NodeLocal DNSCache 通过在群集节点上作为DaemonSet运行dns缓存代理来提高群集DNS性能。 在当今的体系结构中,处于ClusterFirst DNS模式的Pod可以连接到kube-dns serviceIP进行DNS查询。 通过kube-proxy添加的iptables规则将其转换为kube-dns / CoreDNS端点。 借助这种新架构,Pods将可以访问在同一节点上运行的dns缓存代理,从而避免了iptables DNAT规则和连接跟踪。 本地缓存代理将查询 kube-dns 服务以获取集群主机名的缓存缺失(默认为 cluster.local 后缀)。
优势
- 使用当前的 DNS 体系结构,如果本地没有kube-dns/CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须延伸到另一个节点。 在这种场景下,拥有本地缓存将有助于改善延迟。
- 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表。
- 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP 。 TCP conntrack 条目将在连接关闭时被删除,相反 UDP 条目必须超时(默认
nf_conntrack_udp_timeout是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)。
- 在节点级别对 dns 请求的度量和可见性。
- 可以重新启用缓存,从而减少对 kube-dns 服务的查询数量。
缺陷
- NodeLocal DNS Cache 没有高可用性(High Availability,HA),会存在单点 nodelocal dns cache 故障(Pod Evicted/ OOMKilled/ConfigMap error/DaemonSet Upgrade)
架构图
启用 NodeLocal DNSCache 之前,Kubernetes中的Pod将请求发送到 kube-dns 服务。在 pod 内部,这是通过将pod的 /etc/resolv.conf nameserver 字段设置为kube-dns服务IP(默认情况下是10.96.0.10)来完成的。 kube-proxy 管理这些服务IP,并通过 iptables 或 IPVS 技术将它们转换为 kube-dns 端点。
启用 NodeLocal DNSCache 之后,这是 DNS 查询所遵循的路径:

通过 DaemonSet 在集群的每个节点上部署一个 hostNetwork 的 Pod,该 Pod 是 node-cache,可以缓存本节点上 Pod 的 DNS 请求。如果存在 cache misses ,该 Pod 将会通过 TCP 请求上游 kube-dns 服务进行获取。如果 cache hit,则会直接返回个客户端。
前提条件
k8s 集群已经建立。
# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master-node1 Ready master 3d17h v1.19.3
k8s-master-node2 Ready master 3d17h v1.19.3
k8s-master-node3 Ready master 3d17h v1.19.3
k8s-worker-node1 Ready worker 3d17h v1.19.3
k8s-worker-node2 Ready worker 3d17h v1.19.3
如果没建立的,可以通过下列方式一键部署高可用集群。
bash -c "$(curl -sSL https://cdn.jsdelivr.net/gh/lework/kainstall/kainstall.sh)" \ - init \ --master 192.168.77.130,192.168.77.131,192.168.77.132 \ --worker 192.168.77.133,192.168.77.134 \ --user root \ --password 123456 \ --port 22 \ --version 1.19.3
部署 NodeLocal DNSCache
下载资源清单文件
wget https://cdn.jsdelivr.net/gh/kubernetes/kubernetes@master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
该资源清单文件中包含几个变量,其中:
__PILLAR__DNS__SERVER__:表示kube-dns这个 Service 的 ClusterIP,可以通过命令kubectl get svc -n kube-system -l k8s-app=kube-dns -o jsonpath='{$.items[*].spec.clusterIP}'获取__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为169.254.20.10__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local__PILLAR__CLUSTER__DNS__: 表示集群内查询的上游服务器__PILLAR__UPSTREAM__SERVERS__: 表示为外部查询的上游服务器
如果kube-proxy在 iptables 模式下运行, 则运行以下命令创建
sed 's/k8s.gcr.io/k8sgcr.lework.workers.dev/g
s/__PILLAR__DNS__SERVER__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml | kubectl apply -f -
k8sgcr.lework.workers.dev是代理地址
__PILLAR__CLUSTER__DNS__和__PILLAR__UPSTREAM__SERVERS__由node-cache应用配置。
如果kube-proxy在 ipvs 模式下运行, 则运行以下命令创建
sed 's/k8s.gcr.io/k8sgcr.lework.workers.dev/g
s/__PILLAR__CLUSTER__DNS__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/[ |,]__PILLAR__DNS__SERVER__//g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml | kubectl apply -f -
k8sgcr.lework.workers.dev是代理地址
__PILLAR__UPSTREAM__SERVERS__由node-cache应用配置。
创建完成后,就能看到每个节点上都运行了一个pod
# kubectl -n kube-system get pods -l k8s-app=node-local-dns -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-local-dns-9bzx9 1/1 Running 0 116m 192.168.77.132 k8s-master-node3 <none> <none>
node-local-dns-9w7mk 1/1 Running 0 116m 192.168.77.133 k8s-worker-node1 <none> <none>
node-local-dns-ljvtt 1/1 Running 0 116m 192.168.77.131 k8s-master-node2 <none> <none>
node-local-dns-vsg6q 1/1 Running 0 116m 192.168.77.130 k8s-master-node1 <none> <none>
