc/haproxy/haproxy.cfg $NODE:/etc/haproxy/haproxy.cfg
ssh $NODE systemctl enable --now haproxy.service
done
验证haproxy代理
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
ssh ${NODE} curl -k -s https://127.0.0.1:6443
done
配置kubelet
分发配置并启动kubelet
cd /opt/kubernetes-manual/v1.14.3/
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
ssh $NODE "mkdir -p /etc/kubernetes/pki /etc/kubernetes/manifests /var/lib/kubelet /var/log/kubernetes/kubelet"
scp /etc/kubernetes/pki/ca.pem $NODE:/etc/kubernetes/pki/ca.pem
scp /etc/kubernetes/bootstrap-kubelet.kubeconfig $NODE:/etc/kubernetes/bootstrap-kubelet.kubeconfig
scp node/systemd/kubelet.service $NODE:/lib/systemd/system/kubelet.service
scp node/etc/kubernetes/kubelet-conf.yaml $NODE:/etc/kubernetes/kubelet-conf.yaml
ssh $NODE 'systemctl enable --now kubelet.service'
done
验证node
kubectl get csr
node-csr-5VkCjWvb8tGVtO-d2gXiQrnst-G1xe_iA0AtQuYNEMI 2m system:bootstrap:872255 Approved,Issued
node-csr-Uwpss9OhJrAgOB18P4OIEH02VHJwpFrSoMOWkkrK-lo 2m system:bootstrap:872255 Approved,Issued
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-m1 NotReady master 5m v1.14.3
k8s-m2 NotReady master 6m v1.14.3
k8s-m3 NotReady master 8m v1.14.3
k8s-n1 NotReady worker 51s v1.14.3
k8s-n2 NotReady worker 50s v1.14.3
Kubernetes Core Addons 部署
Kubernetes Proxy
kube-proxy是实现Kubernetes Service资源功能的关键组件,监听API Server的Service与Endpoint资源的事件,并依据资源预期状态透过iptables或ipvs来实现网路转发,而本次安装采用ipvs。
创建proxy的rabc
kubectl apply -f addons/kube-proxy/kube-proxy.rbac.yaml
创建kube-proxy的kubeconfig
CLUSTER_NAME="kubernetes"
KUBE_CONFIG="kube-proxy.kubeconfig"
SECRET=$(kubectl -n kube-system get sa/kube-proxy \
--output=jsonpath='{.secrets[0].name}')
JWT_TOKEN=$(kubectl -n kube-system get secret/$SECRET \
--output=jsonpath='{.data.token}' | base64 -d)
kubectl config set-cluster ${CLUSTER_NAME} \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-context ${CLUSTER_NAME} \
--cluster=${CLUSTER_NAME} \
--user=${CLUSTER_NAME} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config set-credentials ${CLUSTER_NAME} \
--token=${JWT_TOKEN} \
--kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config use-context ${CLUSTER_NAME} --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
kubectl config view --kubeconfig=/etc/kubernetes/${KUBE_CONFIG}
分发配置并启动kube-proxy
for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
scp /etc/kubernetes/kube-proxy.kubeconfig $NODE:/etc/kubernetes/kube-proxy.kubeconfig
scp master/etc/kubernetes/kube-proxy-conf.yaml $NODE:/etc/kubernetes/kube-proxy-conf.yaml
scp master/systemd/kube-proxy.service $NODE:/usr/lib/systemd/system/kube-proxy.service
ssh $NODE 'systemctl enable --now kube-proxy.service'
done
for NODE in k8s-n1 k8s-n2; do
echo "--- $NODE ---"
scp /etc/kubernetes/kube-proxy.kubeconfig $NODE:/etc/kubernetes/kube-proxy.kubeconfig
scp node/etc/kubernetes/kube-proxy-conf.yaml $NODE:/etc/kubernetes/kube-proxy-conf.yaml