node-local-dns-wbw84 1/1 Running 0 116m 192.168.77.134 k8s-worker-node2 <none> <none>
需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了
hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。
查看其中一个节点pod的日志
# kubectl -n kube-system logs node-local-dns-9bzx9
2020/11/10 01:59:23 [INFO] Starting node-cache image: 1.15.16
2020/11/10 01:59:23 [INFO] Using Corefile /etc/Corefile
2020/11/10 01:59:23 [INFO] Updated Corefile with 0 custom stubdomains and upstream servers /etc/resolv.conf
2020/11/10 01:59:23 [INFO] Using config file:
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . /etc/resolv.conf
prometheus :9253
}
2020/11/10 01:59:23 [INFO] Updated Corefile with 0 custom stubdomains and upstream servers /etc/resolv.conf
2020/11/10 01:59:23 [INFO] Using config file:
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . /etc/resolv.conf
prometheus :9253
}
cluster.local.:53 on 169.254.20.10
in-addr.arpa.:53 on 169.254.20.10
ip6.arpa.:53 on 169.254.20.10
.:53 on 169.254.20.10
[INFO] plugin/reload: Running configuration MD5 = e43ea5ef65cd4ee85f56a7f18086f3dd
CoreDNS-1.6.7
linux/amd64, go1.11.13,
2020/11/10 01:59:23 [INFO] Added interface - nodelocaldns
[INFO] Added back nodelocaldns rule - {raw PREROUTING [-p tcp -d 169.254.20.10 --dport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {raw PREROUTING [-p udp -d 169.254.20.10 --dport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {filter INPUT [-p udp -d 169.254.20.10 --dport 53 -j ACCEPT]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p tcp -s 169.254.20.10 --sport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p udp -s 169.254.20.10 --sport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {filter OUTPUT [-p tcp -s 169.254.20.10 --sport 53 -j ACCEPT]}
[INFO] Added back nodelocaldns rule - {filter OUTPUT [-p udp -s 169.254.20.10 --sport 53 -j ACCEPT]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p tcp -d 169.254.20.10 --dport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p udp -d 169.254.20.10 --dport 53 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p tcp -d 169.254.20.10 --dport 8080 -j NOTRACK]}
[INFO] Added back nodelocaldns rule - {raw OUTPUT [-p tcp -s 169.254.20.10 --sport 8080 -j NOTRACK]}
可以看到其使用的配置,和iptables 规则。
在节点上,我们可以看到node-cache创建的接口
# ip link show nodelocaldns
11: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default
link/ether 9e:7c:86:1b:18:92 brd ff:ff:ff:ff:ff:ff
# ip addr show nodelocaldns
11: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 9e:7c:86:1b:18:92 brd ff:ff:ff:ff:ff:ff
inet 169.254.20.10/32 brd 169.254.20.10 scope global nodelocaldns
valid_lft forever preferred_lft forever
# ifconfig nodelocaldns
nodelocaldns: flags=130<BROADCAST,NOARP> mtu 1500
inet 169.254.20.10 netmask 255.255.255.255 broadcast 169.254.20.10
ether 9e:7c:86:1b:18:92 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
在节点上,通过iptables-save命令可以看到10.96.0.10/ 169.254.20.10IP相关的规则
# iptables-save
*raw
-A PREROUTING -d 169.254.20.10/32 -p udp -m udp --dport 53 -j NOTRACK
-A PREROUTING -d 169.254.20.10/32 -p tcp -m tcp --dport 53 -j NOTRACK
-A OUTPUT -s 169.254.20.10/32 -p tcp -m tcp --sport 8080 -j NOTRACK
-A OUTPUT -d 169.254.20.10/32 -p tcp -m tcp --dport 8080 -j NOTRACK
-A OUTPUT -d 169.254.20.10/32 -p udp -m udp --dport 53 -j NOTRACK
-A OUTPUT -d 169.254.20.10/32 -p tcp -m tcp --dport 53 -j NOTRACK
-A OUTPUT -s 169.254.20.10/32 -p udp -m udp --sport 53 -j NOTRACK
-A OUTPUT -s 169.254.20.10/32 -p tcp -m tcp --sport 53 -j NOTRACK
*filter
-A INPUT -d 169.254.20.10/32 -p udp -m udp --dport 53 -j ACCEPT
-A INPUT -d 169.254.20.10/32 -p tcp -m tcp --dport 53 -j ACCEPT
-A OUTPUT -s 169.254.20.10/32 -p udp -m udp --sport 53 -j ACCEPT
-A OUTPUT -s 169.254.20.10/32 -p tcp -m tcp --sport 53 -j ACCEPT
节点本地DNS会在所有 kube-proxy 规则之前添加这些规则,以便首先对其进行评估。-j NOTRACK 使发送到本地或 kube-dns IP地址的TCP和UDP数据包被conntrack取消跟踪。这就是节点本地DNS缓存避免conntrack错误并接管数据包以发送到 kube-dns IP的方式。
我们如何将DNS流量发送到 kube-dns ? 我们无法使用它的IP,因为流量会因网络更改而流向Node Local DNS pod本身。 。node-local-dns解决此问题的方法是为现有的 kube-dns 部署添加新服务。服务的配置如下:
# kubectl -n kube-system describe svc kube-dns-upstream
Name: kube-dns-upstream
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
k8s-app=kube-dns
kubernetes.io/cluster-service=true
kubernetes.io/name=KubeDNSUpstream
Annotations: <none>
Selector: k8s-app=kube-dns
Type: ClusterIP
IP: 10.96.134.149
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.244.2.2:53,10.244.3.9:53
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.244.2.2:53,10.244.3.9:53
Session Affinity: None
Events: <none>
此服务将创建一个新的Cluster IP,该Cluster IP,可用于联系kube-dns pod并跳过节点本地DNS iptables规则。 __PILLAR__CLUSTER__DNS是一个特殊的模板变量,Node Local DNS将使用该模板变量进行模板化。 这是通过解析KUBE_DNS_UPSTREAM_SERVICE_HOST环境变量来完成的,如果启用enableServiceLinks(默认为启用),则在pod启动时会生成该环境变量。 请记住,如果重新创建服务,则必须重新启动节点 node-local-dns。
# kubectl -n kube-system exec node-local-dns-9bzx9 -- env | grep KUBE_DNS_UPSTREAM_SERVICE_HOST
KUBE_DNS_UPSTREAM_SERVICE_HOST=10.96.134.149
在CoreDNS配置中,我们还具有 .:53区域,该区域用于处理非Kubernetes内运行的服务的解析请求的情况。 我们缓存请求并转发到__PILLAR__UPSTREAM__SERVERS上游DNS服务器。 节点本地DNS从kube-dns configmap查找__PILLAR__UPSTREAM__SERVERS值。 本次部署没有设置,因此默认为/etc/resolv.conf。 请注意,节点本地DNS使用dnsPolicy:Default,这使/etc/resolv.conf与节点上的相同。
使用
使用node-local-dns的解析有两种设置:配置Pod 的 dnsconfig ;配置 kubelet的 cluster-dns。
配置Pod 的 dnsconfig
使用此方法,仅针对某个pod设置,不影响其他组件。
apiVersion: v1
kind: Pod
spec:
dnsPolicy: None
dnsConfig:
nameservers:
- 169.254.20.10
searches:
- default.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "2"
配置 kubelet 的 cluster-dns
使用此方法,生效的对象则是kubelet所管理的所有pod,需要重启 kubelet 。
# sed -i 's/10.96.0.10/169.254.20.10/g' /var/lib/kubelet/config.yaml
# systemctl restart kubelet
验证
我们此次使用 配置Pod 的 dnsconfig 的方式来测试
-
创建测试pod
# cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: test-node-local-dns spec: containers: - name: local-dns image: busybox:glibc command: ["/bin/sh", "-c", "sleep 60m"] dnsPolicy: "None" dnsConfig: nameservers: - 169.254.20.10 searches: - default.svc.cluster.local - svc.cluster.local - cluster.local options: - name: ndots value: "2" EOF注意: busybox 的 新版本 uclibc 中的nslookup 有问题,请使用 glibc 。
-
待 pod 启动后,查看
/etc/resolv.conf# kubectl exec test-node-local-dns -- cat /etc/resolv.conf nameserver 169.254.20.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:2 -
在 pod 的节点上,监听 53 端口
我这里是
k8s-worker-node2节点,可以通过kubectl get pods test-node-local-dns -o jsonpath='{$.spec.nodeName}'获取# yum install tcpdump -y # tcpdump -i any src host 169.254.20.10 and port 53 -vv tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes -
在 pod 中查询 外部域名 A 记录
# kubectl exec test-node-local-dns -- nslookup www.baidu.com Server: 169.254.20.10 Address: 169.254.20.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11正常返回,没有问题。
-
在 pod 的节点上,观察 tcpdump 接收到的信息