scp node/systemd/kube-proxy.service $NODE:/usr/lib/systemd/system/kube-proxy.service
ssh $NODE 'systemctl enable --now kube-proxy.service'
done
验证
# 检查ipvs规则
ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.77.130:6443 Masq 1 0 0
-> 192.168.77.131:6443 Masq 1 0 0
-> 192.168.77.132:6443 Masq 1 0 0
curl localhost:10249/proxyMode
ipvs
CoreDNS
1.11后CoreDNS已取代Kube DNS作为集群服务发现元件,由于Kubernetes需要让Pod与Pod之间能夠互相通信,然而要能够通信需要知道彼此的IP才行,而这种做法通常是通过Kubernetes API来获取,但是Pod IP会因为生命周期变化而改变,因此这种做法无法弹性使用,且还会增加API Server负担,基于此问题Kubernetes提供了DNS服务来作为查询,让Pod能够以Service名称作为域名来查询IP位址,因此使用者就再不需要关心实际Pod IP,而DNS也会根据Pod变化更新资源记录(Record resources)。
CoreDNS是由CNCF维护的开源DNS方案,该方案前身是SkyDNS,其采用了Caddy的一部分来开发伺服器框架,使其能够建立一套快速灵活的 DNS,而 CoreDNS 每个功能都可以被当作成一個插件的中介软体,如Log、Cache、Kubernetes 等功能,甚至能够将源记录存储在Redis、Etcd中。
部署CoreDNS
kubectl apply -f addons/coredns/
kubectl -n kube-system get po -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-58b4fbcfbb-4tdjh 0/1 Pending 0 90s
coredns-58b4fbcfbb-w9js2 0/1 Pending 0 90s
Pending的原因是因为节点状态为NotReady, 因为集群网络还没建立呢。
Kubernetes 集群网络
Kubernetes在默认情况下与Docker的网络有所不同。在Kubernetes中有四个问题是需要被解决的,分别为:
- 高耦合的容器到容器通信:通过Pods与Localhost的通信来解决。
- Pod 到 Pod 的通信:通过实现网络模型来解决。
- Pod 到 Service 的通信:由Service objects结合kube-proxy解决。
- 外部到 Service 的通信:一样由Service objects结合kube-proxy解决。
而 Kubernetes 对于任何网络的实现都需要满足以下基本要求(除非是有意调整的网络分段策略):
- 所有容器能够在没有 NAT 的情况下与其他容器通信。
- 所有节点能够在没有 NAT 情况下与所有容器通信(反之亦然)。
- 容器看到的IP与其他人看到的IP是一样的。
庆幸的是Kubernetes已经有非常多的网络模型以网络插件(Network Plugins)方式被实现,因此可以选用满足自己需求的网络功能来使用。另外 Kubernetes 中的网路插件有以下两种形式:
- CNI plugins:以 appc/CNI 标准规范所实现的网络,详细可以阅读CNI Specification。
- Kubenet plugin:使用 CNI plugins 的 bridge 与 host-local 来实现基本的 cbr0。这通常被用在公有云服务上的 Kubernetes 丛集网路。
如果想了解如何选择可以阅读 Chris Love 的Choosing a CNI Network Provider for Kubernetes文章。
本次选用calico作为网络组件, 也可以选择Falnner
Calico是一款纯Layer 3的网络,其好处是它整合了各种云原生平台(Docker、Mesos 与 OpenStack 等),且Calico 采用 vSwitch,而是在每个Kubernetes节点使用vRouter功能,并通过Linux Kernel既有的 L3 forwarding 功能,而当资料中心复杂度增加时,Calico 也可以利用 BGP route reflector 來达成。
部署calico
kubectl apply -f addons/calico/
calico 默认使用的是作为Kubernetes API datastore存储,也可以选择直接使用etcd方式存储。 使用Kubernetes API datastore存储模式时,如果超过50个节点推荐启用typha,Typha组件可以帮助Calico扩展大量的节点,而不会对Kubernetes API服务器造成过度的影响。
kubectl -n kube-system get po | grep calico
calico-kube-controllers-78f8f67c4d-xxs2p 1/1 Running 0 1m
calico-node-9wrjs 1/1 Running 0 1m
calico-node-l4hlk 1/1 Running 0 1m
calico-node-l5hnz 1/1 Running 0 1m
calico-node-pdwm6 1/1 Running 0 1m
calico-node-w69bw 1/1 Running 0 1m
calicoctl 1/1 Running 0 1m
另外当节点超过50台,可以使用Calico的 Typha 模式来减少通过Kubernetes datastore造成API Server的负担。
使用calicoctl客户端
kubectl exec -ti -n kube-system calicoctl -- /calicoctl get profiles -o wide
NAME LABELS
kns.default map[]
kns.kube-node-lease map[]
kns.kube-public map[]
kns.kube-system map[]
ksa.default.default map[]
ksa.kube-node-lease.default map[]
ksa.kube-public.default map[]
ksa.kube-system.attachdetach-controller map[]
ksa.kube-system.bootstrap-signer map[]
ksa.kube-system.calico-kube-controllers map[]
ksa.kube-system.calico-node map[]
ksa.kube-system.calicoctl map[]
ksa.kube-system.certificate-controller map[]
ksa.kube-system.clusterrole-aggregation-controller map[]
ksa.kube-system.coredns map[pcsa.addonmanager.kubernetes.io/mode:Reconcile pcsa.kubernetes.io/cluster-service:true]
ksa.kube-system.cronjob-controller map[]
ksa.kube-system.daemon-set-controller map[]
ksa.kube-system.default map[]
ksa.kube-system.deployment-controller map[]
ksa.kube-system.disruption-controller map[]
ksa.kube-system.endpoint-controller map[]
ksa.kube-system.expand-controller map[]
ksa.kube-system.generic-garbage-collector map[]
ksa.kube-system.horizontal-pod-autoscaler map[]
ksa.kube-system.job-controller map[]
ksa.kube-system.kube-proxy map[pcsa.addonmanager.kubernetes.io/mode:Reconcile]
ksa.kube-system.namespace-controller map[]
ksa.kube-system.node-controller map[]
ksa.kube-system.persistent-volume-binder map[]
ksa.kube-system.pod-garbage-collector map[]
ksa.kube-system.pv-protection-controller map[]
ksa.kube-system.pvc-protection-controller map[]
ksa.kube-system.replicaset-controller map[]
ksa.kube-system.replication-controller map[]
ksa.kube-system.resourcequota-controller map[]
ksa.kube-system.service-account-controller map[]
ksa.kube-system.service-controller map[]
ksa.kube-system.statefulset-controller map[]
ksa.kube-system.token-cleaner map[]
ksa.kube-system.ttl-controller map[]
kubectl -n kube-system exec calicoctl -- calicoctl get node -o wide
NAME ASN IPV4 IPV6
k8s-m1 (unknown) 192.168.77.130/24
k8s-m2 (unknown) 192.168.77.131/24
k8s-m3 (unknown) 192.168.77.132/24
k8s-n1 (unknown) 192.168.77.133/24
k8s-n2 (unknown) 192.168.77.134/24
没有问题时,可以将calicoctl删除掉,等待有需要的时候再次建立
完成后,查看节点状态
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-m1 Ready master 30m v1.14.3
k8s-m2 Ready master 31m v1.14.3
k8s-m3 Ready master 32m v1.14.3
k8s-n1 Ready worker 38m v1.14.3
k8s-n2 Ready worker 38m v1.14.3
验证crondns的状态
kubectl -n kube-system get po -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-58b4fbcfbb-4tdjh 1/1 Running 0 25m
coredns-58b4fbcfbb-w9js2 1/1 Running 0 25m
yum -y install bind-utils
dig kubernetes.default.svc.cluster.local +noall +answer @10.96.0.10
; <<>> DiG 9.9.4-RedHat-9.9.4-74.el7_6.1 <<>> kubernetes.default.svc.cluster.local +noall +answer @10.96.0.10
;; global options: +cmd
kubernetes.default.svc.cluster.local. 5 IN A 10.96.0.1
部署Kubernetes Extra Addons组件
Ingress Controller
Ingress是Kubernetes中的一个抽象资源,其功能是透过Web Server的Virtual Host概念以域名(Domain Name)方式转发到内部Service,这避免了使用Service中的NodePort与LoadBalancer类型所带来的限制(如Port数量上限),而实现Ingress功能则是透过Ingress Controller来达成,它会负责监听Kubernetes API中的Ingress 与Service资源物件,并在发生资源变化时,依据资源预期的结果来设定Web Server。另外Ingress Controller有许多实现可以选择:
- Ingress NGINX: Kubernetes 官方维护的专案,也是本次安装使用的 Controller。