k8s-worker-node2.domain > 10.244.4.24.38514: [bad udp cksum 0xcd77 -> 0x112f!] 41730 q: AAAA? www.baidu.com. 1/0/0 www.baidu.com. CNAME www.a.shifen.com. (74) 11:18:03.164521 IP (tos 0x0, ttl 64, id 33106, offset 0, flags [DF], proto UDP (17), length 102) k8s-worker-node2.domain > 10.244.4.24.38514: [bad udp cksum 0xcd77 -> 0x112f!] 41730 q: AAAA? www.baidu.com. 1/0/0 www.baidu.com. CNAME www.a.shifen.com. (74) 11:18:03.164646 IP (tos 0x0, ttl 64, id 33107, offset 0, flags [DF], proto UDP (17), length 166) k8s-worker-node2.domain > 10.244.4.24.38514: [bad udp cksum 0xcdb7 -> 0x60ed!] 33472 q: A? www.baidu.com. 3/0/0 www.baidu.com. CNAME www.a.shifen.com., www.a.shifen.com. A 180.101.49.12, www.a.shifen.com. A 180.101.49.11 (138) 11:18:03.164649 IP (tos 0x0, ttl 64, id 33107, offset 0, flags [DF], proto UDP (17), length 166) k8s-worker-node2.domain > 10.244.4.24.38514: [bad udp cksum 0xcdb7 -> 0x60ed!] 33472 q: A? www.baidu.com. 3/0/0 www.baidu.com. CNAME www.a.shifen.com., www.a.shifen.com. A 180.101.49.12, www.a.shifen.com. A 180.101.49.11 (138)到这里就说明NodeLocal DNSCache 组件部署成功了,但是域名解析我们还是要多测试测试。
-
测试 service 域名解析
# kubectl exec test-node-local-dns -- nslookup -type=a kubernetes Server: 169.254.20.10 Address: 169.254.20.10:53 ** server can't find kubernetes.cluster.local: NXDOMAIN ** server can't find kubernetes.svc.cluster.local: NXDOMAIN Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1 command terminated with exit code 1因为使用了相对域名,使用搜索域,进行了所有域的查询操作。
# fqdn # kubectl exec test-node-local-dns -- nslookup -type=a kubernetes. Server: 169.254.20.10 Address: 169.254.20.10:53 ** server can't find kubernetes.: SERVFAIL command terminated with exit code 1 # dot 2 [root@k8s-master-node1 ~]# kubectl exec test-node-local-dns -- nslookup -type=a kubernetes.default Server: 169.254.20.10 Address: 169.254.20.10:53 ** server can't find kubernetes.default: NXDOMAIN command terminated with exit code 1 # domain [root@k8s-master-node1 ~]# kubectl exec test-node-local-dns -- nslookup -type=a kubernetes.default.svc.cluster.local Server: 169.254.20.10 Address: 169.254.20.10:53 Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1- 使用fqdn时,只会查询一次。
- 域名中的
.数目等于或大于设置的值时,也会只查询一次。
-
ExternalName Service 解析
ExternalName Service 是 Service 的一个特例,没有选择器,可以用于给外部服务取一个内部别名。
创建 ExternalName Service
# cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Service metadata: name: baidu namespace: default spec: type: ExternalName externalName: www.baidu.com EOF # kubectl describe svc baidu Name: baidu Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ExternalName IP: External Name: www.baidu.com Session Affinity: None Events: <none>测试解析内部服务
# kubectl exec test-node-local-dns -- nslookup baidu Server: 169.254.20.10 Address: 169.254.20.10:53 ** server can't find baidu.cluster.local: NXDOMAIN baidu.default.svc.cluster.local canonical name = www.baidu.com www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11 baidu.default.svc.cluster.local canonical name = www.baidu.com www.baidu.com canonical name = www.a.shifen.com ** server can't find baidu.svc.cluster.local: NXDOMAIN ** server can't find baidu.svc.cluster.local: NXDOMAIN ** server can't find baidu.cluster.local: NXDOMAIN command terminated with exit code 1baidu.default.svc.cluster.local 将会被映射到 www.baidu.com , 这是通过 DNS 的 CNAME 记录实现的。
压测
使用 dnsperf 项目进行 dns 查询压力测试
-
创建pod
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: perf-node-dns spec: containers: - name: perf-node-dns image: guessi/dnsperf:alpine command: ["/bin/sh", "-c", "sleep 60m"] dnsPolicy: "None" EOF -
测试coredns的性能
coredns 在集群中默认是2个节点
# kubectl exec -ti perf-node-local-dns -- sh cat <<EOF >records.txt baidu.com A www.baidu.com A mail.baidu.com A github.com A www.yahoo.com A www.microsoft.com A www.aliyun.com A developer.aliyun.com A kubernetes.io A kubernetes A kubernetes.default.svc.cluster.local A kube-dns.kube-system.svc.cluster.local A EOF / # dnsperf -l 60 -s 10.96.0.10 -Q 100000 -d records.txt DNS Performance Testing Tool Version 2.2.1 [Status] Command line: dnsperf -l 60 -s 10.96.0.10 -Q 100000 -d records.txt [Status] Sending queries (to 10.96.0.10) [Status] Started at: Tue Nov 10 05:00:35 2020 [Status] Stopping after 60.000000 seconds [Status] Testing complete (time limit) Statistics: Queries sent: 835613 Queries completed: 835613 (100.00%) Queries lost: 0 (0.00%) Response codes: NOERROR 765979 (91.67%), SERVFAIL 69634 (8.33%) Average packet size: request 35, response 163 Run time (s): 60.005840 Queries per second: 13925.527915 Average Latency (s): 0.005713 (min 0.000170, max 0.067250) Latency StdDev (s): 0.003657dnsperf 参数
-l 60: 测试 60s-s 10.96.0.10: dns 服务器-Q 100000: 最高qps-d records.txt: 查询的列表
在 Statistics 区域中,我们可以看到发送查询835613,查询完成度100%,qps 为 13925.527915。 返回码有SERVFAIL 是因为 kubernetes 域名查询的错误。
-
测试使用NodeLocal DNSCache
/ # dnsperf -l 60 -s 169.254.20.10 -Q 100000 -d records.txt DNS Performance Testing Tool Version 2.2.1 [Status] Command line: dnsperf -l 60 -s 169.254.20.10 -Q 100000 -d records.txt [Status] Sending queries (to 169.254.20.10) [Status] Started at: Tue Nov 10 05:08:16 2020 [Status] Stopping after 60.000000 seconds [Status] Testing complete (time limit) Statistics: Queries sent: 1515112 Queries completed: 1515112 (100.00%) Queries lost: 0 (0.00%) Response codes: NOERROR 1388853 (91.67%), SERVFAIL 126259 (8.33%) Average packet size: request 35, response 163 Run time (s): 60.010329 Queries per second: 25247.520306 Average Latency (s): 0.003299 (min 0.000035, max 0.052578) Latency StdDev (s): 0.002136在 Statistics 区域中,我们可以看到发送查询1515112,查询完成度100%,qps 为 25247.520306。 其性能比使用coredns提升了
55%左右。
高可用
NodeLocal DNS Cache 并没有高可用性的特征,但是我们通过设置DaemonSet的属性,可以提高本地 dns缓存服务的稳定性。
在常规的pod终止过程中,pod会删除dummy interface & iptables规则。这样就会将流量从自身切换到集群中运行的常规 kube-dns pod上。但是如果我们强行杀死 pod,将不会去除 iptable 规则,这样就会破坏该节点的所有DNS流量,因为nodelocaldns接口上没有任何应用在监听。
为了避免这个不必要的麻烦,默认的 DaemonSet 没有设置内存/CPU限制。我建议你保持这种方式,以避免内存终止或任何CPU节流。另外pods被标记为 system-node-critical 优先级,这使得nodelocaldns几乎可以保证在节点资源耗尽的情况下,首先被调度,不太可能被驱逐。
如果你想安全起见,我建议你把DaemonSet更新策略改为OnDelete,并通过排空Kubernetes节点来进行维护/升级,排空成功后逐一删除Node Local DNS pods。
在pod中,增加一个备用nameserver,也就是我们的 kube-dns的 cluster ip,从而在 node-local-dns 不可用的情况下,能使用集群中的dns服务解析域名,保障服务不中断业务。
故障演练
模拟 node-local-dns pod 意外宕机
-
进入测试pod容器中
# kubectl exec -ti test-node-local-dns -- sh / # cat /etc/resolv.conf nameserver 169.254.20.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:2 / # -
定时查询解析
/ # while true; do date; nslookup -type=a www.baidu.com; sleep 0.5; done -
在测试pod节点上kill掉
node-local-dnspod# docker kill $(docker ps | grep node-cache_node-local-dns | awk '{print $1}') 939d90728c43 -
在测试pod容器中,查看解析情况
Wed Nov 11 03:43:55 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.11 Name: www.a.shifen.com Address: 180.101.49.12 ...... Wed Nov 11 03:43:58 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.11 Name: www.a.shifen.com Address: 180.101.49.12 Wed Nov 11 03:43:59 UTC 2020 nslookup: read: Connection refused nslookup: read: Connection refused ;; connection timed out; no servers could be reached ...... Wed Nov 11 03:46:39 UTC 2020 nslookup: read: Connection refused nslookup: read: Connection refused ;; connection timed out; no servers could be reached Wed Nov 11 03:46:44 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.11 Name: www.a.shifen.com Address: 180.101.49.12 Wed Nov 11 03:46:45 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.11 Name: www.a.shifen.com Address: 180.101.49.12解析日志做了缩减处理。