- F5 BIG-IP Controller: F5 所开发的 Controller,它能够让管理员透过 CLI 或 API 从 Kubernetes 与 OpenShift 管理 F5 BIG-IP 设备。
- Ingress Kong: 著名的开源 API Gateway 专案所维护的 Kubernetes Ingress Controller。
- Træfik: 是一套开源的 HTTP 反向代理与负载平衡器,而它也支援了 Ingress。
- Voyager: 一套以 HAProxy 为底的 Ingress Controller。
部署ingress Controller
export INGRESS_VIP=192.168.77.140
sed -i "s/{{INGRESS_VIP}}/${INGRESS_VIP}/g" ExtraAddons/ingress-controller/ingress-controller.svc.yaml
kubectl apply -f ExtraAddons/ingress-controller/ingress-controller.ns.yaml
kubectl apply -f ExtraAddons/ingress-controller/
kubectl -n ingress-nginx get po,svc
NAME READY STATUS RESTARTS AGE
pod/default-http-backend-75d9cc4bdf-l8cn5 1/1 Running 0 2m7s
pod/nginx-ingress-controller-7544557b7f-ncqx8 1/1 Running 0 2m5s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/default-http-backend ClusterIP 10.107.198.108 <none> 80/TCP 2m6s
service/ingress-nginx LoadBalancer 10.100.124.242 192.168.77.140 80:30294/TCP,443:31457/TCP 2m6s
如过没有EXTERNAL-IP,可以选择使用NodePort的方式暴露给外部的slb
验证ingress
curl http://192.168.77.140
default backend - 404
# 使用nginx来测试下
kubectl apply -f apps/nginx/
kubectl get po,svc,ing
NAME READY STATUS RESTARTS AGE
pod/nginx-6fcff58d54-zvvnk 1/1 Running 0 5m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h
service/nginx ClusterIP 10.107.209.50 <none> 80/TCP 11m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/nginx-ingress nginx.k8s.local 192.168.77.140 80 11m
# 测试nginx访问
curl 192.168.77.140 -H 'Host: nginx.k8s.local'
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
# 测试其他 domain name 是否会回返回 404
curl 192.168.77.140 -H 'Host: nginx1.k8s.local'
default backend - 404
虽然 Ingress 能够让我们通过域名方式访问 Kubernetes 內部服务,但是若域名无法被用户解析的话,将会显示default backend - 404结果,而这经常发送在內部自建环境上,虽然可以通过修改主机/etc/hosts来解决,但不能弹性扩展,因此下节将说明如何建立一个 External DNS 与 DNS 服务器来提供自动解析 Ingress 域名。
External DNS
External DNS 是 Kubernetes 社区的孵化项目,被用于定期同步 Kubernetes Service 与 Ingress 资源,并依据资源内容来自动设定公有云 DNS 服务的资源纪录(Record resources)。而由于部署不是公有云环境,因此需要通过 CoreDNS 提供一个内部 DNS 伺服器,再由 ExternalDNS 与这个 CoreDNS 做串接。
需要的服务
- CoreDNS:用来提供使用者的 DNS 解析以处理服务导向,并利用 Etcd 插件来存储与查询 DNS 资源记录(Record resources)。
- Etcd:用来储存 CoreDNS 资源纪录,并提供给整合的元件查询与储存使用。
- ExternalDNS:用于定期同步Kubernetes Service 与Ingress 资源,并根据Kubernetes 资源内容产生DNS 资源纪录来设定CoreDNS,架构中采用Etcd 作为两者沟通中介,一旦有资源纪录产生就储存至Etcd 中,以提供给CoreDNS作为资源纪录来确保服务辨识导向。 ExternalDNS 是 Kubernetes 社区的专案,目前被用于同步 Kubernetes 自动设定公有云 DNS 服务的资源纪录。
部署External DNS
export DNS_VIP=192.168.77.141
sed -i "s/{{DNS_VIP}}/${DNS_VIP}/g" ExtraAddons/external-dns/coredns/coredns.svc.yaml
kubectl apply -f ExtraAddons/external-dns/
kubectl apply -f ExtraAddons/external-dns/coredns/
kubectl apply -f ExtraAddons/external-dns/external-dns/
目前还不支持
nodePort方式的service,预计在0.6版本加入
验证服务
kubectl -n external-dns get po,svc
NAME READY STATUS RESTARTS AGE
pod/coredns-85867446cb-5cmct 1/1 Running 0 2m22s
pod/coredns-etcd-977864b94-hk55n 1/1 Running 0 21m