从上列日志中可以看到,在
Wed Nov 11 03:43:59 UTC 2020到Wed Nov 11 03:46:44 UTC 2020时间内,解析域名是不成功的,也就意味着近4分钟内应用是无法连接外网的。node-local-dns pod 在此时间内完成了重建,后续解析才能够成功。对于这种情况,我们可以增加一个备用
nameserver,也就是我们的kube-dns的 cluster,从而在 node-local-dns 不可用的情况下,能使用集群中的dns服务。 -
添加备用 nameserver
/ # cat /etc/resolv.conf nameserver 169.254.20.10 nameserver 10.96.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:2 options timeout:2 -
定时查询解析
/ # while true; do date; nslookup -type=a www.baidu.com; sleep 0.5; done -
在测试pod节点上kill掉
node-local-dnspod# docker kill $(docker ps | grep node-cache_node-local-dns | awk '{print $1}') eaf8e75858e0 -
在测试pod容器中,查看解析情况
Wed Nov 11 04:36:58 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11 ...... Wed Nov 11 04:36:59 UTC 2020 nslookup: read: Connection refused nslookup: read: Connection refused Server: 10.96.0.10 Address: 10.96.0.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11 ...... Wed Nov 11 04:37:10 UTC 2020 nslookup: read: Connection refused nslookup: read: Connection refused Server: 10.96.0.10 Address: 10.96.0.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11 Wed Nov 11 04:37:16 UTC 2020 Server: 169.254.20.10 Address: 169.254.20.10:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 180.101.49.12 Name: www.a.shifen.com Address: 180.101.49.11解析日志做了缩减处理。
从上列日志中可以看到,在
Wed Nov 11 04:36:59 UTC 2020到Wed Nov 11 04:37:16 UTC 2020时间内,169.254.20.10本地dns 解析域名是不成功的,经过重试10.96.0.10集群dns获得了域名A记录。这样就能保障在本地dns出现故障时,可以使用集群dns接替解析任务,从而使业务不中断。
监控
本次使用 kube-prometheus 来监控,如果你没安装的话,可以使用下列命令进行安装
bash -c "$(curl -sSL https://cdn.jsdelivr.net/gh/lework/kainstall/kainstall.sh)" \
- add --monitor prometheus
[2020-11-10T13:28:20.809542864+0800]: INFO: [start] bash - add --monitor prometheus
[2020-11-10T13:28:20.817660909+0800]: INFO: [check] ssh command exists.
[2020-11-10T13:28:20.820457137+0800]: INFO: [check] sshpass command exists.
[2020-11-10T13:28:20.823335934+0800]: INFO: [check] wget command exists.
[2020-11-10T13:28:20.825988915+0800]: INFO: [check] os support: centos7 centos8
[2020-11-10T13:28:21.021220740+0800]: INFO: [check] conn apiserver succeeded.
[2020-11-10T13:28:21.023791207+0800]: INFO: [monitor] add prometheus
[2020-11-10T13:28:21.039557403+0800]: INFO: [download] prometheus.zip
prometheus[2020-11-10T13:28:25.725607835+0800]: INFO: [download] prometheus.zip succeeded.
[2020-11-10T13:28:25.727947512+0800]: INFO: [monitor] apply prometheus manifests
[2020-11-10T13:28:56.504609026+0800]: INFO: [apply] add prometheus succeeded.
[2020-11-10T13:28:56.509174225+0800]: INFO: [apply] controller-manager and scheduler prometheus discovery service
[2020-11-10T13:28:57.181076540+0800]: INFO: [apply] add controller-manager and scheduler prometheus discovery service succeeded.
[2020-11-10T13:28:57.185952295+0800]: INFO: [monitor] add prometheus ingress
[2020-11-10T13:28:57.190479235+0800]: INFO: [apply] prometheus ingress
[2020-11-10T13:30:07.853591378+0800]: INFO: [apply] add prometheus ingress succeeded.
[2020-11-10T13:30:08.193170222+0800]: INFO: [command] get node_ip value succeeded.
[2020-11-10T13:30:08.429265384+0800]: INFO: [command] get node_port value succeeded.
ACCESS Summary:
[ingress] curl -H 'Host:grafana.monitoring.cluster.local' http://192.168.77.133:47453; auth: admin/admin
[ingress] curl -H 'Host:prometheus.monitoring.cluster.local' http://192.168.77.133:47453
[ingress] curl -H 'Host:alertmanager.monitoring.cluster.local' http://192.168.77.133:47453
See detailed log >>> /tmp/kainstall.qa1wOUDWUm/kainstall.log
创建 node-local-dns 的 prometheus 监控资源
kubectl apply -f https://cdn.jsdelivr.net/gh/lework/prometheus-config@master/node-local-dns/node-local-dns.ServiceMonitor.yaml
稍后,就能在 prometheus 中看到捕捉到的node-local-dns实例
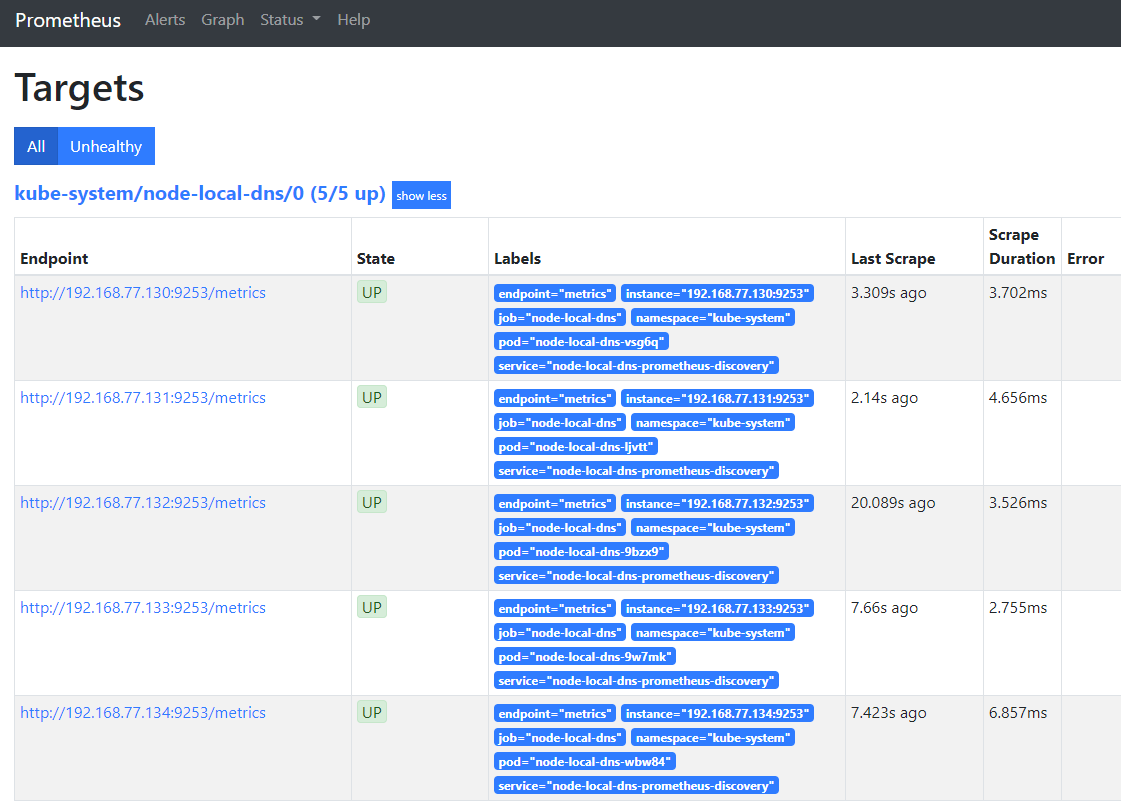