pod/external-dns-55b8797b99-fgcbz 1/1 Running 0 37m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/coredns-etcd ClusterIP 10.100.57.251 <none> 2379/TCP,2380/TCP 38m
service/coredns-tcp LoadBalancer 10.106.147.182 192.168.77.141 53:30496/TCP,9153:31490/TCP 38m
service/coredns-udp LoadBalancer 10.109.50.102 192.168.77.141 53:30548/UDP 38m
# 解析域名
dig @${DNS_VIP} SOA nginx.k8s.local +noall +answer +time=2 +tries=1
; <<>> DiG 9.9.4-RedHat-9.9.4-74.el7_6.1 <<>> @192.168.77.141 SOA nginx.k8s.local +noall +answer +time=2 +tries=1
; (1 server found)
;; global options: +cmd
k8s.local. 30 IN SOA ns.dns.k8s.local. hostmaster.k8s.local. 1561367307 7200 1800 86400 30
dig @${DNS_VIP} A nginx.k8s.local +noall +answer +time=2 +tries=1
; <<>> DiG 9.9.4-RedHat-9.9.4-74.el7_6.1 <<>> @192.168.77.141 A nginx.k8s.local +noall +answer +time=2 +tries=1
; (1 server found)
;; global options: +cmd
nginx.k8s.local. 300 IN A 192.168.77.140
将dns服务器加入到主机的/etc/resolv.conf
cat /etc/resolv.conf
nameserver 192.168.77.141
# 解析内部地址
nslookup nginx.k8s.local
Server: 192.168.77.141
Address: 192.168.77.141#53
Name: nginx.k8s.local
Address: 192.168.77.140
# 解析外部地址
nslookup baidu.com
Server: 192.168.77.141
Address: 192.168.77.141#53
Non-authoritative answer:
Name: baidu.com
Address: 220.181.38.148
Name: baidu.com
Address: 123.125.114.144
Dashboard
Dashboard是Kubernetes官方开发的基于Web的仪表板,目的是提升管理Kubernetes集群资源便利性,并以资源视觉化方式,来让人更直觉的看到整个集群资源状态。
配置证书
cd /etc/kubernetes/pki
echo '{"CN":"kubernetes-dashboard","key":{"algo":"rsa","size":2048},"names":[{"C":"CN","ST":"Shanghai","L":"Shanghai","O":"Kubernetes","OU":"Kubernetes System"}]}' > kubernetes-dashboard.json
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,localhost,kubernetes-dashboard.k8s.local \
-profile=kubernetes \
kubernetes-dashboard.json | cfssljson -bare kubernetes-dashboard
kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.crt=./kubernetes-dashboard.pem --from-file=dashboard.key=./kubernetes-dashboard-key.pem -n kube-system
# 创建ingress的tls认证
kubectl create secret tls kubernetes-dashboard-certs-tls --key ./kubernetes-dashboard-key.pem --cert ./kubernetes-dashboard.pem -n kube-system
部署dashboard
cd /opt/kubernetes-manual/v1.14.3/
kubectl apply -f ExtraAddons/dashboard/
kubectl -n kube-system get po,svc -l k8s-app=kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-5f7b999d65-8skjp 1/1 Running 0 3m38s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard ClusterIP 10.244.42.131 <none> 443/TCP 3m37s
在这边会额外建立名称为anonymous-dashboard-proxy的Cluster Role(Binding) 来让system:anonymous这个匿名使用者能够透过API Server 来proxy到Kubernetes Dashboard,而这个RBAC 规则仅能够存取services/proxy资源,以及https:kubernetes-dashboard:资源名称。
https://{{VIP}}:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
获取token登录dashboard
kubectl -n kube-system describe secrets $(kubectl describe sa kubernetes-dashboard-admin -n kube-system | awk '/Tokens/ {print $2}') | awk '/token:/{print $2}'
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbi10b2tlbi1xY3o0ZyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjI1NWU3OTNmLTlhNzItMTFlOS04YTlkLTAwMGMyOWRiZDEzOSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTprdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbiJ9.LmjbcNobNFv69FYvpZvJtRh57vWyyOPfAYCpU06zIr4G75ZbfiNWUAwCxzu7ifA24dWMGyCPx2RxbbbBL62thl9CZGv5SevUrnr_8IcXn3lBR4PVsO19uY0cYAxVpQWSl7fJzMb5hRoqsMIHSRU3bdSHqY0t909_lyso5a2eWOGg6Zeof7DJDymf7r0f9X9iz2Q3-PDQfA4J_p_ESaceNUVsvlls_PC0m4WyHE7JrRJqIsGF5iiSxP3RvxWCknPuKl9k9DT0uDKYIKzrB-0bjbMXqYGcRS9FcLzuwd4Df1wTt3r_jNbVsGVPJZ7EQGAOQWH_8bMbmeyJK6ffHKsnFQ
使用代理节点登录,选择token方式验证
https://192.168.77.140:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
使用ingress代理进行访问
绑定hosts即可使用域名访问
192.168.77.140 kubernetes-dashboard.k8s.local
Metrics Server
Metrics Server 是实现了Metrics API的元件,其目标是取代Heapster作为Pod与Node提供资源的Usage metrics,该组件会从每个Kubernetes节点上的Kubelet所公开的Summary API中收集Metrics。
在任意master节点上执行kubectl top命令
kubectl top node
Error from server (NotFound): the server could not find the requested resource (get services http:heapster:)
发现top指令无法取得Metrics,这表示Kubernetes 丛集没有安装Heapster或是Metrics Server 来提供Metrics API给top指令取得资源使用量。
部署metric-server组件
kubectl apply -f ExtraAddons/metrics-server/
kubectl -n kube-system get po -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-55599dc87f-5z8n8 1/1 Running 0 5m6s
查看聚合的api
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[]}
完成后,等待一段时间收集Metrics,再次执行kubectl top
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-m1 144m 14% 1133Mi 60%
k8s-m2 130m 13% 952Mi 50%
k8s-m3 150m 15% 805Mi 43%
k8s-n1 101m 10% 796Mi 42%
k8s-n2 92m 9% 856Mi 45%
这时如果使用hpa的话,就能够正确抓到pod的cpu和memory数据了。
Prometheus
由于Heapster将要被移弃,因此这边选用Prometheus作为第三方的集群监控方案。而本次安装采用CoreOS开发的Prometheus Operator用于管理在Kubernetes上的Prometheus集群与资源。
在k8s-m1上执行以下命令部署Prometheus组件
kubectl apply -f ExtraAddons/prometheus/
kubectl apply -f ExtraAddons/prometheus/prometheus-operator/
这边要等 operator 起来并建立好 CRDs 才能进行下步操作
``
kubectl get customresourcedefinitions | grep monitoring
alertmanagers.monitoring.coreos.com 2019-06-20T10:22:50Z
prometheuses.monitoring.coreos.com 2019-06-20T10:22:50Z
prometheusrules.monitoring.coreos.com 2019-06-20T10:22:52Z
servicemonitors.monitoring.coreos.com 2019-06-20T10:22:51Z
接着创建服务组件
kubectl apply -f ExtraAddons/prometheus/kube-state-metrics/
kubectl apply -f ExtraAddons/prometheus/node-exporter/
kubectl apply -f ExtraAddons/prometheus/alertmanager/
kubectl apply -f ExtraAddons/prometheus/prometheus/
kubectl apply -f ExtraAddons/prometheus/grafana/
kubectl apply -f ExtraAddons/prometheus/service-monitor/
可以修改alertmanager/alertmanager.cm.yml文件里的配置,以便报警通过邮件或微信发送。
创建k8s的服务组件service监控
kubectl apply -f ExtraAddons/prometheus/kube-service-discovery/
因为我们是二进制方式创建的,所以服务的endpoint需要手动指定
cat ExtraAddons/prometheus/kube-service-discovery/endpoints/kube-controller-manager.ep.yaml
apiVersion: v1
kind: Endpoints
metadata:
namespace: kube-system