创建报警规则
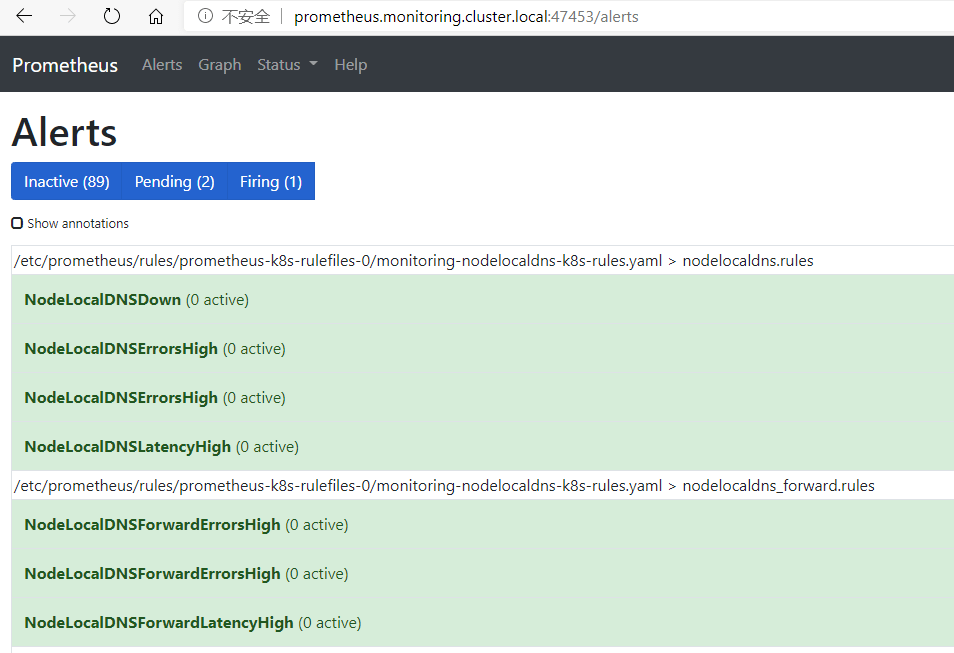
kubectl apply -f https://cdn.jsdelivr.net/gh/lework/prometheus-config@master/node-local-dns/node-local-dns.PrometheusRule.yaml
稍后,可以在 Alerts 页面中看到我们创建的规则
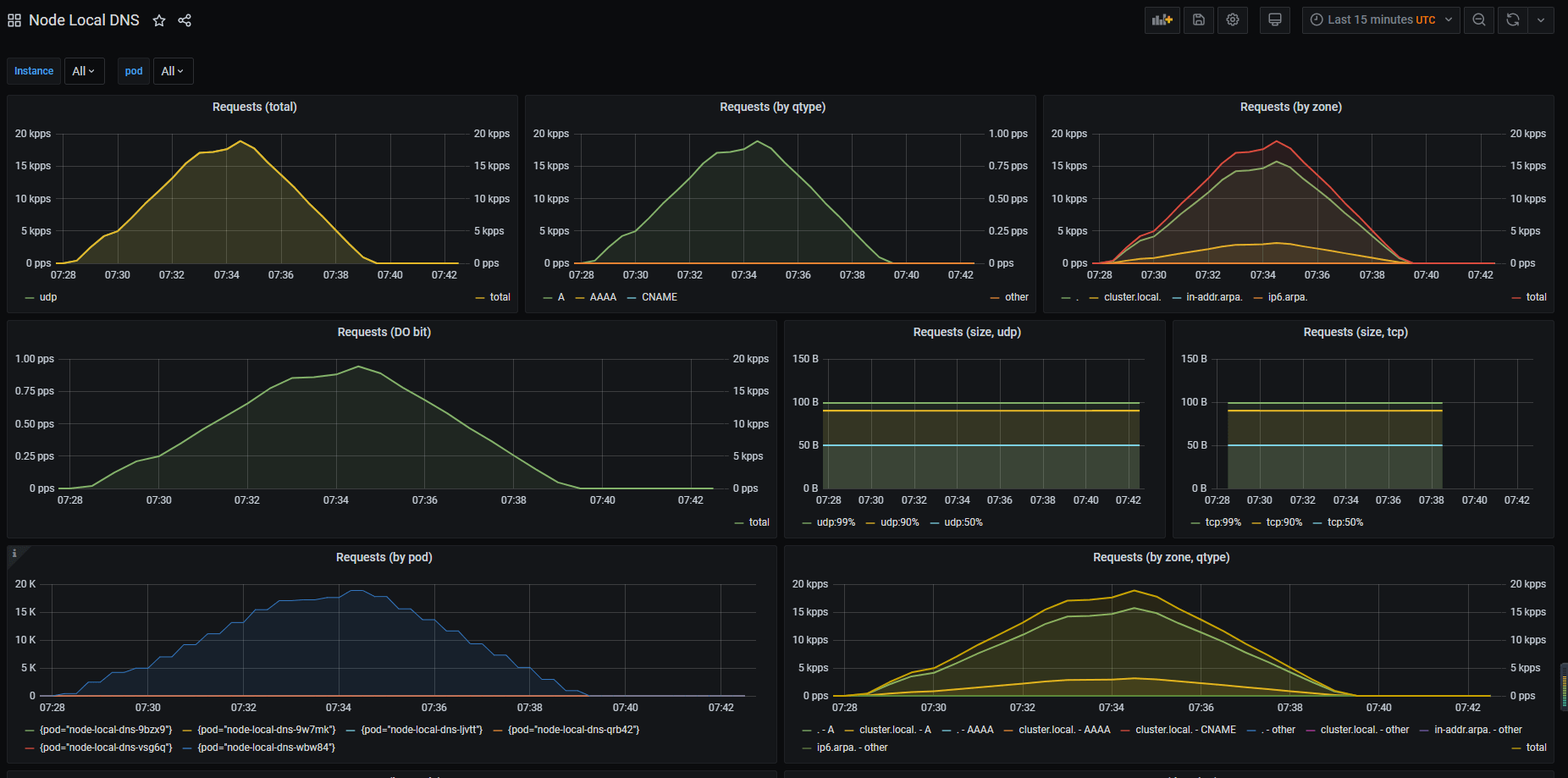
最后,我们在 grafana 导入监控面板
模板文件下载地址 https://cdn.jsdelivr.net/gh/lework/prometheus-config@master/node-local-dns/node-local-dns.grafana.json
导入后,就可以在grafana中看到node-local-dns的监控数据了
参考
- https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/
- https://www.qikqiak.com/post/use-nodelocal-dns-cache/
- https://cloud.tencent.com/document/product/457/40613