name: kube-controller-manager-prometheus-discovery
labels:
k8s-app: kube-controller-manager
subsets:
- addresses:
- ip: 192.168.77.130
- ip: 192.168.77.131
- ip: 192.168.77.132
ports:
- name: http-metrics
port: 10252
protocol: TCP
cat ExtraAddons/prometheus/kube-service-discovery/endpoints/kube-scheduler.ep.yml
apiVersion: v1
kind: Endpoints
metadata:
namespace: kube-system
name: kube-scheduler-prometheus-discovery
labels:
k8s-app: kube-scheduler
subsets:
- addresses:
- ip: 192.168.77.130
- ip: 192.168.77.131
- ip: 192.168.77.132
ports:
- name: http-metrics
port: 10251
protocol: TCP
kubectl apply -f ExtraAddons/prometheus/kube-service-discovery/endpoints/
完成后,通过kubectl检查服务是否正常运行:
kubectl -n monitoring get po,svc,ing
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 1m
grafana-7f7c7947bf-pq58n 1/1 Running 0 1m
kube-state-metrics-86d9d9854-4rkm8 2/2 Running 0 1m
node-exporter-9h6hf 1/1 Running 0 1m
node-exporter-bfkrv 1/1 Running 0 1m
node-exporter-cgxkj 1/1 Running 0 1m
node-exporter-fqgpx 1/1 Running 0 1m
node-exporter-znk98 1/1 Running 0 1m
prometheus-k8s-0 3/3 Running 1 1m
prometheus-operator-f44494678-4z7pn 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.96.204.137 <none> 9093/TCP 48m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 48m
service/grafana ClusterIP 10.111.132.53 <none> 3000/TCP 47m
service/kube-state-metrics ClusterIP 10.106.232.241 <none> 8080/TCP 48m
service/node-exporter ClusterIP None <none> 9100/TCP 48m
service/prometheus ClusterIP 10.104.74.175 <none> 9090/TCP 39m
service/prometheus-operated ClusterIP None <none> 9090/TCP 39m
service/prometheus-operator ClusterIP 10.106.108.8 <none> 8080/TCP 56m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/alertmanager alertmanager.monitoring.k8s.local 192.168.77.140 80 20m
ingress.extensions/grafana grafana.monitoring.k8s.local 192.168.77.140 80 20m
ingress.extensions/prometheus prometheus.monitoring.k8s.local 192.168.77.140 80 20m
可以通过hosts绑定进行访问组件页面
192.168.77.140 prometheus.monitoring.k8s.local
192.168.77.140 alertmanager.monitoring.k8s.local
192.168.77.140 grafana.monitoring.k8s.local
prometheus
alertmanager
grafana
Weave Scope
使用Weave Scope 来监控容器的网络 Flow 拓扑图。
部署scope
kubectl apply -f ExtraAddons/WeaveScope/scope.yaml
使用ingress代理,并设置basic验证
yum -y install httpd-tools
htpasswd -bc scope.user scope scope@admin123
sed -i "s#{{auth}}#$(cat scope.user | base64)#g" ExtraAddons/WeaveScope/scope.ing.yaml
kubectl apply -f ExtraAddons/WeaveScope/scope.ing.yaml
kubectl -n weave get pod,svc,ing
NAME READY STATUS RESTARTS AGE
pod/weave-scope-agent-4gjz2 1/1 Running 0 1m
pod/weave-scope-agent-lj4fb 1/1 Running 0 1m
pod/weave-scope-agent-pf9l5 1/1 Running 0 1m
pod/weave-scope-agent-vtj82 1/1 Running 0 1m
pod/weave-scope-agent-xw6cm 1/1 Running 0 1m
pod/weave-scope-app-6689cb649c-lvxz9 1/1 Running 0 1m
pod/weave-scope-cluster-agent-b8564dd7b-bcqb5 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/weave-scope-app ClusterIP 10.102.129.130 <none> 80/TCP 1m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/scope scope.weave.k8s.local 192.168.77.140 80 95s
本地绑定hosts进行访问,输入用户和密码进行认证
192.168.77.140 scope.weave.k8s.local
Helm Tiller Server
Helm 是Kubernetes Chart的管理工具,Kubernetes Chart是一套预先组态的Kubernetes资源套件。其中Tiller Server主要负责接收来至Client的指令,并通过kube-apiserver与Kubernetes集群做沟通,根据Chart定义的内容,来产生与管理各种对应API物件的Kubernetes部署文件(又称为Release)。
所有节点安装socat
for NODE in k8s-m1 k8s-m2 k8s-m3 k8s-n1 k8s-n2; do
echo "--- $NODE ---"
ssh ${NODE} "yum install -y socat"
done
部署helm
cd /opt/v1.14.3/
cp bin/helm /usr/local/bin/
初始化
kubectl -n kube-system create sa tiller
kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
helm init --service-account tiller --stable-repo-url http://mirror.azure.cn/kubernetes/charts
kubectl -n kube-system get po,deploy,svc -l app=helm
NAME READY STATUS RESTARTS AGE
pod/tiller-deploy-9bf6fb76d-dd2x8 1/1 Running 0 52s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/tiller-deploy 1/1 1 1 52s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/tiller-deploy ClusterIP 10.105.39.226 <none> 44134/TCP 52s
helm version
Client: &version.Version{SemVer:"v2.14.1", GitCommit:"5270352a09c7e8b6e8c9593002a73535276507c0", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.14.1", GitCommit:"5270352a09c7e8b6e8c9593002a73535276507c0", GitTreeState:"clean"}
测试helm
# 安装grafana
helm install --name my-release stable/grafana --set image.tag=6.2.4,service.type=NodePort
kubectl get po,svc -l release=my-release
NAME READY STATUS RESTARTS AGE
pod/my-release-grafana-687784cd9f-dh7lh 1/1 Running 0 14s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-release-grafana NodePort 10.106.173.248 <none> 80:31790/TCP 15s
# 获取admin密码
kubectl get secret --namespace default my-release-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
SR8swZlvJ0LOVBrhvxRu9ErAfgVIAWEc9CMAHeYt
使用http://node_ip:31790链接访问grafana
测试完成后,使用以下命令删除release
helm ls
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
my-release 1 Mon Jun 24 18:34:48 2019 DEPLOYED grafana-3.5.4 6.2.4 default
# 删除
helm del --purge my-release
# 删除helm
helm reset --remove-helm-home
更多Helm Apps可以到Kubeapps Hub寻找。
测试高可用
将k8s-m3关机
ssh k8s-m3 poweroff
# 过一会
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-m1 Ready master 1h v1.14.3
k8s-m2 Ready master 1h v1.14.3
k8s-m3 NotReady master 1h v1.14.3
k8s-n1 Ready worker 1h v1.14.3
k8s-n2 Ready worker 1h v1.14.3
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-2 Unhealthy Get https://192.168.77.132:2379/health: dial tcp 192.168.77.132:2379: connect: no route to host
测试建立pod
kubectl run nginx --image nginx:1.17.0-alpine --restart=Never --port 80 --labels="app=nginx-test"
kubectl get po -l app=nginx-test
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 35s
测试完成之后,重启集群所有节点。
累了吧,试试一键部署Ansible 应用 之 【使用ansible来做kubernetes 1.14.3集群高可用的一键部署 】